I recently had a scenario in a two-node Availability Group where multiple large-batch modification queries were executed and created a large redo queue on the replica. The storage on the replica is slower than that on the primary (not a desired scenario, but it is what it is) and the secondary has fallen behind before, but this time it was to the point where it made more sense remove the database from the replica and re-initialize, rather than wait several hours for it to catch up. What I’m about detail is not an ideal solution. In fact, your solution should be architected to avoid this scenario entirely (storage of equal capability for all involved nodes is essential). But, stuff happens (e.g., a secondary database unexpectedly pausing), and the goal was to get the replica synchronized again with no downtime.
In my demo environment I have two nodes, CAP and BUCKY. CAP is the primary, BUCKY is the replica, and there are two databases, AdventureWorks2012 and WideWorldImporters in my TestLocation AG:
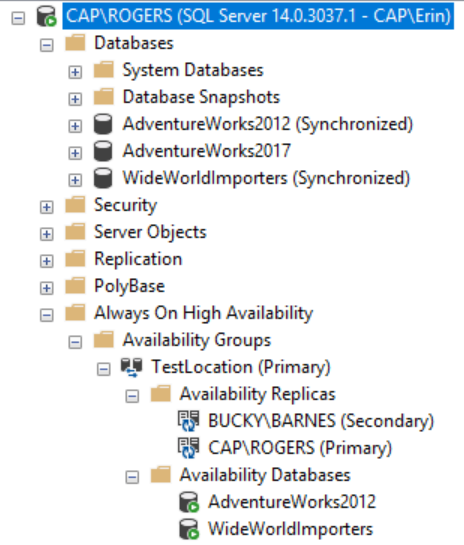
In this case, my WideWorldImporters database is the one that’s behind on the secondary replica, so this is the database we want to remove and then re-initialize. On the secondary (BUCKY) we will remove WideWorldImporters from the AG with this TSQL:
USE [master];
GO
ALTER DATABASE [WideWorldImporters]
SET HADR OFF;
GO
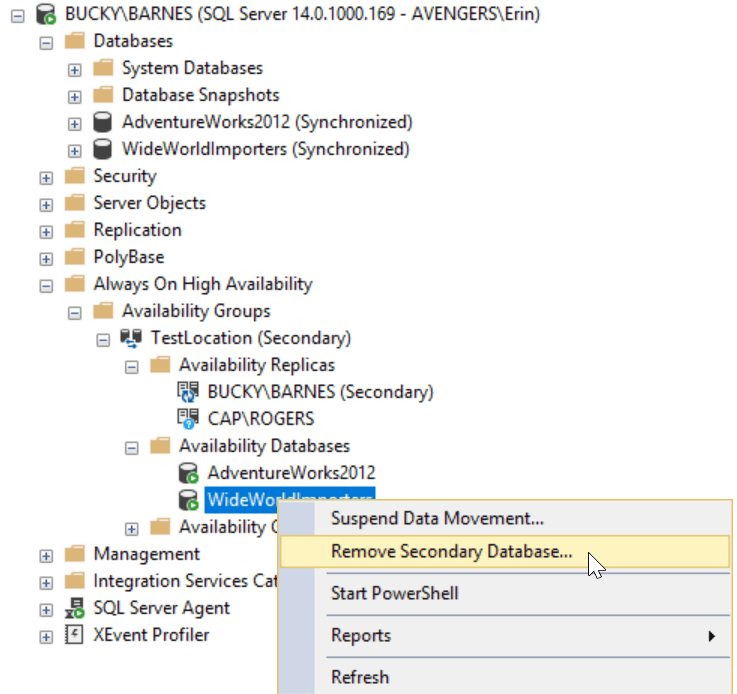
You can also do this in the UI, if you right-click on the database within the AG and select Remove Secondary Database, but I recommend scripting it and then running it (screen shot for reference):
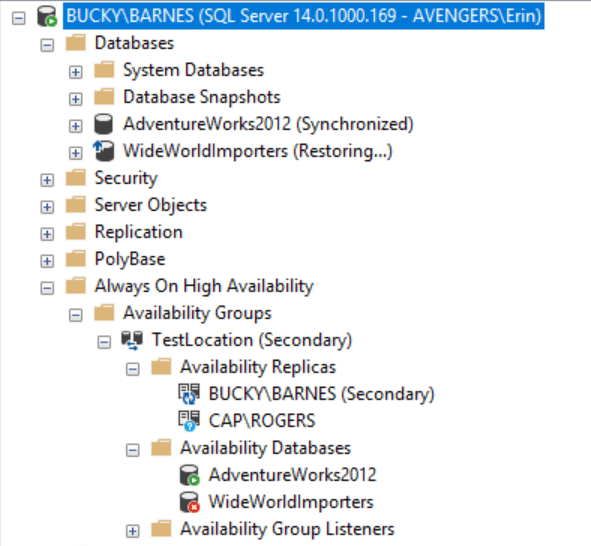
After removing the database, it will still be listed for the AG but it will have a red X next to it (don’t panic). It will also be listed in the list of Databases, but it will have a status of Restoring…
If you check the primary, the WideWorldImporters database there is healthy:
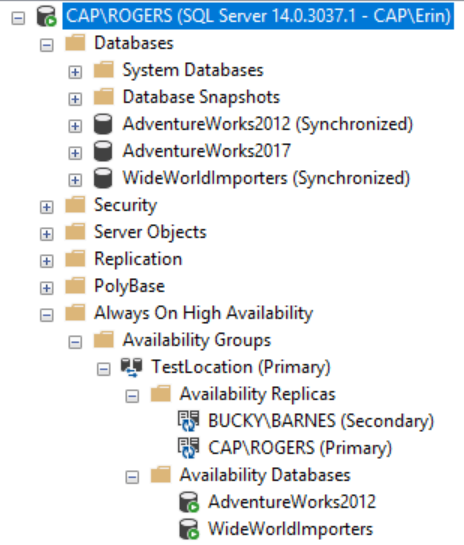
