Last week I kicked off the first weekly survey – on whether you validate your backups or not (see here for the survey). The results are very interesting (as of 3/13/09):
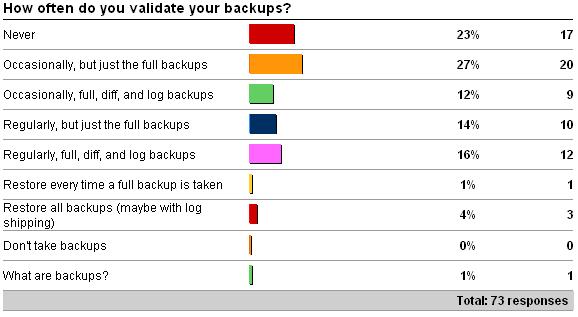
As you can see, almost 25% of respondents never validate their backups! And a further 25% only validate them occasionally, with 30% doing some kind of regular checks, and only a handful checking all the time.
While these results may seem shocking to you, based on what I’ve heard when teaching, they’re pretty normal. There are lots of reasons why DBAs may choose not to validate backups as often as they should, including:
- Not enough time to restore the backups to check them
- Not enough disk space
- Not part of the day-to-day operations guide
- Don’t see why it’s important
Kimberly and I have a saying (well, to be fair, Kimberly coined it): you don’t have a backup until you’ve restored it. You don’t know whether the backup you just took was corrupt or not and will actually work in a disaster recovery situation.
Can you ever get a guarantee? No. Here’s an analogy, taken from a very old post of mine. Consider Paul, who works for the Seattle Police Department in traffic control. Paul’s in a control room somewhere in the city with a large bank of monitors connected to various traffic cameras. Paul’s job is to cycle through the cameras every 1/2 hour, looking for traffic accidents. At the end of the 1/2 hour cycle, if Paul hasn’t seen any accidents then he knows that there are no accidents in the city.
Ah – but hold on. Does Paul really know that? No. All Paul knows is that at the point he looked at a particular camera, there was not an accident at that spot in the city. The very instant he switches to another camera feed, an accident could happen at a spot covered by the previous camera.
The same is true for validating backups. As soon as you’ve validated a backup, it could then be corrupted by the I/O subsystem, but at least you know that it was valid at some point. But what if that happens, I hear you ask? Well, then you need to have multiple copies of your backups, and you should not rely on backups as the only method of disaster recovery. A good high-availability solution includes as many technologies as you need to mitigate all risks – and backups are just one of those technologies. You’re going to have to have some kind of redundant system too that you can fall back on (or maybe even immediately failover to, depending on your particular disaster recovery plan). But, saying that, you can’t rely on the redundant server either – if it goes wrong, you’ll need your backups.
So – whichever way you look at it, validating backups is a really good practice to get into so you don’t get bitten when it comes to the crunch. When I teach, I’ve got many stories of customers losing data, business, time, and money (and DBAs losing their jobs) because the backups didn’t work or were destroyed along with the data. Here’s one for you (simplified, and no I won’t divulge names etc). Major US investment firm decides to provision new hardware, so takes a backup of the database storing all the 401-k accounts for all their customers (private and corporate), flattens the hardware, and goes to restore the backup. The backup is corrupt – on SQL 2000, where there’s no RESTORE … WITH CONTINUE_AFTER_ERROR. What happened? Well, the SQL team and Product Support had to get involved to help get the data back, but people in the firm lost their jobs and it cost a lot of time and money to recover the data. If only they’d had multiple copies of the backup, and tested their backup before removing the database (or better yet, restored the database on the new hardware before flattening the old hardware). They learned a costly lesson, but they did change their practices after that.
Unfortunately this is so often the way – people don’t realize they need to validate backups or have an HA plan UNTIL they have a disaster. Then suddenly its the top priority at the company. Being proactive can save a lot of grief, and make you look good when disaster strikes.
Backups can be unusable for a number of reasons, including:
- The full backup is corrupt, because something in the I/O subsystem corrupted it.
- A backup in the log backup chain is corrupt, meaning restore cannot continue past that point in the chain.
- All backups following a full backup are written to the same backup set, but the WITH INIT clause is used accidentally on all backups, meaning the only backup present in the backup set is the last one taken.
- An out-of-band backup was taken without using the WITH COPY_ONLY clause and the log backup chain was broken (see BACKUP WITH COPY_ONLY – how to avoid breaking the backup chain).
- The backups worked but the database contained corruption before it was backed up (kind of a separate issue).
The only ones that are out of your control are the first two, but they can be mitigated by having multiple copies of backups. All of these though, can be avoided at disaster recovery time by regularly restoring your backups as a test of what you’d do if there was a real disaster. You might be surprised what you’d find out…
This is more of an editorial style post than a deep technical or example script post – I’m going to start doing more of these around the weekly surveys. Next post – this week’s survey.
Thanks!
7 thoughts on “Importance of validating backups”
I just returned from across the pond where I had a perf gig for a country’s biggest OLTP/SSRS installation. The system was responsible for 1.3B (as in billion) USD/year in revenues. Yet the org had not only not ever executed DBCC CHECKDB, they also hadn’t even ever tested their backups.
Though I identified perf improvements which are likely to double their throughput (several disk I/O subsystem misconfigs), I consider my #1 win the fact that as of now *they have already implemented an interim solution*.
I’m going to liberate this phrase (with appropriate credit, of course): "You don’t have a backup until you’ve restored it."
Great survey. Disturbing results. Keep up the drumbeat. We all need to run with this baton. (Apologies for the mixed metaphors.)
I used to work with a guy who thought it should be called a "Recovery Plan" and not a Backup Plan. He figured that by calling it a backup plan caused people to stop at the "backup" step and not think it through to the end.
I come from the older days of SQL Server where the backup command would actually backup corruption. So you wouldn’t know that the backups were corrupt until you tried to restore it. When the building is on fire and you’re trying to restore, having a corrupt backup is the last thing you need. I always thought that was humorous – it could backup the data but refused to restore it – wrong time to find out. The checkdb and defrag operations could take 4+ hours, and the backup could take several more… and there are only so many hours in the night (24/7 shops).
One complaint my customers have is the need to have a second computer and the diskspace to do the restore on. Time and Money. Some have problems doing the cost calculation around being down after a crash – others get it. Copying a full backup of 1TB between sites is difficult – and having more data generated in a 15 minute TLog backup than can be copied across the WAN in the same time period. Some are doing it – and trying to figure out the technical details, others don’t understand the ramifications.