Back at the start of August I kicked off a survey (see here) that gave you some code to run to produce an aggregate list of the number of tables on your server with different numbers of nonclustered indexes. I got back results from more than 1000 servers across the world – a big thank you to everyone who sent me data!
It’s taken me a while to get to this post because a) I needed a few hours to set aside to aggregate the comments, txt files, and spreadsheets that people sent and load them into a database; and b) I’ve been really busy with teaching etc. Finally I’ve had time this week while at SQL Connections in Las Vegas to put together the results and this post.
The winners:
-
Highest number of nonclustered indexes on a single clustered index: 1032
-
Highest number of nonclustered indexes on a single heap: 148
-
Highest number of clustered indexes with zero nonclustered indexes on a single server: 185237
-
Highest number of heaps with zero nonclustered indexes on a single server: 88042
Wow!
Now to some of the details…
Tables with Zero Nonclustered Indexes
The two graphs below show the number of servers that have a certain number of tables with zero nonclustered indexes.
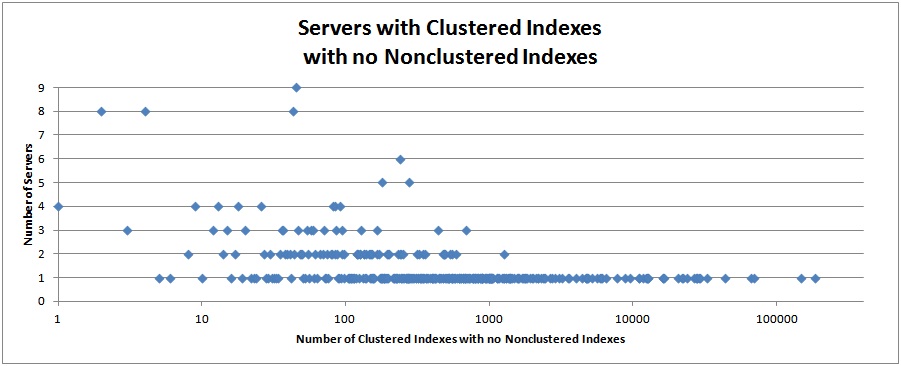
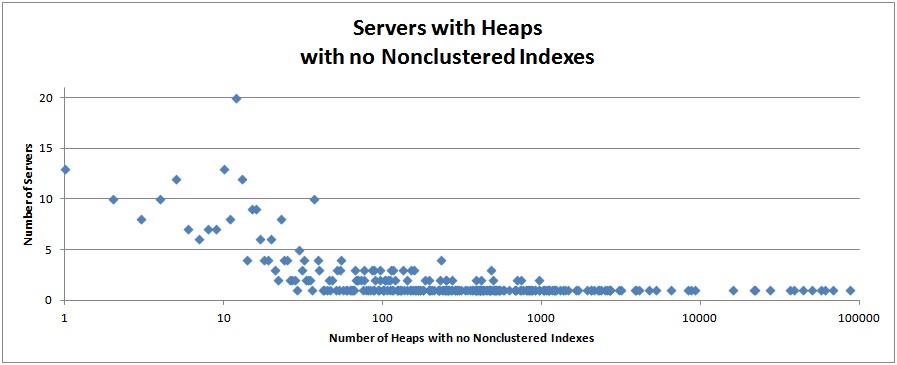
For the clustered indexes, there is one case I can think of where having zero nonclustered indexes is acceptable: if all queries return all columns of the table and the query search predicate for all queries is the cluster key (or a left-based subset of the cluster key).
All queries that have a search predicate that does not match the cluster key (or a left-based subset thereof) will be table scans, which can put pressure on the buffer pool (see my post on Page Life Expectancy) and lead to contention on the ACCESS_METHODS_DATASET_PARENT latch (all manifesting as a high percentage of LATCH_EX or PAGEIOLATCH_SH and maybe CXPACKET waits).
For the heaps, all queries are inefficient table scans. Well, efficient if you’re returning all the rows in the table every time, I suppose :-)
Bottom line: tables usually need nonclustered indexes to provide efficient access paths to the data requested by the various queries that your workload performs.