You can still access WideWorldImporters as it’s part of the AG and using the Listener. The system is still available, but I’m playing without a net. If the primary goes down, I will have not have access to the WideWorldImporters database. In this specific case, this was a risk I was willing to take (again, because the time to restore the database was less than the time it would take the secondary to catch up). Also note that because this database is in an Availability Group by itself, the transaction log will be truncated when it’s backed up.
At this point, you want to kick off a restore of the most recent full backup of the database on the replica (BUCKY):
USE [master];
GO
RESTORE DATABASE [WideWorldImporters]
FROM DISK = N'C:\Backups\WWI_Full.bak'
WITH FILE = 1,
MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters.mdf',
MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters_UserData.ndf',
MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters.ldf',
MOVE N'WWI_InMemory_Data_1' TO N'C:\Databases\WideWorldImporters_InMemory_Data_1',
NORECOVERY,
REPLACE,
STATS = 5;
GO
Depending on how long this takes, at some point I disable the jobs that run differential or log backups on the primary (CAP), and then manually kick off a differential backup on the primary (CAP).
USE [master];
GO
BACKUP DATABASE [WideWorldImporters]
TO DISK = N'C:\Backups\WWI_Diff.bak'
WITH DIFFERENTIAL ,
INIT,
STATS = 10;
GO
Next, restore the differential on the replica (BUCKY):
USE [master];
GO
RESTORE DATABASE [WideWorldImporters]
FROM DISK = N'C:\Backups\WWI_Diff.bak'
WITH FILE = 1,
NORECOVERY,
STATS = 5;
GO
Finally, take a log backup on the primary (CAP):
USE [master];
GO
BACKUP LOG [WideWorldImporters]
TO DISK = N'C:\Backups\WWI_Log.trn'
WITH NOFORMAT,
INIT,
STATS = 10;
GO
And then restore that log backup on the replica (BUCKY):
USE [master];
GO
RESTORE LOG [WideWorldImporters]
FROM DISK = N'C:\Backups\WWI_Log.trn'
WITH FILE = 1,
NORECOVERY,
STATS = 5;
GO
At this point, the database is re-initialized and ready to be added back to the Availability Group.
