Blog posts in this series:
-
For the hardware setup I'm using, see this post.
-
For the baseline performance measurements for this benchmark, see this post.
-
For the increasing performance through log file IO optimization, see this post.
In the previous post in the series, I optimized the log block size to get better throughput on the transaction log, but it was very obvious that having the log file and the data file on the same RAID array is a bottleneck.
Over the last couple of weeks I've been running some tests with the log and data files on separate RAID arrays, and this post will explain what I've found.
The first thing I did was setup the systems for remote access so I can log in to them from anywhere in the world. This involved:
-
Changing the TCP/IP port that Remote Desktop listens to (KB 306759)
-
Allowing that port through Windows Firewall (having to perform this step wasn't obvious)
-
Turning on port forwarding on our Internet-facing router for that port to the right server
It's very cool being able to play with these servers from anywhere – and to show live servers-under-load during a class, as I could last week.
The previous two tests were performed using a single 2TB RAID-10 array comprised of 8 300GB 15k SCSI drives. The new array I added to the mix for this test is comprised of various numbers of 1TB 7.2k SATA drives. I tested:
-
4 drives in a RAID-10 configuration, giving 2TB
-
6 drives in a RAID-10 configuration, giving 2TB usable
-
8 drives in a RAID-10 configuration, giving 2TB usable
The volume size limit that the Dell MD3000i arrays allow is 2TB, so the 2nd and 3rd array configurations described above made use of extra spindles but with a lot of wasted space. In this set of tests I limited myself to a single data file, but coming up I'll try multiple data files which will enable more efficient usage of the available raw disk capacity.
I used the same scripts as in the previous tests, with 128 concurrent connections each inserting 4.1KB rows in batches of 10 inserts per transaction into the same table, for a total of 1/128 TB in each connection. The data file is pre-sized to 1TB. The log file is pre-sized to 250MB, with a 50MB auto-growth increment. These are invariants from the previous test (and are also something obvious that can be changed for better performance, but that's not what this set of tests was about).
I tried the following configurations:
- Log on SCSI RAID-10, data on 4-, 6-, 8-drive SATA RAID-10
- Data on SCSI RAID-10, log on 4-, 6-, 8-drive SATA RAID-10
And very interesting results they are too! In the previous set of tests, the best performance I could get was 21167 seconds for test completion, with the data and log files sharing the SCSI RAID-10 array.
Moving the log to a different array
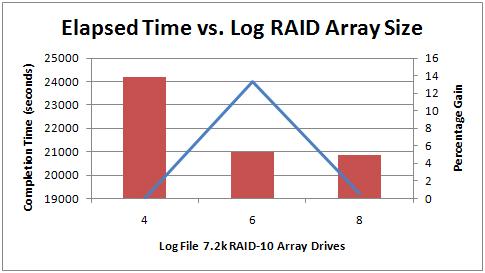
The left-hand graph above shows that moving the log file off managed to get the time down to 20842 seconds in the best case, but that's using 8 drives. The 6- and 8-drive times were basically the same – which shows that 4-drives didn't provide enough IO parallelism for the load SQL Server was pushing through the array, but moving to 6 drives provided basically enough so that 8 drives didn't lead to a big performance gain.
Overall, I'd say there was no real performance gain from moving the log file to a different array.
As far as log disk queue lengths go, when the log was on the 4-drive array, the average log write disk queue length was in the 20s. For the 6- and 8-drive cases, the queue length dropped to low single-digits. It didn't drop right down to around zero because the perfmon counter is measuring the queue length as far as Windows sees it – and the iSCSI traffic was being bottle-necked through a single NIC, as we'll see later.
For data disk queue lengths, when the log was on the 4-drive array, the average data write queue length was around 5, with spikes to 20+. For the 6- and 8-drive cases, the queue length increased to an average of 10-15, with spikes to 30+. Clearly the log drive bottle-neck in the 4-drive case was lowering the overall transaction throughput, which reduced the load on the data drives.
