One of the earlier comments I received asked about costing of T-SQL and CLR functions. More specifically, they want to know how they are costed and why it is so low.
Let’s create a motivating example. I’ll create a table with some size to it (I add a binary(2000) column to make each page take at least 2000 bytes, and this means that about 4 rows fit on a page. So, if I add 100,000 rows to a table, we’re talking about enough IOs to show up in the costing functions).
use t1
create table t3(col1 int, col2 binary(2000))
insert into t3(col1, col2) values (2, 0x1234)
insert into t3(col1, col2) values (3, 0x1234)
declare @p int
set @p=0
while @p < 100000
begin
insert into t3(col1, col2) values (rand()*1000, 0x1234)
set @p=@p+1
end
create function f3(@p1 int) RETURNS int
BEGIN
return (select count(col1) from t3 where col1=@p1)
END
select dbo.f3(2)
(I apologize for my lack of real-world examples.. After you’ve done this a few thousand times you resort to the shortest names you can type ;).
ok, so we have a table and we create a T-SQL scalar function that just runs an aggregate to find the number of occurances of a particular value in the table. Since there are no indees on t3 this will be a table scan and it will read lots of pages into the buffer pool.
So let’s look at the costing output for each of the elements of this query.

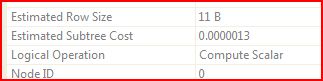
Above is the plan for the base query (select dbo.f3(2)). It emits a dummy row from a constant table and then does a “compute scalar” operation to run the function and generate a 1 row, 1 column result.
That cost doesn’t look so big…
Now let’s look at the plan for the scalar subquery (well, the top of it since we’re looking for the total cost)
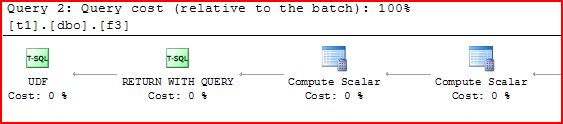

Well, the laws of physics appear to be violated.
You can try whatever cost query you want in the function – unfortunately, these aren’t really costed in the SQL Server QP (at least through 2005 and what I have seen so far on the 2008 CTPs). Back when SQL Server 7 was being created, scalars were generally always cheap and they really didn’t need costs. There’s a small amount of CPU cost added in a compute scalar and that generally worked for OLTP plans. As SQL Server started being used in larger and larger scenarios, this issue started to manifest.
As SQL Server has added more features, some of them can be arbitrarily expensive and this issue can show up in plan selection as a problem. Areas where you are likely to see this are T-SQL functions, CLR functions, string functions on varchar(max) and friends, and I’m sure that there are others. However, it’s worth noting that this won’t be a problem in a lot of cases, and often workarounds are possible that may even be better design choices than doing what I’ve done in this example. I don’t recommend that you “hide” subqueries in scalar functions like this precisely because the optimizer can’t see and cost them properly, even if they are as simple as this one.
There are a few tricky problems in “fixing” this (costing the scalar functions in line with their runtime). First, this isn’t exactly the sort of thing that people are going to beat down the gates at Microsoft to get fixed. However, it is an area where the model doesn’t work right, and when a customer does hit this they are often very far into a deployment or POC and can’t exactly redesign their application easily. Second, there are actually lots of really complex things that happen with the placement of computescalars and how they are evaluated in the optimizer and execution engine. Finally, the SQL Server QP is set up to do relational transformations (A join B is equivalent to B join A, etc.), and the computation fo scalars isn’t really a true relational operation in this algebra. This makes true costing of compute scalars always something that is different than costing a join or a filter. Third, changing the costing of such a basic operator will probably impact the plan selection for basically EVERY query, as their costs will change slightly – that’s a big risk to fix a “little” bug. The last tricky bit in fixing this has to do with the way that T-SQL functions like this get exposed into the optimizer. Not all queries really have known costs a priori. The example function that I’ve given you does have a fixed cost, under some definition, but if I start putting procedural logic into the function, then the actual executed path depends on the runtime data, and that means that the cost is based on something you haven’t interpreted yet. So, there are some at least reasonable explanations as to why this issue persists to this day.
So my advice is that if you have cases where your scalar functions are undercosted and you think it impacts plan selection, then you need to contact Microsoft and let them know. I have seen some cases of this, but I think that it’s perhaps not the most common problem and that might have some impact on whether it gets addressed in the future. I *guarantee* you that the people who work there are highly skilled and passionate about solving customer issues, as I worked with them, so I suspect that if there’s enough squeaky wheels then this is something that may be addressed.
Your other option is to send me money, I guess ;).
I hope that gives you a bit of background on the issues you need to know when examining your query plans when you have expensive scalars in them.
Conor Cunningham