Now, when I ran into this the other day, I also wanted to apply a startup trace flag to the primary replica and restart the instance. I also wanted to make sure that the AG wouldn’t try to failover when the instance restarted, so I temporarily changed the primary to manual failover (executed on CAP, screenshot for reference):
USE [master];
GO
ALTER AVAILABILITY GROUP [TestLocation]
MODIFY REPLICA ON N'CAP\ROGERS' WITH (FAILOVER_MODE = MANUAL);
GO
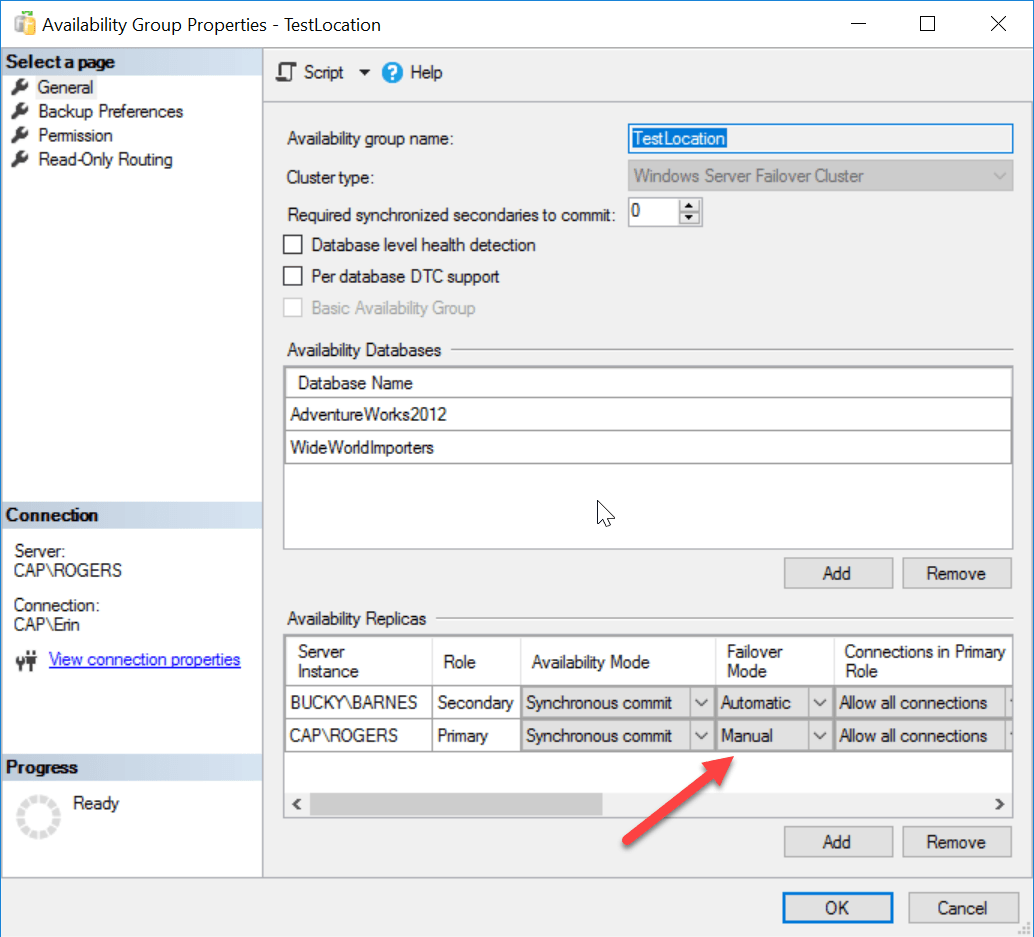
I restarted the instance, confirmed my trace flag was in play, and then changed the FAILOVER_MODE back to automatic:
USE [master];
GO
ALTER AVAILABILITY GROUP [TestLocation]
MODIFY REPLICA ON N'CAP\ROGERS' WITH (FAILOVER_MODE = AUTOMATIC);
GO
The last step is to join the WideWorldImporters database on the replica back to the AG:
ALTER DATABASE [WideWorldImporters]
SET HADR AVAILABILITY GROUP = TestLocation;
GO
After joining the database back to the AG, be prepared to wait for the databases to synchronize before things look healthy. Initially I saw this:
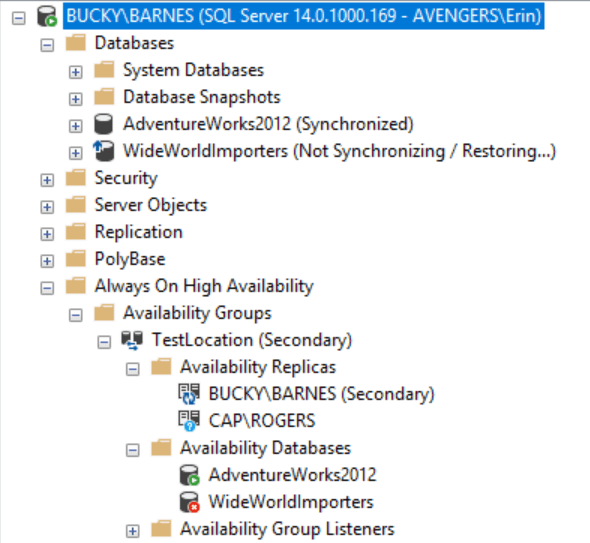
Transactions were still occurring on the primary between the time of the log being applied on the secondary (BUCKY) and the database being joined to the AG from the secondary. You can check the dashboard to confirm this:
