As a follow-on discussion to my SQL Server Magazine Q&A titled “Determining the position of search arguments in a join” where I was responding to a reader question about whether or not search arguments could be moved up into the FROM clause instead of placed in the WHERE clause and whether or not it would improve performance. While I was so focused on creating a scenario to highlight the problems when doing this, I missed a great point about what happened in my specific example. Fellow SQL Server MVP, Phil Brammer (blog | twitter) brought up this point first and it sparked a very passionate discussion on the SQL Server MVP forum. As a result, I thought I’d take a few minutes to create a few more examples and state a few key points. The most important of which is that search arguments should not be moved from the WHERE clause into the FROM clause unless you really know what you’re doing – you may completely change the meaning of the query… Let me explain.
Details:
In the prior Q&A, Listing 1 and Listing 2 show INNER JOINs that describe the Customers along with some of their Sales information (specifically: OrderDate, AccountNumber, FirstName, LastName, and StateProvinceCode). In the joins, we asked for only Customers with a RegionCode of US. Regardless of having the search argument in the WHERE clause or the FROM clause, SQL Server executes the same plan, has the same performance and returns the same data. While people often state that a WHERE clause applies to the entire set (and also imply order), that’s NOT the case in terms of how the join is processed. SQL Server knows that the search argument applies to the entire set but it can certainly apply the filter prior to the join if it’s selective enough and would help improve performance. Moving the search argument up into the FROM clause is not a “tip” for improving performance. However, if all of the joins are inner joins, then it really doesn’t matter. You can certainly move the search arguments up; they won’t change the result set and it’s very unlikely that they’ll change the query plan. Listing 1 and Listing 2 were both executed at the same time to produce these two plans:

First, notice that they are 50% each. Also, without worrying about the plan itself, notice that each plan has the same pattern, the same percentages, and the same join types. These are in fact, the same plan – Listing 1 has the search argument in the WHERE clause and Listing 2 has the search argument in the FROM clause.
To illustrate how moving a search argument could affect results, I created OUTER joins, added a somewhat random search argument and then did the same thing – Listing 3 was written as an outer join and Listing 4 was a copy of that query with the search argument moved up into the FROM clause. While my examples (solely looking at the results between Listing 3 and Listing 4) prove the point that a search argument cannot be moved from the WHERE clause into the FROM clause without understanding the effects, my example also introduced another phenomena. It was this phenomena that sparked debate. When a search argument exists on an inner table of an outer join, the purpose of the outer join is effectively lost. In fact, the query is not likely to even work the way you expect. To illustrate this, I’ve created a [quick] Venn diagram of what’s logically happening:
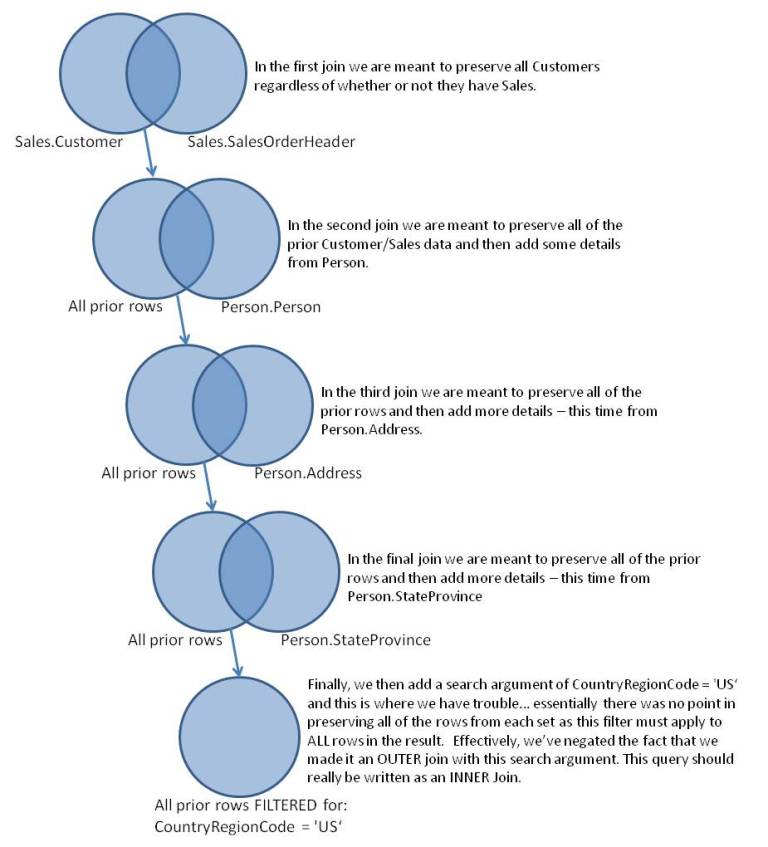
In fact, the two following queries will produce identical results:
— The original Listing 3 query
SELECT so.OrderDate, c.AccountNumber, p.FirstName
, p.LastName, sp.StateProvinceCode
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
LEFT OUTER JOIN Person.Person AS p
ON c.PersonID = p.BusinessEntityID
LEFT OUTER JOIN Person.Address AS pa
ON so.ShipToAddressID = pa.AddressID
LEFT OUTER JOIN Person.StateProvince AS sp
ON sp.StateProvinceID = pa.StateProvinceID
WHERE sp.CountryRegionCode = ‘US’
ORDER BY sp.StateProvinceCode, so.OrderDate— Listing 3 is really an inner join
SELECT so.OrderDate, c.AccountNumber, p.FirstName
, p.LastName, sp.StateProvinceCode
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
INNER JOIN Person.Person AS p
ON c.PersonID = p.BusinessEntityID
INNER JOIN Person.Address AS pa
ON so.ShipToAddressID = pa.AddressID
INNER JOIN Person.StateProvince AS sp
ON sp.StateProvinceID = pa.StateProvinceID
WHERE sp.CountryRegionCode = ‘US’
ORDER BY sp.StateProvinceCode, so.OrderDate
A better example – which preserved the purpose of the outer join – would be to place a search argument on the table which is our outer table in the query. Before I show the query itself, let’s get some background on the data here.
In the Sales.Customer table there are 3,520 Customers in TerritoryID 1 (the northwestern US):
SELECT COUNT(*)
FROM Sales.Customer AS c
WHERE c.TerritoryID = 1 — 3520 customers
These Customers represent a total number of Sales of 4,594 orders:
SELECT COUNT(*)
FROM Sales.Customer AS c
JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
WHERE c.TerritoryID = 1 — 4594 orders
There are 92 customers that have never placed an order:
SELECT COUNT(*)
FROM Sales.Customer AS c
WHERE NOT EXISTS (SELECT *
FROM Sales.SalesOrderHeader AS so
WHERE so.CustomerID = c.CustomerID)
AND c.TerritoryID = 1 — 92 customers have not placed orders
If we want to see ALL Customers in TerritoryID 1 – regardless of whether or not they have placed an order and with their order information if they have, we can use an outer join to do this. For those customers who have not placed an order, NULLs will be produced:
SELECT so.OrderDate, c.AccountNumber, p.FirstName
, p.LastName, sp.StateProvinceCode
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
LEFT OUTER JOIN Person.Person AS p
ON c.PersonID = p.BusinessEntityID
LEFT OUTER JOIN Person.Address AS pa
ON so.ShipToAddressID = pa.AddressID
LEFT OUTER JOIN Person.StateProvince AS sp
ON sp.StateProvinceID = pa.StateProvinceID
WHERE C.TerritoryID = 1 — 4686 rows
ORDER BY sp.StateProvinceCode, so.OrderDate
This is different from an inner join because the INNER join will return only those customers that have a matching row in each and every joined table. In this case, all 3,520 customers have a matching row in Person.Person, Person.Address and Person.StateProvince. As a result, the inner join produces all 3,520 customers with their sales for 4,594 total rows. If you notice, the outer join above returned 4686 rows (4686 – 4594 = 92).
