Two weeks ago I kicked off a survey that presented a scenario and asked you to vote for the log_reuse_wait_desc value you’d be most worried to see on a critical database with a 24×7 workload.
Here are the results:
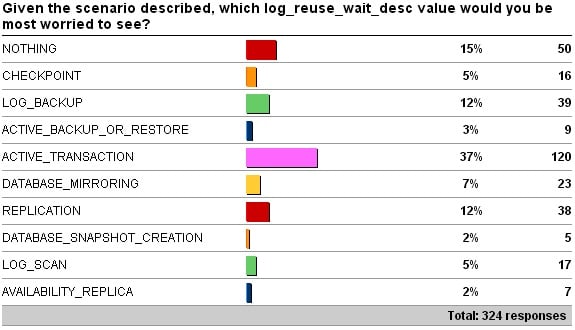
Another very interesting spread of responses – as always, thanks to everyone who took the time to respond.
Remember that you have no knowledge about anything on the system except what the log_reuse_wait_desc is for the database with constantly growing log.
Before I start discussing them, I’m going to explain the term log truncation that I’ll be using. This is one of the two terms used (the other is log clearing) to describe the mechanism that marks currently-active VLFs (virtual log files) in the log as inactive so they can be reused. When there are inactive VLFs, the log can wrap around (see this post for more details) and doesn’t have to grow. When there are no available VLFs because log truncation isn’t possible, the log has to grow. When log truncation can’t make any VLFs inactive, it records the reason why, and that’s what the log_reuse_wait_desc value in sys.databases gives us. You can read more about how the log works in the this TechNet Magazine article I wrote back in 2009, and get all the log info you could ever want in my logging and recovery Pluralsight course.
We also need to understand how the log_reuse_wait_desc reporting mechanism works. It gives the reason why log truncation couldn’t happen the last time log truncation was attempted. This can be confusing – for instance if you see ACTIVE_BACKUP_OR_RESTORE and you know there isn’t a backup or restore operation running, this just means that there was one running the last time log truncation was attempted. You can also see some weird effects – for instance if you do a log backup, and then see LOG_BACKUP immediately as the log_reuse_wait_desc value. I blogged about the reason for that phenomenon here.
Let’s quickly consider what each of the log_reuse_wait_desc values in the list above means (and this isn’t an exhaustive analysis of each one):
- NOTHING: Just as it looks, this value means that SQL Server thinks there is no problem with log truncation. In our case though, the log is clearly growing, so how could we see NOTHING? Well, for this we have to understand how the log_reuse_wait_desc reporting works. The value is reporting what stopped log truncation last time it was attempted. If the value is NOTHING, it means that at least one VLF was marked inactive the last time log truncation occurred. We could have a situation where the log has a huge number of VLFs, and there are a large number of active transactions, with each one having its LOP_BEGIN_XACT log record in successive VLFs. If each time log truncation happens, a single transaction has committed, and it only manages to clear one VLF, it could be that the speed of log truncation is just waaaay slower than the speed of log record generation, and so the log is having to grow to accommodate it. I’d use my script here to see how many active transactions there are, monitor VLFs with DBCC LOGINFO, and also track the Log Truncations and Log Growths counters for the database in the Databases perfmon object. I need to see if I can engineer this case and repeatably see NOTHING.
- CHECKPOINT: This value means that a checkpoint hasn’t occurred since the last time log truncation occurred. In the simple recovery model, log truncation only happens when a checkpoint completes, so you wouldn’t normally see this value. When it can happen is if a checkpoint is taking a long time to complete and the log has to grow while the checkpoint is still running. I’ve seen this on one client system with a very poorly performing I/O subsystem and a very large buffer pool with a lot of dirty pages that needed to be flushed when the checkpoint occurred. You could also see this if the only checkpoint in the log would be lost if the log was truncated. There must always be a complete checkpoint (marked as beginning and ending successfully) in the active portion of the log, so that crash recovery will work correctly.