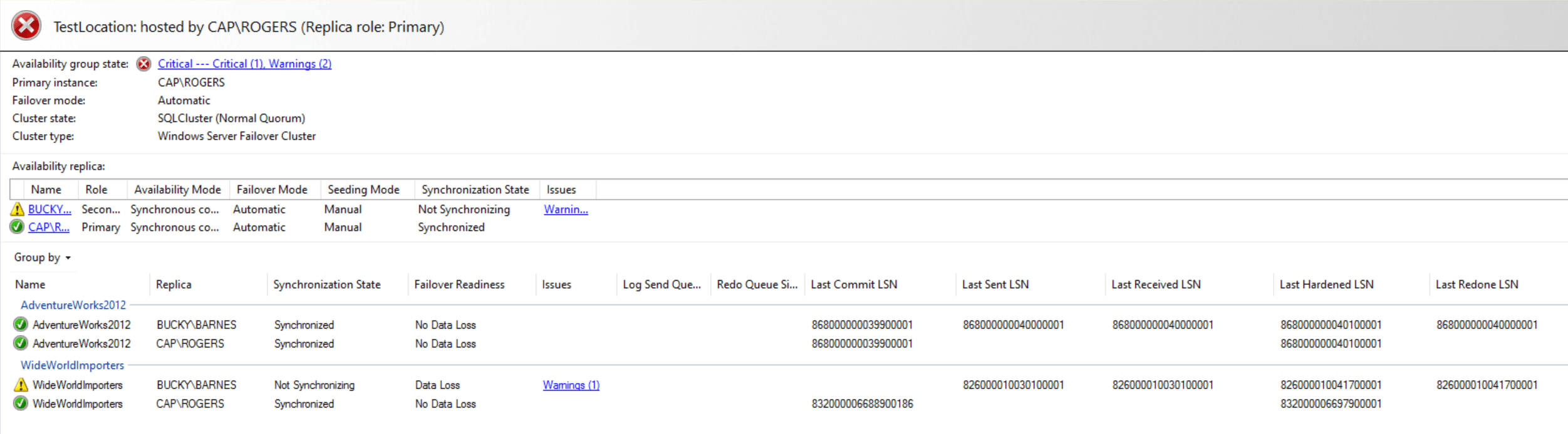
Once the transactions had been replayed, everything was synchronized and healthy:
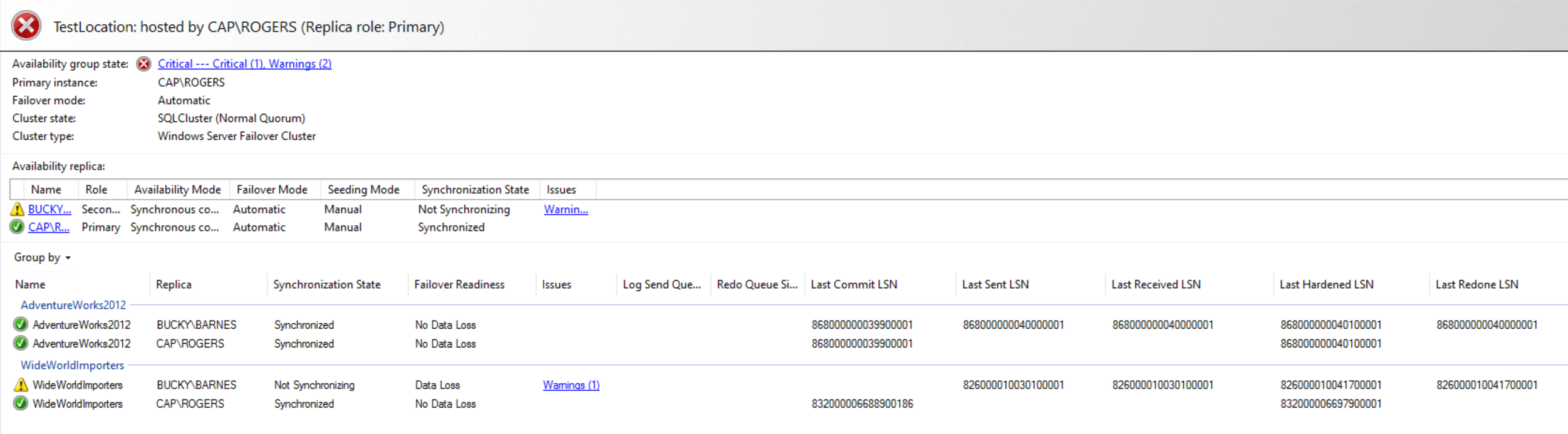
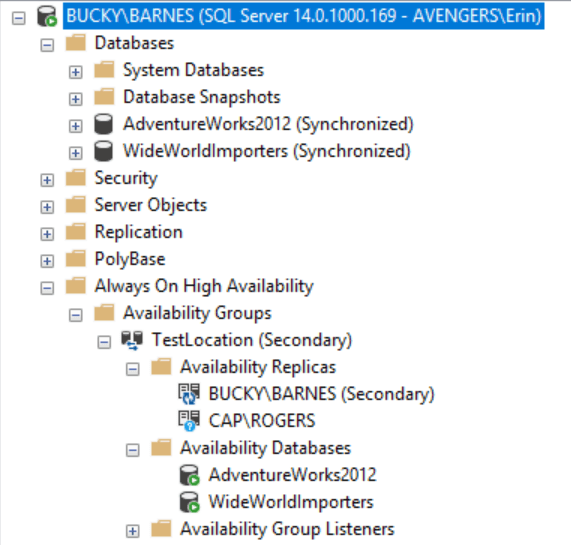
Once the databases are synchronized, make sure to re-enable the jobs that run differential and log backups on the primary (CAP). In the end, removing a database from a replica in an Availability Group (and then adding it back) is probably not something you will need to do on a regular basis. This is a process worth practicing in a test environment at least once, so you’re comfortable with it should the need arise.
4 thoughts on “Removing a database from a replica in an Availability Group”
Good article, thank you! We do this regularly where we have a prod AG environment database backup being restored to an identical test AG environment system, is there a different way we should be doing that? Also in testing we have actually found it faster to just use Automatic seeding with Trace Flag 9567 (compression).
Hey Jim-
Thanks for your comment, but can you clarify what you mean by doing this regularly from prod to test? I was removing the secondary DB from the AG and then adding it back to the same AG…and not making any changes to the primary database.
It sounds like you are taking a backup from prod, restoring to dev and then…creating the AG? Is that correct?
Erin
Good article, as jim said, i’m regularly in the same scenario where customers needs to reload test environment with live backup.
so, T-SQL is my preference , i remember my last MCSE where it was a good idea to have a T-SQL strong knowledge
best regards
Eric
Hi Erin,
First, thank-you for writing this article, it was very informative; in addition, I was wondering if you guys could perhaps blog about a Distributed Availability Groups or DAGs?
For instance, the process of adding and removing Databases on a DAG is very similar but also different at the same time than a straight AG and seems to come with a different set of challenges; some steps can be done via the SSMS GUI while other steps must be scripted; and the exact order is not at all well documented.
Then, there are the problems that comes with synchronization (never really catching up) or, if synchronization fails completely, what steps do you take to diagnose and resolve the issue or just rebuild the DAG completely (and what a task that can be, starting over).
Microsoft might call this Enterprise level HADR, but if you can’t find the tools right away to diagnose performance issues or recover failure, then I’m not sure its really Enterprise Level HADR.