So as you proceed up the river into the jungle, searching for answers about how the query optimizer works, I’ll ask you one question: Did you know that there’s actually a lot of stuff that the Optimizer team just tells you? It’s in the product, and I’m constantly suprised by how little attention they get. You can learn all sorts of things by looking at the data. Now, not all of it is documented, but that’s usually just because one needs leeway to change the internals rather than some deep, dark secret that needs to be kept.
Now that you’re hooked ;), I’ll tell you a bit about an optimizer DMV called sys.dm_exec_query_optimizer_info. It tells you all sorts of things about how your querys are optimized. It’s a bag of counters for all sorts of things that, with a trained eye, can give you lots of insight into what is happening.
This guy is actually documented, at least partially, on MSDN.
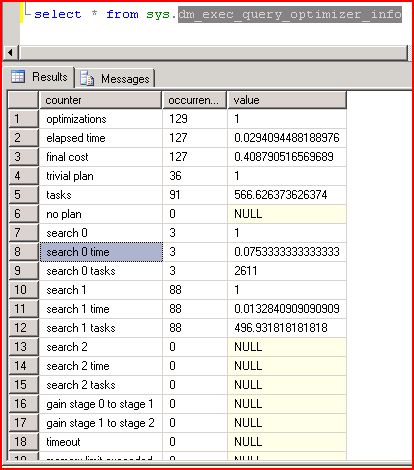
(That’s from my SQL 2008 install, btw).
Some of these fields are “undocumented”. search 0, 1, and 2 are in that category. I won’t talk about them except to say that the names aren’t really obfuscated too much.
To learn about a particular query, you find a nice, quiet server and:
1. select * from this table, store the results somewhere
2. optimize a query of interest,
3. select from this table again, then compare the current totals to the originals.
I think that this is one use of this DMV – trying to figure out why a query takes a long time to optimize.
The other use of the DMV is to get a good statistical picture of a running system. Say that I’m a DBA and I want to know how many queries in my application have hints or _need_ hints to work well. Well, this will tell you. Granted, it doesn’t separate recompiles from compiles, and if you have a system where plans are getting kicked out of the cache things may be a bit skewed, but I can tell you that this is far better than simply guessing. Often the DB application developer doesn’t realize that they’ve built an application that requires a lot of hinting or a lot of compilations, and you can see this in more detail than you get with the performance counters.
I’ve already talked about “trivial plans”, which are not documented in this DMV but are widely known in the other outputs of the system. I’ll let you guys guess about the search 0, 1, and 2 stuff – if you can back up your guess with a public post, book, or other form of comment I’ll confirm if you get it right.
Have a great weekend, ya’ll.
Conor Cunningham