I’m starting a new blog category to talk about some of weird and confusing stuff I see while query tuning.
First up is the case of the unexpected Key Lookup (Clustered) in a query that looks like it should be covered. This is a follow on from the post Missing index DMVs bug that could cost your sanity…
Today I was tracking down some performance issues on a client site and came across something in a query plan that confused me for a bit. All code and screenshots below are from my simplified repro on my test machine at home.
Check It Out!

The code is using a cursor to drive a process, and the SELECT statement driving the cursor is covered by a non-clustered index.
However, the query plan for the cursor-driving statement is as below:

You can see the SELECT statement above, and you can see that the query plan is using the nonclustered index on c2 and c3 to satisfy the SELECT. So where is the Key Lookup coming from? If I hover over the Key Lookup operator, I see the details of the operator in a tool-tip:
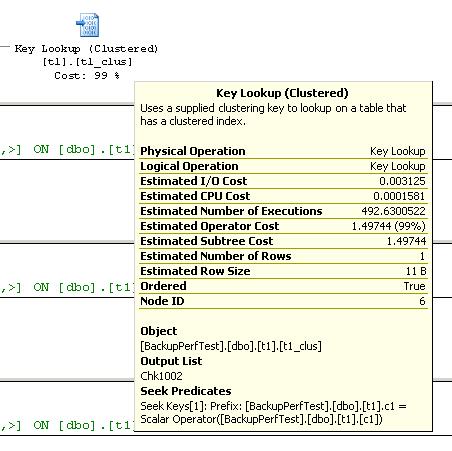
According to the details, the output list of the Key Lookup is Chk1002. What’s Chk1002? It’s not a column in my table, and it’s not a check constraint on the table either – I don’t have any. And why is it looking up the cluster key *anyway*?
This is where I turned to Kimberly to help figure out what’s going on, who said it’s to do with the cursor.
I then proceeded to work things out and got it a little twisted up. Check out the comments discussion with Brad who explained things, and it’s in Books Online too.
Because the cursor is a dynamic optimistic cursor (by default as I didn’t specify anything else) SQL Server persists a checksum of all rows picked up by the cursor-driving query in a worktable in tempdb (which, if this is a heavily executed query, can cause perf issues with tempdb). When I say FETCH NEXT, it goes back to the table to get the next value, but if I want to update a column in the row I’m working on, it recalculates the checksum to make sure that nothing has changed in that row outside the confines of my cursor. If so, my update fails – if not, it allows it.
There are plenty of ways to improve the situation (e.g. removing the cursor altogether and using a nice set-based operation… or changing the cursor type) but that’s not the point of this post. I just wanted you to be aware of this, and how the query operator properties isn’t explicit in working out what’s going on.
Enjoy!
10 thoughts on “Adventures in query tuning: unexpected key lookups”
Man, I love you guys!!
I declare cursors as LOCAL FORWARD_ONLY STATIC when I do use them (usually for maintenance or test purposes) so I usually don’t see nasty plans or performance resulting from them. However, this post makes me want to run through some dynamic cursors just to see the plans so that I might recognize them if encountered. Thanks Paul, this was a fun one!
"Behind every great man is an even greater woman."
Still true! :-)
That’s a good thing to know Paul, I never realized cursors may have such side effect. Thanks :)
Piotr
Hi Paul…
The FETCH NEXT is NOT going to a work table in this particular case… it IS getting the data directly from the T1 table…
What’s really happening here is this:
Since the CURSOR declaration did not have any keywords in it to specify what kind of cursor to use, the system used a DYNAMIC OPTIMISTIC cursor. OPTIMISTIC is the key here… whenever a row is FETCHed by the cursor, it has to do a CHECKSUM on the row data (that’s the Chk1002 and that’s why it has to do the Key Lookup into the clustered index to do the CHECKSUM on the *entire* row). It then stores the clustered index key (column c1) and the row number of the cursor (which it calls ROWID) and the Chk1002 CHECKSUM into a temporary clustered index file (called CWT_PRIMARY key in the plan). If you were to attempt to then do an update…
UPDATE T1 SET C4=’x’ WHERE CURRENT OF testcursor
…then the system would lookup the current row of the cursor (WHERE CURRENT OF) in the CWT_PRIMARY temp table, then do a lookup in the clustered index of T1 once again in order to do another CHECKSUM, and it would compare the newly-acquired CHECKSUM with the CHECKSUM that had been stored in the CWT_PRIMARY temp table to make sure they were equal and THEN it would do the UPDATE only if they were equal… otherwise if they were not equal, it would refuse to do the update.
So, in reality, the query plan IS telling you exactly what it’s doing… though the Chk1002 variable is not that self-descriptive in and on its own. The confusion comes about because we didn’t specify what kind of cursor to declare and so ended up with an OPTIMISTIC one that does all this extra CHECKSUM nonsense.
If you were to add the READ_ONLY keyword to the cursor declaration, all of that stuff with the CWT_PRIMARY temp table and the lookup into the T1’s clustered index would go away.
–Brad
Unless you specify a FOR UPDATE clause in the DECLARE CURSOR command, then it assumes that you can update ANY column in the original table (via a WHERE CURRENT OF in your UPDATE command).
However, what’s weird is that if you DO specify particular columns FOR UPDATE, like so…
DECLARE CURSOR TestCursor FOR SELECT c1 FROM t1 WHERE … FOR UPDATE OF c2;
…then it STILL does the Key Lookup to do the checksum. To be honest, that doesn’t seem to make much sense, since I now CANNOT update any column except c2:
UPDATE t1 SET c4=’x’ WHERE CURRENT OF TestCursor /* Error: Requested column to be updated not in list */
I guess the checksum is *always* done on ALL columns so that it won’t allow you to make ANY kind of change if someone else may have changed SOMETHING about the original row between the time you FETCHed the row and the time you UPDATEd it… that’s just a "feature" of the OPTIMISTIC aspect of a cursor, I suppose.
And yes, this all has to do with using WHERE CURRENT OF… if we UPDATEd t1 directly, like so:
UPDATE t1 SET c4=’x’ WHERE c1=@var;
…there’d be no problem with that at all. And, in fact, if processing needs to be sped up, that’s what one *should* do if they weren’t worried about other users changing the row.
And, of course, changing the cursor to a READ_ONLY would speed things up even more to get rid of the whole OPTIMISTIC checksum-saving stuff… in fact, as Noel indicated in his comments, a STATIC (READ_ONLY) cursor is almost always the fastest one of all, if you don’t mind the engine creating a copy of the data into a temp table when you OPEN the cursor… that’s the kind of cursor that I think Kimberly was referring to.
–Brad
Hey Brad – very interesting! So the FETCH NEXT in the cursor is using the nonclustered index to satisfy the cursor query. Why does the checksum have to be over the entire row? Surely the only thing that would break the dynamic query is if I changed c2, c3, or c1? Why would a column that’s not involved in the query need to be included in the checksum? Sure – that makes the checksum a lot easier, but it prevents the code in the cursor from changing a column in the row being processed – which the query on the client site does quite happily. Is it to do with using WHERE CURRENT OF? What if the query is using c1 directly? Thanks
Yup – that makes sense – and I did some reading up in Books Online too. Thanks
I know this is an old post, but what if you are running a set of CTEs inside a SPROC – not running a cursor – is there a more generic way to troubleshoot this?
Sorry – not my specialty so I don’t know. Try posting on a forum or send me an email and copy Jonathan.