A few weeks ago I kicked off a survey on how you add geo-redundancy to a failover cluster (see here for the survey). The results as of 8/26/09 are as follows:
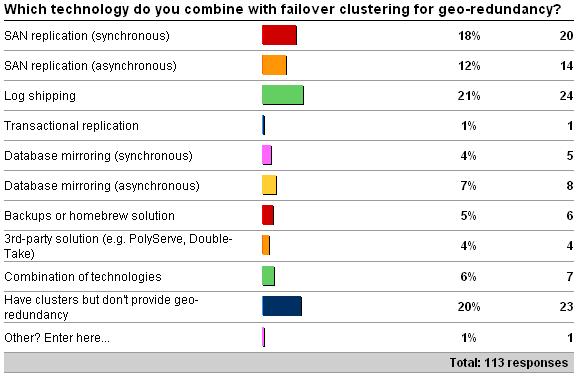
So why is this interesting? Well, many people will suggest failover clustering as the best way to provide high-availability for a database (or group of databases). And it is a great technology to protect against server failure, but there's only a single copy of the database, which is the Achilles' heel of failover clustering. If that copy of the database is damaged, the application is down unless there's another copy of the database available. This is where providing geo-redundancy comes in. With that in mind, I'm surprised at the percentage of respondents that don't provide any geo-redundancy at all.
There are a bunch of options for providing a redundant copy of a database that is hosted on a failover cluster, with pros and cons to each, and that's what I'm going to spend the rest of this post on.
SAN replication: This is where the SAN hardware itself mirrors all write I/Os to a remote SAN, thus maintaining a remote copy of the database. The hardware has to provide disk-block size and write-order preservation; otherwise the database on the remote SAN could become corrupt. Imagine if write-ordering was not preserved and some data pages write I/Os were completed on the remote SAN before log records write I/Os (thereby breaking the write-ahead logging protocol) – recovery wouldn't be able to work properly! This mechanism requires a remote SAN, a second failover cluster connected to the remote SAN, a network including both clusters, and a big, fat network pipe between the two SANs. The bigness and fatness of the pipe depends, of course, on how many write I/Os are performed on the local SAN, and whether the SAN replication is synchronous or asynchronous.
Synchronous replication requires that the I/O is completed on the remote SAN and acknowledged back to the local SAN before the local I/O can be acknowledged to the local server. If the network bandwidth and latency can't support the volume of write I/Os trying to be replicated to the remote SAN, the I/Os will start to queue up and delays will be incurred on the local server. This will lead to the workload slowing down as SQL Server has to wait longer and longer for I/Os to complete. Now, with synchronous replication you have the guarantee that the remote copy of the database is completely in-sync with the local copy, so if a failure occurs, no committed data will be lost. If the network can't keep up though, you may have to switch to asynchronous replication. This means the local I/Os don't have to wait for the remote I/Os to complete, and so no performance penalty is incurred. BUT as the replication is now asynchronous, committed data may be lost if the local copy of the SAN is damaged.
Apart from the potential for performance problems with SAN replication, it's also very expensive – as another SAN, another cluster, and some beefy network hardware/bandwidth is required. This isn't a technology I'd expect a small company to be using or considering. Finally, the portion of the remote SAN that's being replicated to cannot be accessed at all. On the MAJOR plus side, all databases on the SAN are replicated at once, without having to setup a technology to provide a redundant copy of each. For application ecosystems that include multiple databases, this is what I like to recommend.
Log shipping: This is the simplest way to maintain a redundant copy of the database – it's just backup log, copy, restore log; repeat. It works seamlessly with failover clustering and is really easy to setup and maintain. The only problem with this is that you open yourself up to data loss, as a log shipping secondary is usually not right up-to-date with the primary. You can use the secondary for reporting/querying by restoring the log backup WITH STANDBY (which requires a little more configuration, but not much), and you can protect against accidental data damage by having a secondary with a load-delay configured, so the database is, say, 8 hours behind the primary. In my experience, this is the most common technology that's used in conjunction with failover clustering as it's the cheapest and easiest. On the downside, it's a single database solution so its not suitable for complicated application ecosystems.
Transactional replication: This isn't very commonly used at all, although again, it works seamlessly with failover clustering after a failover. The reason this isn't used very often for geo-redundancy is that transactional replication doesn't provide database-level redundancy, only table-level. It's also much more complicated to setup and troubleshoot when things go wrong, plus there's varying latency between a transaction committing in the publication database and it being applied to the subscription database(s).
Database mirroring: Database mirroring is the only technology apart from SAN replication that can provide a zero data-loss solution when configured for synchronous operation. It works by shipping the log records from a database rather than the raw I/Os, so doesn't require anywhere near as much capital expenditure, but the network has to be able to cope with sending the log generated on the principal, otherwise performance on the principal can be affected. Mirroring is relatively easy to setup and maintain, and the mirror database can only be accessed, but only through a database snapshot. When combined with failover clustering, you need to be careful about setting the mirroring partner timeout, so that the local failover cluster gets a chance to fail over before mirroring does. Checkout my blog post on this: Search Engine Q&A #3: Database mirroring failover types and partner timeouts. You can configure database mirroring for synchronous or asychronous operation, with the same performance and data-loss exposure caveats as SAN replication. SQL Server 2008 provides log stream compression and automatic page repair, which make this more attractive (see SQL Server 2008: Performance boost for Database Mirroring and SQL Server 2008: Automatic Page Repair with Database Mirroring, respectively), but only supports a single database. I'm seeing this combination start to be used more, but again, it's a single database solution so isn't suitable for complicated application ecosystems.
Backups/homebrew: Good old backups can easily be used to provide a very low cost way of maintaining a redundant copy of a database, and if you think about it, this is really do-it-yourself log shipping. At the very least, databases should *always* be included in a backup strategy, no matter what other high-availability technology(s) you may have implemented.
3rd-party solution: There are a few non-Microsoft solutions for providing redundancy with failover clustering which don't involve traditional SAN replication. I'm not an expert in any of them, but I've heard of anecdotal issues with the two I mentioned in the survey and worked with customers who've had real issues with PolyServe (one of which I blogged about).
Summary
When you're planning a high-availability strategy, you always need to consider the limitations of technologies while evaluating them. The big limitation of failover clustering is that there's no redundant copy of the database so you need to add another technology to provide that. I've just finished writing a 35-page whitepaper for Microsoft on the high-availability technologies in SQL Server 2008, as well as how to go about planning a strategy. It will be published before PASS in November, but in the meantime, this should have given you lots of food for thought.
Next post – the next survey!