- LOG_BACKUP: This is one of the most common values to see, and says that you’re in the full or bulk_logged recovery model and a log backup hasn’t occurred. In those recovery models, it’s a log backup that performs log truncation. Simple stuff. I’d check to see why log backups are not being performed (disabled Agent job or changed Agent job schedule? backup failure messages in the error log?)
- ACTIVE_BACKUP_OR_RESTORE: This means that there’s a data backup running or any kind of restore running. The log can’t be truncated during a restore, and is required for data backups so can’t be truncated there either.
- ACTIVE_TRANSACTION: This means that there is a long-running transaction that is holding all the VLFs active. The way log truncation works is that it goes to the next VLF (#Y) from the last one (#X) made inactive last time log truncation works, and looks at that. If VLF #Y can’t be made inactive, then log truncation fails and the log_reuse_wait_desc value is recorded. If a long-running transaction has its LOP_BEGIN_XACT log record in VLF #Y, then no other VLFs can be made inactive either. Even if all other VLFs after VLF #Y have nothing to do with our long-running transaction – there’s no selective active vs. inactive. You can use this script to see all the active transactions.
- DATABASE_MIRRORING: This means that the database mirroring partnership has some latency in it and there are log records on the mirroring principal that haven’t yet been sent to the mirroring mirror (called the send queue). This can happen if the mirror is configured for asynchronous operation, where transactions can commit on the principal before their log records have been sent to the mirror. It can also happen in synchronous mode, if the mirror becomes disconnected or the mirroring session is suspended. The amount of log in the send queue can be equated to the expected amount of data (or work) loss in the event of a crash of the principal.
- REPLICATION: This value shows up when there are committed transactions that haven’t yet been scanned by the transaction replication Log Reader Agent job for the purpose of sending them to the replication distributor or harvesting them for Change Data Capture (which uses the same Agent job as transaction replication). The job could have been disabled, could be broken, or could have had its SQL Agent schedule changed.
- DATABASE_SNAPSHOT_CREATION: When a database snapshot is created (either manually or automatically by DBCC CHECKDB and other commands), the database snapshot is made transactionally consistent by using the database’s log to perform crash recovery into the database snapshot. The log obviously can’t be truncated while this is happening and this value will be the result. See this blog post for a bit more info.
- LOG_SCAN: This value shows up if a long-running call to fn_dblog (see here) is under way when the log truncation is attempted, or when the log is being scanned during a checkpoint.
- AVAILABILITY_REPLICA: This is the same thing as DATABASE_MIRRORING, but for an availability group (2012 onward) instead of database mirroring.
Ok – so maybe not such a quick consideration of the various values :-) Books Online has basic information about these values here.
So which one would *I* be the most worried to see for a 24 x 7, critical database?
Let’s think about some of the worst case scenarios for each of the values:
- NOTHING: It could be the scenario I described in the list above, but that would entail a workload change having happened for me to be surprised by it. Otherwise it could be a SQL Server bug, which is unlikely.
- CHECKPOINT: For a critical, 24×7 database, I’m likely using the full recovery model, so it’s unlikely to be this one unless someone’s switched to simple without me knowing…
- LOG_BACKUP: This would mean something had happened to the log backup job so it either isn’t running or it’s failing. Worst case here would be data loss if a catastrophic failure occurred, plus the next successful log backup is likely to be very large.
- ACTIVE_BACKUP_OR_RESTORE: As the log is growing, if this value shows up then it must be a long-running data backup. Log backups can run concurrently so I’m not worried about data loss of a problem occurs.
- ACTIVE_TRANSACTION: Worst case here is that the transaction needs to be killed and then will take a long time to roll back, producing a lot more transaction log before the log stops growing.
- DATABASE_MIRRORING: Worst case here is that a crash occurs and data/work loss occurs because of the log send queue on the principal, but only if I don’t have log backups that I can restore from. So maybe we’re looking at a trade off between some potential data loss or some potential down time (to restore from backups).