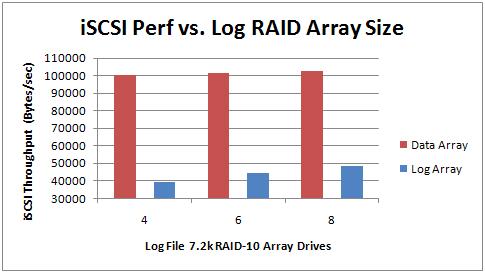
In terms of iSCSI performance, I had the MD3000is take a 2-hour snapshot of each array's performance with the varying size of the log array. The results are in the right-hand graph above. You can see that the throughput of the data array remains basically static, but the log array throughput increases with more drives thrown into the mix. Nothing stunning here.
In the 4-drive case, the transaction log grew to 5.5GB but in the 6- and 8-drive cases the log grew to over 8GB – which is what I'd expect given the higher transaction throughput.
Moving the data to a different array
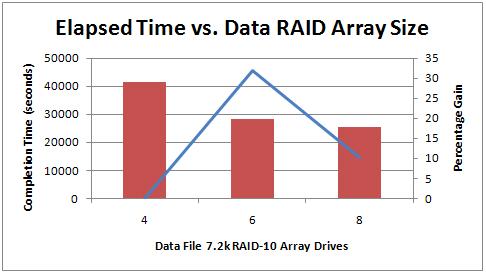
Edit 02/28/10: When performing the tests for the next post in the series, I found the results from this test didn't make sense. I went back to re-run the single-NIC tests and found what I feared – the original tests didn't complete properly. The corrected results are below.
The left-hand graph above shows that moving the data file off managed to get the time down to 25400 seconds in the best case, but that's using 8 drives. The data file's throughput requirements are clearly higher than the log file's (for this specific benchmark test, not as a general statement by *any means*). It's clear that having the data file on the slower SATA array wasn't going to lead to any better performance than having it on the SCSI array.
As far as log disk queue lengths go, they were between 1-3 in all cases, as the 8-drive SCSI array could clearly provide enough IO throughput to satisfy the log's need.
For data disk queue lengths, when the data was on the 4-drive array, the average data write queue length was around 30, with wild spikes. For the 6- and 8-drive cases, the queue length decreased to an average of 20, and then down to 10 with spikes to 30+. When there was no checkpoint or lazy writer activity, the write queue lengths dropped to zero, as I'd expect.
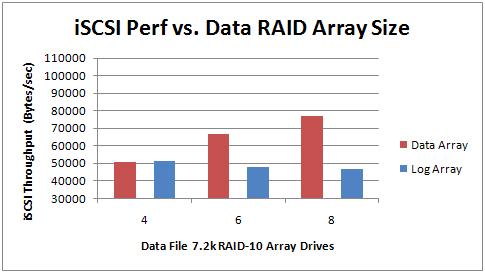
In terms of iSCSI performance, I had the MD3000is take a 2-hour snapshot of each array's performance with the varying size of the data array. The results are in the right-hand graph above. You can see that the throughput of the log array remains pretty static, but the data array throughput increases *dramatically* with more drives thrown into the mix. Again, nothing stunning here.
In the 4-drive case, the transaction log grew to 19GB but in the 6- and 8-drive cases the log grew to around 8GB – again I'd expect this. It seems that for this workload, with these default checkpoint settings, and with 8GB of server memory, the log needs to be around 8GB when there's adequate IO throughput. This is something I'll be trying to address in future tests.
Perfmon captures
I took a few perfmon snapshots during the various tests to provide some details of the system performance. I'm not going to go into as much detail explaining the various counters and what they mean, I did that in the previous post, but I will point out interesting details. These aren't necessarily meant to be representative of what you'll see running similar tests – they're of interesting times during the traces that I thought would be fun to look at and understand.
