A couple of week ago I kicked off a survey about the extent of your experience with the DBCC WRITEPAGE command. Here are the results:
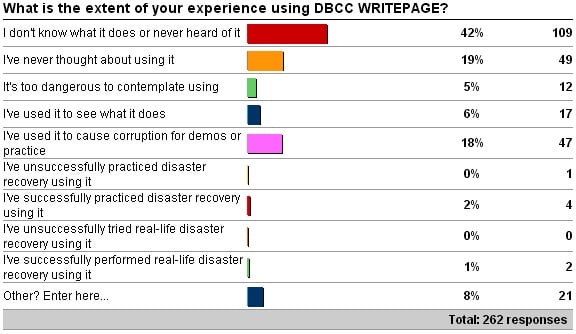
The “Other” values are:
- 9 x “Read your post on it, may practice it one day, but it’ll always be last resort to use.”
- 6 x “I read your post on it.”
- 4 x “I know about it (from your posts/immersion event) and it’s in my toolbox whenever I get called in to perform disaster recovery.”
- 1 x “It’s like knowing the Unix recursive delete command as root, dangerous and powerful.”
- 1 x “Not since 2k pages, and then PageEdit.exe was easier.”
For those of you who don’t know what DBCC WRITEPAGE is, it’s an undocumented command that allows you to make direct changes to data file pages. It’s an extremely powerful command that is very useful for creating corrupt databases, and in extreme cases, for helping to repair otherwise irretrievably-corrupt databases. I blogged about it a year ago in this post.
I never advocate using it to repair a corrupt database and then continue using that database in production, and in fact I refuse to do that if a client asks as there are just too many potential problems that could occur. I’ll only ever use it to help recover data from a damaged database, where there’s already a copy of the databases files in existence, and the client has signed an agreement acknowledging that any data file I use it on is a duplicate, is not on a production instance, and changes to it will in no way affect production.
There are all kinds of things I’ve used DBCC WRITEPAGE for to allow data recovery to progress, and in my Advanced Corruption Recovery Techniques course on Pluralsight course I demonstrate one of them, which I’m going to describe here.
Imagine a database that’s suffered corruption and there’s an off-row LOB data value that’s inaccessible because the owning data row is corrupt. Your mission is to retrieve the data. And to make it impractical to manually piece together the value using DBCC PAGE dumps, the LOB value is a few megabytes, so it’s stored on hundreds of linked text pages.
The process:
- Create another row with an off-row LOB value (the ‘dummy’ row)
- Find out the dummy row’s page and offset on the page
- Calculate the offset of the dummy LOB value’s in-row root in the variable-length portion of the record
- Calculate the offset of the dummy LOB in-row root’s size, text timestamp, and pointer fields
- Find the corrupt row’s LOB in-row-root’s size, text timestamp, and pointer field values
- Use DBCC WRITEPAGE to overwrite the dummy LOB in-row root fields
- Select from the dummy row and you’ll get back the LOB value you wanted to save
Cool, eh? Desperate times call for clever measures, and with procedures like this I regularly recover data from client databases that Microsoft and other data recovery firms either can’t help with or have given up on. It’s not a fast process as it can take quite a while to figure out exactly what to modify to make things work, but when the data comes back, the clients are always ecstatic.
And with some knowledge of the data structures in a data file, careful use of DBCC WRITEPAGE, and plenty of practice, you can do it too.
Or call us to help you :-)
4 thoughts on “Corruption recovery using DBCC WRITEPAGE”
Paul, this is so cool!!! :) I definitely will try it and practice in my local machine. Thank you so much for the post. Happy New Year!
– Tareq
Hi Paul,
Thank you very much for your articles on these DBCC commands.
We got in a pickle recently where a database had a couple of pages of it’s sysobjvalues table go corrupt. DBCC CHECKDB won’t recover it. I do have a backup for it, but unfortunately, we need some data which was added after the backup was taken. Since no schema changes had happened between the backup and now, I managed to find the exact bytes that are corrupt and put together a C# app to find out the offsets and such to automate the patching using the data from the working backup.
Unfortunately, DBCC WRITEPAGE is not actually making the changes to the DB if I choose not to bypass the buffer pool. There are no error messages when executing the command and there’s nothing in the errorlog other than the requisite notification about the changes being made. If I do the bypass, the changes are affected, but I would prefer not to do that.
This is a SQL 2014 Developer box and DB is in compatibility level 100.
Any tips would be highly appreciated.
Because you’re changing metadata tables, the changes are on disk, but not in the metadata cache in memory. You’ll need to blip the database offline and online again to have the metadata cache reflect the changes. If for some reason that doesn’t work, you’ll need to do the buffer pool bypass. Curious why you wouldn’t want to do that – no real difference.
Paul, thank you for your response.
I did end up using buffer pool bypass to fix the system table corruption. After that, corruption in the data was detected and fixed by DBCC CHECKDB.
I shall try the offline/online procedure to see if that reflects when not bypassing the buffer pool. As for why I didn’t want to do that, mostly because of your strong warnings against doing so. Logically, of course, if I fix the right bytes, the checksums will match and the corruption will be gone. You’re right. :)
Thanks again!