- REPLICATION: The worst case here is that replication’s got itself badly messed up for some reason and has to be fully removed from the database with sp_removedbreplication, and then reconfigured again.
- DATABASE_SNAPSHOT_CREATION: The worst case here is that there are some very long running transactions that are still being crash recovered into the database snapshot and that won’t finish for a while. It’s not possible to interrupt database snapshot creation, but it won’t affect anything in the source database apart from log truncation.
- LOG_SCAN: This is very unlikely to be a problem.
- AVAILABILITY_REPLICA: Same as for database mirroring, but we may have another replica that’s up-to-date (the availability group send queue could be for one of the asynchronous replicas that is running slowly, and we have a synchronous replica that’s up-to-date.
(Edit: There’s another one that was added in SQL Server 2014: XTP_CHECKPOINT. This is where the log cannot truncate until a in-memory checkpoint occurs, which won’t happen until 1.5GB of log has been generated since the last in-memory checkpoint. In 2016, when this occurs, log_reuse_wait_desc now shows NOTHING.)
The most worrying value is going to depend on what is likely to be the biggest problem for my environment: potential data loss, reinitialization of replication, very large log backup, or lots *more* log growth from waiting for a long-running transaction to commit or roll back.
I think I’d be most worried to see ACTIVE_TRANSACTION, as it’s likely that the offending transaction will have to be killed which might generate a bunch more log, cause more log growth, and more log to be backed up, mirroring, replicated, and so on. This could also lead to disaster recovery problems too – if a long-running transaction exists and a failover occurs, the long-running transaction has to be rolled back before the database is fully available (even with fast recovery in Enterprise Edition).
So there you have it. 37% of you agreed with me. I discussed this with the team just after I posted it and we agreed on ACTIVE_TRANSACTION as the most worrying type (so I didn’t just pick this because the largest proportion of respondents did).
I’m interested to hear your thoughts on my pick and the scenario, but please don’t rant about how I’m wrong or the scenario is bogus, as there is no ‘right’ answer, just opinions based on experience.
And that’s the trick when it comes to performance troubleshooting – although it’s an art and a science, so much of how you approach it is down to your experience.
Happy troubleshooting!
21 thoughts on “What is the most worrying cause of log growth (log_reuse_wait_desc)?”
I picked active_transaction because in a lot of cases I would not be able kill the long running transaction without talking to my users to find out what they were doing. If it is outside of business hours, it might be hard/impossible to get a hold of someone, especially if it’s unclear whose running it.
With pretty much any of the other issues, there would be something I could immediately do to try to resolve the issue.
Hi Paul,
Love the post as always, I agree that would usually be the largest cause for concern but of course it depends on the environment and workload.
I do have a quick question, when you say that killing an open tran this would create more log am I right in thinking that the logging mechanism already reserves space to roll back any open transactions? Therefore any continued log growth would purely be from ongoing transactions? I thought SQL Server was always very conservative with log reserve space for open trans to ensure that a rollback won’t fail?
Thanks,
Correct. It will create more log though – log records, which will have to be backed up, scanned, mirrored, etc.
Hi Paul,
In my case the tempdb log file was growning enormously and looking at this column it says ‘Active Transaction’ whereas when i run dbcc open tran it gives me no results, Is it because of the way tempdb works different than user db.
Let me know your thoughts.
Thanks
Check out my script at https://www.sqlskills.com/blogs/paul/script-open-transactions-with-text-and-plans/
Hi Paul,
Great post
I do have a quick question for you
So when I checked
log_reuse_wait_desc =ACTIVE_TRANSACTION
log_reuse_wait =4
Then I checked for open transactions by running below and No active open transactions
https://www.sqlskills.com/blogs/paul/script-open-transactions-with-text-and-plans/
whats this mean?
It means that log clearing hasn’t been attempted since the transaction ended. Remember that the reason given is what stopped log clearing last time it was attempted.
