So one of the features I had a hand in building in SQL Server 2005 is really useful for helping SQL Server work well in large data warehouse deployments.
I led a team writing the paper that was published about this, and you can read it in my previous blog post here. The paper covers the theory but not the implementation.
The basic idea is that SQL Server has a lot of competing memory consumers within a single process space. Often the naive approach (block incoming requests until there is enough memory) will fail under extreme circumstances because there is even incoming requests take some amount of memory, and you can starve on memory waiting for memory. Additionally, many of the components are built to run best with fewer queries running in the system – for example, hash joins run a lot faster when they do not spill to disk. When you add it all up, you have a bunch of different memory consumers with a bunch of different optimal policies to achieve optimal performance.
For the query optimizer, we tried a number of different approaches in the naive space before we eventually settled on a tiered set of monitors that block based on how much memory an in-process memory optimization has consumed compared to the free memory in the system. This meant that the system would not block any trivially small query from compiling, allow a certain number of normal (OLTP) queries to compile, allow a fewer number of medium (think basic DSS) queries to compile, and have one final bucket to allow for the largest query in human history to compile. (Note that I am not saying “execute” – there are a different set of queues for those queries).
What we found was that, as SQL Server started to be used in larger and larger deployments, the optimizer would consume more memory in those situations where large DW queries were coming into the system. This led to out of memory errors thrown during compilation or execution. The cost of restarting these queries was high (often the plan wasn’t in the cache yet or was thrown out of the cache quickly due to memory pressure), and the system would just go into a memory-thrashing fit.
So how do I tell if my system is in a memory-thrashing fit due to compilation-overload? Well, there is a command called DBCC MEMORYSTATUS that will tell you a bit about where you are. If you scroll through the various rowsets returned, you’ll eventually find one called “Optimization Queue”. This reflects the total memory available for all optimizations in the system, and the SQL OS layer controls this. If lots of other things need memory, this will get clamped down. The next 3 should be familiar by now – they are the various gateways to block queries of various sizes. The “Threshold factor” is the amount of memory at which the optimizer will start trying to block that query from continuing until other queries in that bucket have completed compilation.
The “(default)” postfix is for normal user queries. The “(internal)” queues are for internal queries. There aren’t a ton of internal queries.
Here’s a screenshot of this in action:
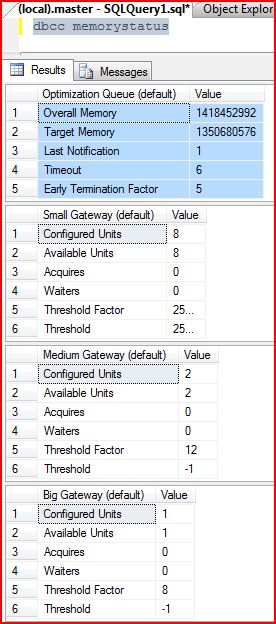
Now, last I checked I didn’t have a large-scale data warehouse running on my desktop, so these numbers are pretty tame right now. You can run this command on a production system to see where you stand – it is intended to run quickly for debugging purposes on running systems, actually.
Enjoy!
Conor Cunningham