1) Log file on the 6-drive SATA array
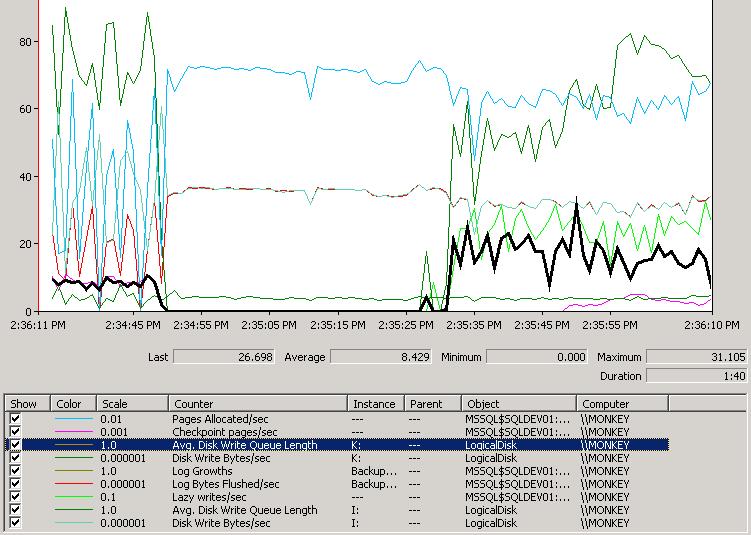
This graph is highlighting the Avg. Disk Write Queue Length for the K: data array (the black line). You can see that when the Checkpoint pages/sec (pink line) and Lazy writes/sec (light green line) both drop to zero, the write queue length drops to zero – as there's no other activity on that RAID array. When either or both of these start up again, the write queue length spikes wildly. Other things to note:
- The Avg. Disk Write Queue Length for the I: log array (the green line at the bottom) is pretty static in the low single-digits.
- The Log Bytes Flushed/sec (the red line) tracks the Disk Write Bytes/sec for the I: log array, except during the heavy checkpoint activity at the start of the trace – this is a period of log file auto-growth.
- The Pages Allocated/sec (the top light blue line) is fairly static, but varies wildly during the heavy checkpoint activity. This is because the log auto-growth is effectively stalling transaction throughput.
2) Log file on the 8-drive SATA array
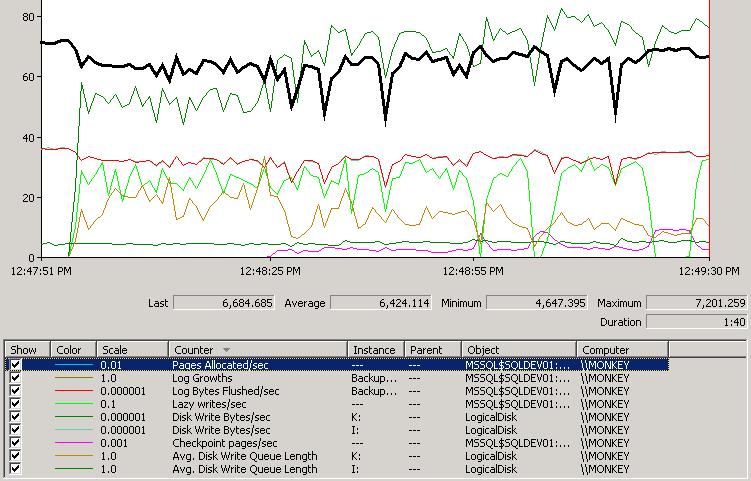
This is highlighting the Pages Allocated/sec (the black line), which remains basically static, and is a measure of the overall transaction throughput. At this point in the test, the log has auto-grown as far as it will and performance is stable. Other things to note:
- The Log Bytes Flushed/sec also remains static, as there's a constant transaction workload with no interruptions for log growth, and directly correlates with the spikes and troughs in the Pages Allocated/sec counter.
- The Avg. Disk Write Queue Length for the I: log array (the bottom green line) is static.