There are two things you can do to help find queries that need nonclustered indexes:
-
Use the missing index DMVs (cautiously!) to determine which nonclustered indexes to create. I use the script posted by Microsoftie Bart Duncan in his blog post. However don’t just go create all the indexes there. I generally look for Bart’s “improvement_measure” column to be above 100k before I’ll consider recommending the index to a client (and on systems that already have nonclustered indexes on the table, I’ll look for index consolidation possibilities). Note also that the missing index DMVs will sometimes add the cluster key as an INCLUDEd column. This is unnecessary but harmless.
-
Look directly in the plan cache to find query plans that perform scans. Using the graphical query plan I can see what columns are being searched for and returned from the scans and then create the correct nonclustered indexes for these.
You can also use the Database Tuning Advisor, but I don’t use that, personally.
You’ll be amazed at the performance difference by having a good set of nonclustered indexes.
But don’t go overboard otherwise you could detrimentally affect performance by having too many nonclustered indexes…
Tables with Nonclustered Indexes
The two graphs below show the number of tables that have a certain number of nonclustered indexes.
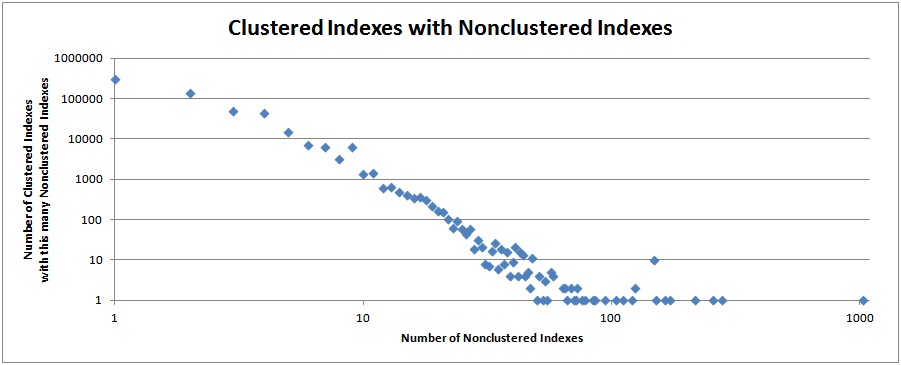
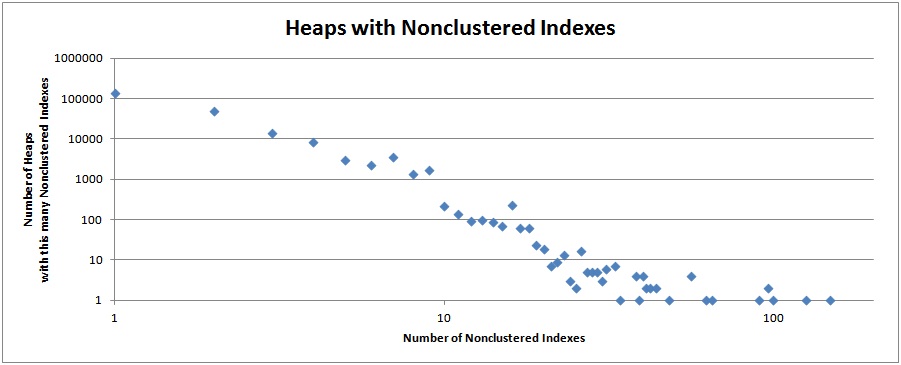
The data shows that it is most common to have 10 nonclustered indexes or less, but even that may be too many.
Every nonclustered index incurs overheard when a table row is inserted or deleted, or when any of the nonclustered index key columns (or INCLUDEd columns) are updated. Filtered indexes in SQL 2008+ are a special case, obviously. The overheard takes a few forms:
-
Buffer pool (i.e. memory and I/O) overhead of having to search the nonclustered index for the record to update.
