I’ve been playing with the new grouping sets feature now that it’s in a CTP, partially because I had a small hand in them before I left Microsoft, but partially because I’m trying to re-examine features from a more external perspective. So, I figure this is a good conversation starter.
So, as all programmers are lazy, I started with my former collegue Craig’s blog post on the subject (http://blogs.msdn.com/craigfr/archive/2007/10/11/grouping-sets-in-sql-server-2008.aspx). Craig’s a query execution guy by training (and a darn good one), so many of Craig’s blog posts are pretty complimentary to my background. Anyways, his post doesn’t talk about the various plans. Part of the reason is that GROUPING SETS contains a fair amount of syntactic sugar. It’s a feature that lets you write CUBEs and ROLLUPs in a different way. It’s slightly more general and powerful, but I’m still trying to get my head around why Oracle/IBM pushed to get this added to the ANSI spec. You can do most of this with CUBE + filters (and a good query optimizer).
So let’s talk about cube and rollup plans from an outsider’s perspective, as I haven’t seen anyone write about this in the depth that I would like.
If I take a the rollup query from Craig’s example in SQL Server 2008’s November CTP, I can see the following plan:

ok, two aggregates – what’s up with that? Well, if you look at the properties for the second aggregate, you can see that there is an extra bit of information that tells you that it’s actually not a classical aggregate operator:
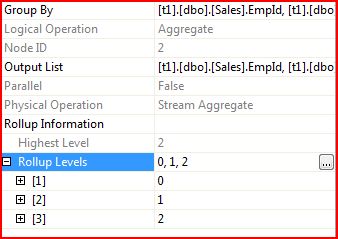
ok, so this guy does some special magic but it is represented in the external query plan as an aggregate function evaluator. It just adds the extra rows that you see in a ROLLUP query.
The key part of ROLLUPs is that they can be computed in one linear pass of the data (sorted appropriately).
CUBE plans are a little trickier:
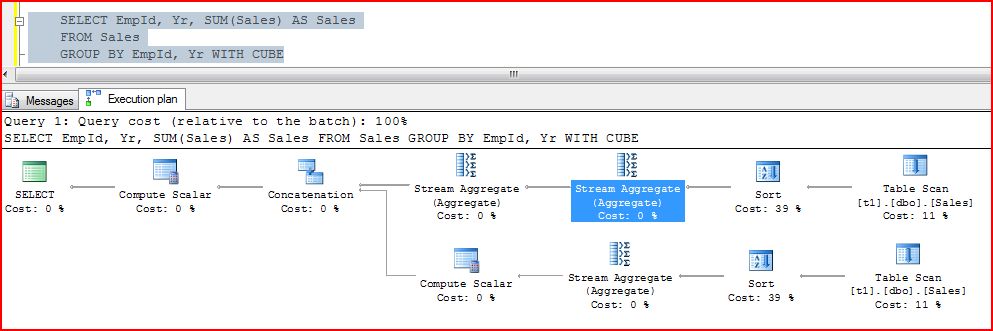
So the QP conatenates a number of different branches of operations, and it actually ends up being a way to compute the matrix of different dimensions – if you have more columns in your cube query, you’ll get more branches. If you look at the second “stream aggregate” in a branch with 2, you’ll see the rollup information just like in the rollup example.
So CUBE is a fancier form of ROLLUP. Obviously it has one sort per dimension, which is EXPENSIVE on big tables. (You could have indexes for each branch, which could make things faster, assuming you have the disk space for the indexes).
In SQL 2005, the plan is slightly different for Craig’s example:

This plan is great if the size of the data going through the CUBEing operation is much smaller than the size of the table. In this case, it writes the data to a temporary spool, sorts the output of that, and then re-reads that spool in the second branch. I don’t recall if SQL Server 2005 generated the SQL 2008 plan or not, but the SQL 2008 plan is potentially more parallelizable since each branch is independent. Note that reading the base table twice could open you up to more interesting locking, but this can happen in any query with multiple scans of the same table if your isolation level is too low. I haven’t tried to create a parllel CUBE plan on SQL 2008, but I’d guess it is possible…
ok, so now we can add in GROUPING SETS. These are essentially CUBEs with the ability to prune branches you don’t need. This can get more interesting when you have lots of columns on which you are CUBEing, but the example from Craig that I’m using here doesn’t do much beyond CUBE.
Technically, one could try to start filtering NULLs from the result of a CUBE and perhaps the query optimizer could work backwards to deduct that it didn’t need to compute various branches of a CUBE like GROUPING SETs can do. Obviously it’s easier when the customer just tells the QP what it wants directly.
I haven’t tried to exhaustively go through the various kinds of plans likely in SQL Server. There aren’t really that many with ROLLUP/CUBE, at least not from what I’ve seen. However, I hope this gives you an intro into how they work and how you can look at the query execution plan to see what is happening.
Now’s the part where I get to ask for your input so I can learn something ;). I want to hear about scenarios where you use CUBE/ROLLUP today – please send me a mail at conor@sqlskills.com! I’ll post up a summary of what I learn. If you plan to use GROUPING SETS, let me know that too. I’m
very curious about what scenarios people do relational computations
like this (as opposed to using Analysis services, for example).
Thanks for reading!
Conor Cunningham