SELECT so.OrderDate, c.AccountNumber, p.FirstName
, p.LastName, sp.StateProvinceCode
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
INNER JOIN Person.Person AS p
ON c.PersonID = p.BusinessEntityID
INNER JOIN Person.Address AS pa
ON so.ShipToAddressID = pa.AddressID
INNER JOIN Person.StateProvince AS sp
ON sp.StateProvinceID = pa.StateProvinceID
WHERE C.TerritoryID = 1 — 4594
ORDER BY sp.StateProvinceCode, so.OrderDate
Using this query as our example, let’s go back to the original discussion about whether or not moving the search argument can improve performance… In the query below, I *solely* move the search argument (c.TerritoryID = 1) up into the FROM clause for the following query:
SELECT so.OrderDate, c.AccountNumber, p.FirstName
, p.LastName, sp.StateProvinceCode
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
AND C.TerritoryID = 1 — 20986 rows
LEFT OUTER JOIN Person.Person AS p
ON c.PersonID = p.BusinessEntityID
LEFT OUTER JOIN Person.Address AS pa
ON so.ShipToAddressID = pa.AddressID
LEFT OUTER JOIN Person.StateProvince AS sp
ON sp.StateProvinceID = pa.StateProvinceID
ORDER BY sp.StateProvinceCode, so.OrderDate
And it returns a drastically different result set of 20,986 rows. What’s happened here?
In this case, we’ve preserved ALL customer rows and then found the matching rows for ONLY those customers where TerritoryID = 1. To show you the numbers, it breaks down like this:
There are 19,820 customers – of which, 3,520 are in TerritoryID 1. Of these 3,520 customers in TerritoryID 1, all but 92 have placed orders – for a total of 4,594 orders. Bringing everything together:
19,820 customers – 3,520 in TerritoryID 1 = 16,300 rows
.4,594 orders + 92 customers that haven’t placed an order (remember – all customers are preserved in the outer join) = 4,686 rows
16,300 + 4,686 = 20,986 rows
Bringing this all together and to quote fellow MVP Hugo Kornelis (blog) in the discussion: “For OUTER joins, moving predicates does change the results. This makes performance comparisons moot. If a query gives incorrect results, I don’t care if it’s faster or slower than one that does yield the desired results.”
This is absolutely the most important point. You cannot just move a search argument “up” into the FROM without repercussions. In general, I recommend search arguments to be in the WHERE clause and join conditions in the FROM clause.
But, to make it even better, I thought I’d end with an even more simplified example of the sets described above:
SELECT c.CustomerID, so.SalesOrderNumber, so.OrderDate
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
WHERE c.TerritoryID = 1 — Northwest US, 4594 rows
go— in this simple inner join
SELECT c.CustomerID, so.SalesOrderNumber, so.OrderDate
FROM Sales.Customer AS c
INNER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
AND c.TerritoryID = 1 — Northwest US, 4594 rows
go— What if we want ALL Customers in the Northwest of the US,
— regardless of whether or not they placed an order:
SELECT c.CustomerID, so.SalesOrderNumber, so.OrderDate
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
WHERE c.TerritoryID = 1 — Northwest US, 4594 rows
go — Northwest US, 4686 rows— So, now what if we thought that the performance could be
— better if we pushed this up into the FROM clause…
SELECT c.CustomerID, so.SalesOrderNumber, so.OrderDate
FROM Sales.Customer AS c
LEFT OUTER JOIN Sales.SalesOrderHeader AS so
ON so.CustomerID = c.CustomerID
AND c.TerritoryID = 1 — 20986 rows— Absolutely ALL customers, regardless of whether or not they
— placed an order. For the Northwest territory we will see their
— order information but for all other customers (even those that
— have placed an order), we will NOT see their order information.
go
What’s probably most important is for you to thoroughly review the output of the last result set (of 20,986 rows). While I’ve explained the number – do you understand the results? Out of the 3,520 customers in TerritoryID 1 – 3,428 of them create 4,594 sales. For ONLY these sales, we see the SalesOrderNumber and SalesOrderDate. For all other customers – even those that have placed orders – we see NULLs. Why? Because moving this search argument up into the FROM has defined the criteria for the INNER join *BEFORE* the outer join is performed. This is why we see NULLs for those that have placed orders. If you order the results by TerritoryID this may help you better visualize what’s happening!
Thanks for reading and thanks for the comments and discussions… I love the SQL Community for its never ending passion!
Cheers,
Kimberly
2 thoughts on “Determining the position of search arguments in a join”
thank you for a great explanation!