Thanks Paul
I believe SQL Server has Automatic Checkpoint which is controlled by recovery interval (min) setting in 2008 .
but why I still see ACTIVE_TRANSACTION when I checked after few hours?
Not exactly related, but I was told that if database has two (or more) log files, then it can happen that MS SQL Server grows one of them despite that there are free (unused) VLFs in the other. How/why can this be?
Yes, if the inactive VLFs are not at the start of either log file, one of them will have to grow when end of the second file is reached when writing to the log.
Thanks for your reply. But I still don’t understand how “inactive VLFs not at the start of either log file” appear. :(
Can you provide an example?
And why, if where is unused VLFs somewhere, MS SQL Server chooses to grow log (expensive) instead of reusing them (should be relatively cheap)?
See my blog post on the circular nature of the log for an example.
Because that’s the way the log management works. If the unused VLFs aren’t at the start of the log, it won’t search through the log looking for unused ones. May not seem like an issue for a log with 50 VLFs, but what about with 5000? Makes searching for LSNs and following the VLF sequence number chain much more expensive.
OK, I’ve read it. Thanks a lot!
Hi, I have DB stuck in log_reuse = REPLICATION in SQL 2014. This was a DB migrated from 2008 R2 which looks like had a publication. But not used in 2014. Replication is not even installed in new server.
Have tried: sp_removedbreplication, sp_replicationdboption with ignore_distributor and even tried sp_dropdistributor (wishful..)
Have run:
select name, object_name(id) from syscolumns where name = ‘msrepl_tran_version’
SELECT * FROM sysobjects where replinfo > 0
ALL return zero rows but log_reuse = REPLICATION is still REPLICATION
CDC is not enabled in DB.
Any suggestions on a reason why won’t change and allow shrink. Some online articles suggest changing to SIMPLE recovery to resolve but Its a big production DB setup in logshipping so that would all need re-created.
My thoughts are might have to install replication, configure distributor and publish an article then drop it all.
Yup – if it’s not CDC causing the problem, I think that’s your best bet.
I have a database about 300 G, after re-indexing, the log file grow to over a 100G, with a 64 M VLF size, I end up with 1500 VLFs. so I tried shrinking the database after re-indexing and set the VLF size 16 M, then grow it before re-indexing with a VLF size 512 M. After I did that, the log shipping is dramatically slower (from 2 mins to 50 mins). Can that change in the log file be the reason for the log-shipping slowness??
If you dramatically increased the number of VLFs with what you did, that could cause it (but I don’t think you did that). If you’re using log shipping where you restore WITH STANDBY, it’s likely that your log backup happened to run in the middle of a large rebuild, which would have to be rolled back for the STANDBY. And then the next log backup restore would have to undo all the rollback and then continue restoring. Btw, if you want to shrink the log, just shrink the log – don’t shrink the database as that causes index fragmentation.
I arrived here investigating why one database’s log file grows by 50GB per day. Reporting on recovery model shows FULL and reporting on the log re-use wait description shows “LOG_BACKUP”. When I inspect the database properties in SSMS I’m told the data file was last backed up last night but the log file was last backed up five nights ago. I have a second database with full recovery model for which the SSMS properties window informs me both the data and log files were backed up last night – and yet this database also shows LOG_BACKUP as the log re-use wait description. Why would it show this value if the database properties dialogue box shows a successful backup of the log file?
https://www.sqlskills.com/blogs/paul/why-is-log_reuse_wait_desc-saying-log_backup-after-doing-a-log-backup/
Hi Paul, I’ve read several of your blog posts on fn_dblog and am trying to find an answer to this question….Will calling fn_dblog on a server with say a 64GB buffer pool, with an active transaction that generated a 100GB logfile read the log records into the buffer pool thus potentially causing a buffer pool flush or any other contention (other than the logreusewait of log_scan)? If you have a reference to a blog post you did on fn_dblog and performance could you please link it hear?
No – it’ll reuse a buffer over and over for subsequent reads and won’t flush the buffer pool. No blog posts on performance of fn_dblog.