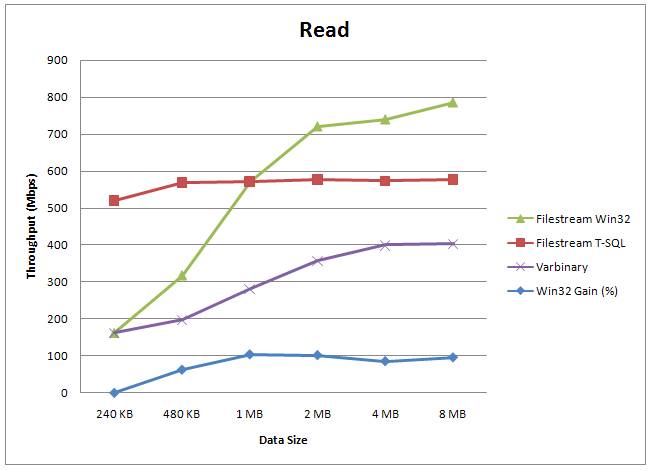
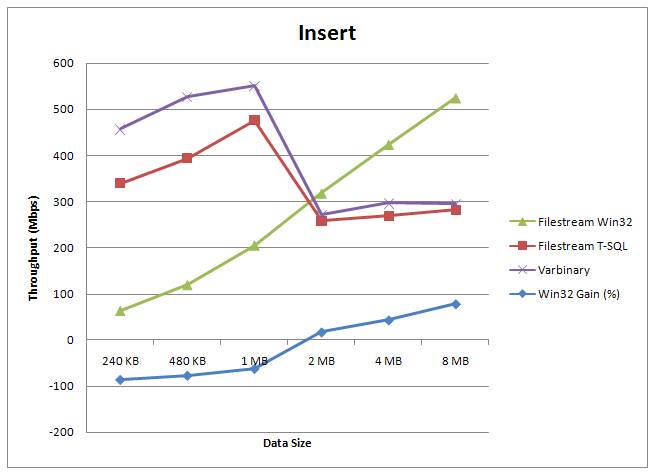
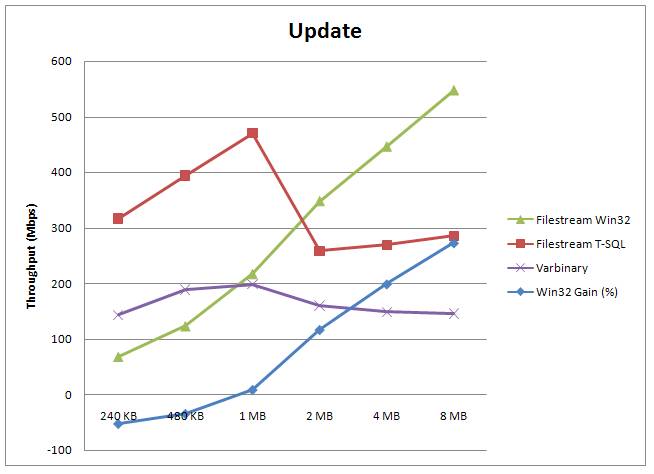
During the various courses I've been teaching, people are interested in how FILESTREAM performance compares with storing BLOBs in the database itself. I have some performance graphs based on measurements the dev team made – these have been presented publicly by myself and the dev team so I can share them with you here.
There are three graphs below, showing the relative performance for read, insert, and update of:
Check It Out!

- BLOB data stored in FILESTREAM format and accessed through the WIN32 streaming APIs. The times include getting a transaction context from SQL Server, getting the file path, doing the operation, closing the file, and committing the transaction in SQL Server.
- BLOB data stored in FILESTREAM format and manipulated through T-SQL
- BLOB data stored in varbinary(max) format (and obviously manipulated through T-SQL)
The data is the same in each test. The tests were performed on a 4-way box with a cold buffer pool. (Note that if this was for a warm-buffer pool, as the graph in the FILESTREAM whitepaper is for, the varbinary(max) and FILESTREAM T-SQL numbers would essentially swap.) One interesting point to note is that for smaller data sizes, it's faster to manipulate them through T-SQL than through the file system – this is expected based on research Jim Gray did when putting together the original TerraServer.
3 thoughts on “SQL Server 2008: FILESTREAM performance”
Hi Paul,
Could I ask you a question about FILESTREAM perfomance regarding directory management?
I have seen similar concern on the web, but do cut and dried answers.
It seems that SQL puts all files into one directory that it manages, but this could cause degradation of performance when dealing with lots of files.
This document states :
"Avoid putting a large number of files into a folder if you use programs that create, delete, open, or close files quickly or frequently. The better solution is to logically separate the files into folders to distribute the workload on multiple folders at the same time."
So, basically, I read this as meaning that over 300,000 document in FILESTREAM will start slowing the system down on reads and inserts even with disable8dot3 on if additional directories are not created.
Would you have any insight into storing potentially millions of documents in FILESTREAM.
Many thanks
Marshall
I’ve just finished a 30-page whitepaper on FILESTREAM for the SQL Server team – should be published before PASS in November. While it’s not specifically a performance whitepaper, it does spend 1/3 of the paper discussing setting up a system correctly for high-peformance. If I get time, I’ll blog some tips and tricks later this week.
Cheers
I’ve just finished a 30-page whitepaper on FILESTREAM for the SQL Server team – should be published before PASS in November. While it’s not specifically a performance whitepaper, it does spend 1/3 of the paper discussing setting up a system correctly for high-peformance. If I get time, I’ll blog some tips and tricks later this week.
Cheers