-
I/O overhead of having to flush the updated index page to disk during the next checkpoint
-
Log space for the log records generated by the operation on the nonclustered index
-
Resource overheard for those log records in terms of:
-
Time to be read by the replication/CDC log reader Agent job
-
Time to be read by log backups (and data backups, if applicable)
-
Time and bandwidth to send the log records to a database mirroring mirror
-
Disk space to store the log records in a log backup
-
Time to restore the log records on a log shipping secondary or during a disaster recovery
-
-
Locking overhead
-
Page split overhead
-
Time to consistency check
-
Time to examine for fragmentation
-
Time to update statistics
-
Disk and backup space overhead
As you can see, nonclustered indexes can be a big burden on a system – you have to be careful when creating them so that you don’t have too many.
There are three things you can do to reduce the number of nonclustered indexes on your system:
-
Use the sys.dm_db_index_usage_stats DMV to find indexes that are only being updated. I’ve blogged about this here. Again, be careful though. Just because an index hasn’t been used doesn’t mean it should be dropped. It may be used only infrequently, but it’s critical when it is used. Ideally you need to look at the output from the DMV after an entire business cycle has passed. Even then, be careful about dropping indexes that are enforcing uniqueness constraints as these can be used by the query optimizer without reflecting any user seeks or scans.
-
Remove duplicate nonclustered indexes. Kimberly blogged code to find duplicate indexes here. There is no downside to doing this.
-
Look for consolidation possibilities. Kimberly has code to show you all the key and INCLUDEd columns here. This is harder and is more of an art than a science. You’re looking for indexes where you can combine two or more indexes into one without affecting the ability of the optimizer to use them for the various queries that the non-consolidated indexes used to help.
-
For example, an index on c1, c2, c3 INCLUDE c4, c5 can be combined with an index on c1, c2, c3 INCLUDE c4, c6. But only as long as c6 isn’t a really wide column that would affect the performance of the queries using the first index.
-
A harder example: would you consolidate an index c1, c2 INCLUDE c3 with an index on c1, c3 INCLUDE c2? Possibly. It would depend on what the indexes are being used for in queries.
-
Summary
Nonclustered indexes are essential for the performance of most workloads, but how many should you have? I often get someone in a class that Kimberly’s teaching on indexes to ask her “what’s the optimum number of indexes a table should have?” because I know it’s a nonsensical question. (And she reciprocates by getting someone to ask me “how long will CHECKDB take?” :-)
The answer is a big, fat “it depends” – and hopefully I’ve given you some pointers to figure it out for yourself.
I’ll continue this series of posts with more surveys and code that you can use on your systems to gauge the health of your indexes.
Hope this helps!
5 thoughts on “Over and under indexing – how bad is it out there?”
Nice Paul.
I would also be interested in a measure like the Highest Ratio of Non-clustered indexes to table colums on a Table/Heap.
I worked with one application that had a heap with a 2048 byte composite primary key including vardchars, XML, and GUIDs. The heap had/has 27 columns and 32 non-clustered indexes. One of the developers was convinced that SQL would "work better" if it had a separate index on each column. This might not of been a huge problem until the scalability issue popped up. At larger customer sites, the base table exceeded 1M rows and 2GB.
So this example would have an index to column ratio of about 1.2 and probably had a IndexSize to DataSize ratio of about 6 or 7.
Does your raw data support determining thess types of measures?
Hey Ray – nope – but I’m already planning a survey on this sometime in November as I’m really interested too.
Hi Paul,
"For the clustered indexes, there is one case I can think of where having zero nonclustered indexes is acceptable: if all queries return all columns of the table and the query search predicate for all queries is the cluster key (or a left-based subset of the cluster key)."
Would another valid reason be if the table was tiny? I have a number of handy reference tables which fit on 1 page. Any index will also fit on 1 page. Any query using any index will read 1 page. Will indexes help at all?
I guess so – it might save some CPU cycles if there are lots of rows on the page.
"•Highest number of nonclustered indexes on a single clustered index: 1032" – can you actually create 1032 indexes on a table/clustered index?