A couple of weeks ago I kicked off a survey asking how often you perform full backups of your databases.
Here are the results:
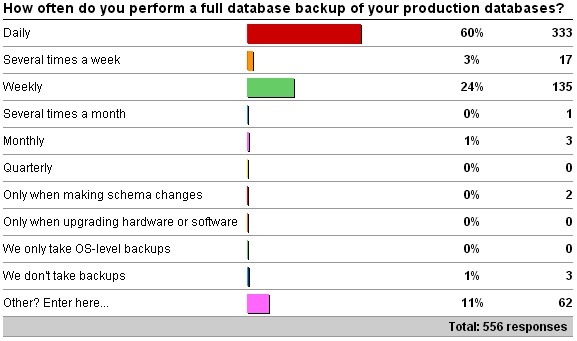
The ‘Other’ values are:
- 20 x ‘Daily for small dbs, weekly (with daily diff) for large dbs.’
- 16 x ‘Depends. Some daily, some weekly.’
- 5 x ‘Daily on small, weekly on vldb, and before/after for schema, or physical changes and software upgrades.’
- 5 x ‘Weekly and daily differential backups.’
- 4 x ‘Every 12 hours.’
- 2 x ‘Depends: some weekly with daily diffs an hourly transaction logs, others are daily fulls with transaction logs depending on various criticality and disk requirements.’
- 2 x ‘Every 2 weeks.’
- 1 x ‘Daily on system DBs; Weekly on User DBs with Differentials daily.’
- 1 x ‘Every other day, with differentials every 8 hours.’
- 1 x ‘It depends on size and criticality. Some are performed daily and others weekly. Diffs are performed for weekly and transaction log backups are done for both in 10 minute intervals.’
- 1 x ‘Never I only have a test database.’
- 1 x ‘Some servers daily, others weekly.’
- 1 x ‘Storage snapshot every hour and weekly native.’
- 1 x ‘We take storage snapshots every two hours.’
I’m actually a bit surprised at the results as I expected there to be a larger number for Weekly than Daily, but more frequent backups are good, if you can do them.
Example Strategies
My opinion is that performing a full backup any less frequently than once a week is dangerous – opening you up to a higher likelihood that you won’t be able to recover in the event of a disaster.
Here are two example strategies: full backup monthly on the first of the month vs. full backup weekly on Sunday morning, with two months of backups being stored in both cases. Both strategies are using daily differential backups and hourly log backups. There’s a lot of data churn across a large proportion of the database. The database size grows at 5% per month.
Now let’s look at a disaster occurring on the last day of the November 2012.
With the first strategy, we restore the full backup from November 1st, and then the differential backup from November 29th, plus log backups up to the point of the crash. The differential backup will be very large because of the data churn. If the full backup is damaged in any way, we need to go back to the full backup from October 1st, plus the differential backup from October 31st, and then all the log backups through November, as the differential backups in November are only valid on top of the full backup from November 1st. This isn’t a problem with differential backups; this is just how they work. Understand that and you’re good to go.
With the second strategy, we restore the full backup from the previous Sunday, November 25th, the differential backup from November 29th, plus log backups up to the point of the crash. In this case the differential backup will be smaller and faster to restore than the ones from the first strategy. And if the full backup is damaged, we only have to go back one week prior, to the one from Sunday 18th, then the last differential from it on November 24th, and a week of log backups. There’s clearly more flexibility with this strategy, and shorter restore times.
Summary
If you have the space, and can afford the I/O hit of performing more frequent backups, then perform full backups as frequently as you can, and make full use of differential backups to limit the restore time, instead of replaying all those operations using log backups. Yes, it’s a little bit more complicated, but you’re smart, right? Don’t let people scaremonger you away from using differential backups – they’re as easy to use as log backups as long as you understand their uses and limitations.
As I discussed in my previous blog post today (Importance of where you store your backups), it’s all about making sure you have the right backups, available quickly, to be able to restore within your downtime and data loss SLAs. When did you last check that’s possible with your environment?
This is my last technical post this year – watch out for the yearly wrap-up and books posts on December 31st. Cheers!
4 thoughts on “Importance of how often you take full backups”
Paul, thank you for a useful post. Hope to track your blog more on the DB backups.
Hi Paul,
Thanks for your posts. I setup mirror for production db and have a job to backup log frequently 15 minutes. So do i need to perform full backup frequently ?
Technically no, but yes if you want to be able to recover from disaster and your mirror is trashed. You must always have a backup strategy and an HA/DR strategy to cope with disasters.
Got it. Thanks Paul.