3) Data on the 4-drive SATA array
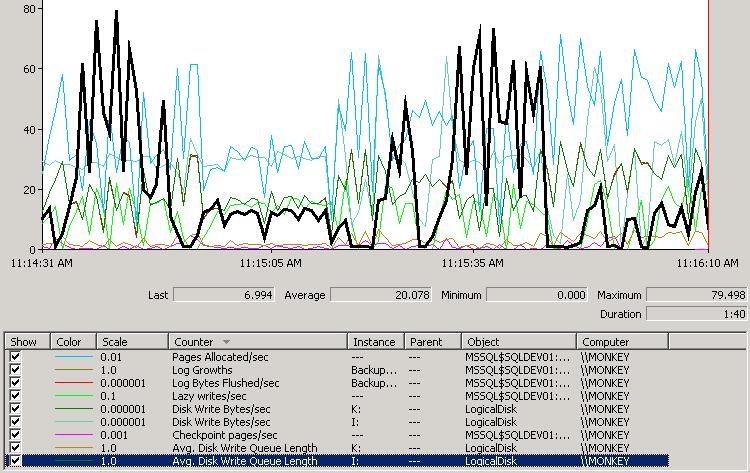
This represents the worst combination of array sizes and file placements, and is a pretty chaotic trace. It's highlighting the Avg. Disk Write Queue Length of the I: data array (the black line) and you can see that it varies wildy between 0 and 80(!!!), clearly showing that the data file performance is hampered by under-powered RAID configuration. All other perf counters around the data array vary wildly – clearly not a recipe for high performance.
Summary
There's clearly a performance gain to be had from separating the data and log portions of the database in this case. However, doing so has highlighted the fact that the simple networking configuration I have is now a bottleneck.
Here's a Task Manager trace showing the network utilization during one of the tests:

The troughs are the constant traffic going to the log array, and the sustained peaks are when there's checkpoint and/or lazy writer activity going to the data array as well.
In the next post, I'll tune the network configuration, and then I'll move on to trying multiple data files in multiple RAID arrays.
Hope you're still enjoying the series!
9 thoughts on “Benchmarking: 1-TB table population (part 3: separating data and log files)”
Hallo Paul
We encountered a similar problem with a NAS disk array connected by iSCSI. We are using the mentioned disk for backup files and not for data or log files. So, maybe this is not exactly the same situation, but in our case a change of the IP package size (iSCSI configuration) and the disk allocation size (disk format) to 64kb fixed the problem.
Sebastian
@Torsten Without looking at the in-depth drive specs, I’d guess that the SCSI drives are using TCQ and the SATAs are using NCQ – as that’s the usual tech in those drives. So – the tests are already testing the difference. I don’t believe the drives will implement both and be switchable.
@Sebastian Drives are aleady formatted with 64KB allocation unit and the RAID stripe is 128K. Next test will turn on jumbo frames to test the difference.
@Konstantin I’d prefer not to use a 3rd-party service to access to my own servers – happy tweaking things myself
Thanks!
Hi Paul,
are you using TCQ or NCQ for your storage, and did you test the difference?
I wish you a nice day,
Torsten
The MD3000/MD3000i 2TB limitation should be removed in current firmware releases.
Still learning and enjoying the series, I like the approach of just making one change and observing the effect. Higher transaction throughput causing almost 50% more log file growth was a surprise. Thanks Paul!
Paul, please keep doing the series, really good staff. BTW, will it make any difference by having log files on FAT32 instead of NTFS?
For remote access to the servers you could’ve use http://www.mesh.com that’s free and doesn’t require any firewall tweaking.
Hi Paul,
do you also keep track of what SQL Server has to say about all of this testing ? :-)
(Please also publish the sys.dm_io_virtual_file_stats and waitstats delta’s to see if there are some quick wins ?)
Regards,
Henk
Thanks Craig. Yup – I’ll be doing extensive Fusion-io tests.
Finally an in-depth performance analysis that breaks it down step by step and throws some real load at the systems.
Looking forward to the multi data file analysis.
Keep up the great work!
ps. Any plans to run the final tests using the Fusion-io SSDs?