In my previous post, I talked about the basics of partition elimination and mentioned some of the challenges. SQL 2005 does contain logic to do partition elimination, but it is imperfect because some of the interactions with other features in the optimizer didn’t always do partition elimination when customers wanted/expected it to do so. SQL 2008 uses a somewhat different internal notation for partitioning, and it appears (from what I have seen so far) to do a better job at some of the interactions that were troublesome for 2005. This should make partitioning work much more seamlessly in the upcoming release.
This example was motivated by a reader of the blog (thanks!) who was using a partitioned fact table for sales data and joining to another table to roll his own row-level security. I’ve seen a number of customers do row-level security this way, so it’s actually not a bad example for how things can break down in partition elimination in 2005 vs. 2008. Here is the script we’ll use for the example:
create partition function pf2(int) as range left for values (10, 20, 30)
create partition scheme ps2 as partition pf2 ALL to ([primary])
create table usersecuritybysite(username nvarchar(100), site int)
insert into usersecuritybysite(username, site) values ('dbo', 1)
insert into usersecuritybysite(username, site) values ('dbo', 2)
create table factsales(site int, invoice int, itemid int, col3 binary(2000)) ON ps2(site)
insert into factsales (site, invoice, itemid) values (1, 1, 1)
insert into factsales (site, invoice, itemid) values (2, 1, 1)
insert into factsales (site, invoice, itemid) values (3, 1, 1)
insert into factsales (site, invoice, itemid) values (4, 1, 1)
This obviously has far less data than an actual fact table, but I’ll show you the plans that are interesting from this example and they should translate to an evaluation of a plan on a full-scale system.
So, we have two tables, both heaps. The fact table is partitioned, and we will always join with an unpartitioned (but likely smaller) table when querying the fact table. SQL 2005 generates the following plan:
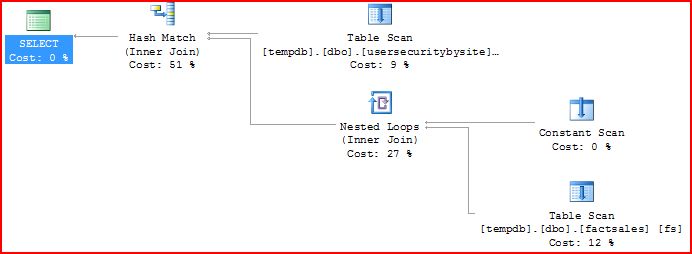
So the optimizer generates a plan to build a hash table from usersecuritybysite and then probe it with every row from the partitioned table. That’s actually not a horrible plan, but as the cardinality of the fact table increases, this will get worse because we’re scanning all partitions. If we look at the statistics profile, we can see that all 4 partitions are scanned once in this plan. Ideally, we’d like it to use the information from the usersecuritybysite table to eliminate partitions “almost always”. That would be safer. (Nothing in optimization is simple, and there are actually more plans I’d consider here, but I’d like to focus on the point of not touching useless partitions in this post – in this case, I actually do want to avoid touching unneeded partitions as often as possible).

The constant scan with values 1,2,3,4 is where the partition information is encoded in SQL 2005.
Each partition has roughly the startup cost of a table, so think of this as opening 4 tables. Databases are usually optimized so that reading lots of rows is the fastest thing – opening tables won’t be as fast as opening rows, and when push comes to shove one will optimize row reads at the expense of table opens every time.
Let’s look at the SQL 2008 plan: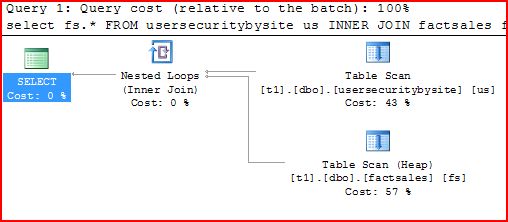
Hey, what happened? Well, the internal plan representation in SQL 2005 was pretty good but not perfect. I think it’s fair to say that it does a better job than partitioned views for local cases, but it wasn’t as good as the non-partitioned tables in a few cases. Many of the improvements that were driven in 2005 led to lessons that were incorporated in 2008’s optimizer support. Specifically, compilation time is higher in 2005 for partitioned tables because there are more operators in the tree. Also, the introduction of these extra operators happened to make “trivial” plans no longer “trivial” (because partitioning is represented as a join in 2005, and joins mean cost-based choices, and therefore it is not “trivial” to choose a plan). Finally, some of the plan choices that happen in the non-partitioned cases from years and years of tweaking queries didn’t quite fit with partitioning because of the representation. For example, index selection didn’t know as much about partition selection as it needed to have to make perfect plan choices.
So, 2008 changes things largely for the better. The stats profile for this plan in 2008 is here:

So you’ll notice a few things. First, the constant scan is gone, and this plan looks like the non-partitioned plan. Hey, is that a seek? What’s up with that? This is a heap!!! Well, the optimizer now has some smarts to treat partitioning as a special leading index key, and even heaps can have them. So, now the index selection code can do most of the partitioning applications better and avoid some of those seams I mentioned earlier. It’s harder to tell how many partitions got pruned, but if you look at the text more closely:
|–Table Scan(OBJECT:([t1].[dbo].[factsales] AS [fs]), SEEK:([PtnId1004]=RangePartitionNew([t1].[dbo].[usersecuritybysite].[site] as [us].[site],(0),(10),(20),(30))), WHERE:([t1].[dbo].[factsales].[site] as [fs].[site]=[t1].[dbo].[usersecuritybysite].[site] as [us].[site]) ORDERED FORWARD)
You can see that the optimizer is running some partition function on the usersecuritybysite.site column as part of the SEEK. I’m asking my friends if this is the only indication I can see beyond looking down at the lock manager, but this is what I can see right now.
To be clear, 2005 also has the ability to partition pruning. I’m not sure how many people store their fact tables in heaps and how often it happens to not prune. If we create a clustered index on the fact table in 2005, you get a better plan:
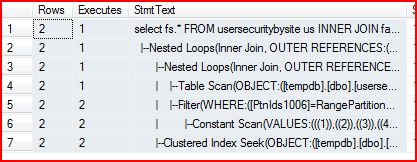
This isn’t quite as perfect as the 2008 plan, but it does avoid opening unneeded partitions. In this case, the security table is scanned and joined with the list of partitions run against the partition function. This generates the right partition to open for each security table row. It happens to work great for this case because the table is being used as a “gate” to let the user see the partition or not. Things get a bit more complex when the non-partitioned tables has duplicates or many rows from the fact table can be matched (you might want to pre-sort your partition requests and use a different plan in that case to avoid re-opening partitions).
So, the bottom line is that this stuff is complicated and it’s a possible to get an imperfect plan at times. You can use this technique to see if your 2005 plan is eliminating all the partitions you would expect. If you end up with a plan that doesn’t prune properly, you can do things like split the query or use a hint to force the optimizer to do what you want. I’d recommend that you know what you are doing before going down either path. Everyone has different levels of experience on this stuff, and it can be tricky to fully understand all of the interactions. I hope I’ve given you enough insight in this post to see whether you have a problem.
Also, please be careful using statistics profile on a production machine, and be sure to turn it off when you are done – it slows down queries, and nothing makes Conor angrier than a needlessly slow query ;).
Have a good weekend, y’all!
Conor