This is a question that came up today on Twitter, and is actually something I’ve been meaning to blog about.
One of the biggest space hogs in tempdb can be DBCC CHECKDB. It generates all kinds of information about what it’s seeing in the database (called facts) and stores them in a giant worktable. A fact may be something like ‘we read page F’ or ‘record X on page Y points to an off-row LOB column in record A of page B’ or it could be something like an entire IAM page bitmap. It is usually the case that the amount of memory required for the worktable is more than is available to store it in memory and so the worktable spills out to tempdb.
DBCC CHECKDB needs to use this fact generation method because it doesn’t read the data file pages in any kind of logical or depth-first order – it reads them in allocation order, which is the fastest way. In fact it spawns multiple threads and each thread reads a set of pages, which is why I/O performance is sucked down while it is running – its special readahead drives the I/O subsystem as hard as it can. As each thread is generating all the facts, it hands them to the query processor which sorts them by a key DBCC CHECKDB defines (page ID, object ID, index ID etc) and inserts them into the worktable.
Check It Out!

Once fact generation has finished, the query processor then gives the facts back to DBCC CHECKDB again so that it can match them up (e.g. page X points to page Y, so we better have seen page Y) – called the aggregation phase. If any mismatched or extra facts are found, that indicates a corruption and the relevant error is generated.
Here’s a picture of the process:
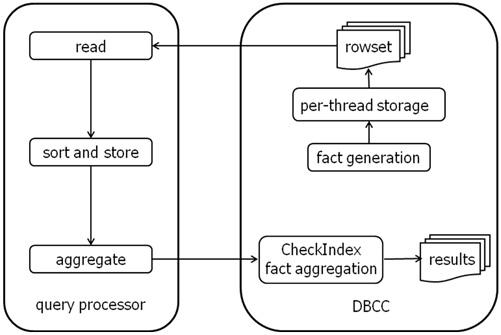
Now, because DBCC CHECKDB can use up so much tempdb space, we put in a way to ask it to estimate how much tempdb space will be required – it’s called WITH ESTIMATEONLY. The output looks something like:
Estimated TEMPDB space needed for CHECKALLOC (KB) ————————————————- 56 (1 row(s) affected) Estimated TEMPDB space needed for CHECKTABLES (KB) ————————————————– 3345 (1 row(s) affected) DBCC execution completed. If DBCC printed error messages, contact your system administrator.
This isn’t the total amount of space required to check the entire database, because DBCC CHECKDB never checks the entire database in one go (unless using the new trace flag 2562). To try to limit the amount of tempdb space required, it breaks the database down into batches. Batches are built by adding in more and more tables until one of the following limits is reached:
- There are 512 or more indexes in the batch
- The total estimate for facts for this batch is more than 32MB
The smallest possible batch is one table and all its indexes – so a very large table may easily blow the 32MB fact limit (or theoretically the 512 index limit).
The fact size estimation is calculated by looping through all partitions of all indexes for a table (remember a non-partitioned table or index is a special case of a single partition as far as SQL Server is concerned) and adding up:
- Twice the sum of all pages allocated to the partition (HoBt, LOB, and SLOB)
- Three times the number of HoBt pages in the clustered index
- Two times the number of LOB columns in the table
- Two times the number of tables rows, if a heap
- Maximum row size times the number of HoBt pages
And these totals are multiplied by the sizes of the relevant facts.
The WITH ESTIMATEONLY option runs through all the batches and spits out the largest total fact estimate from all the batches. It’s supposed to be a very conservative estimate, but certain pathological cases can trip it up as it can’t account for all possible schemas.
One more piece of knowledge I can safely page-out of my head now! :-)
PS Beware also that I’ve heard of many cases of a bug in SQL Server 2008 R2 and 2012 where the output is incorrectly very low. The dev team is aware of this issue and are working on it. It’s working again in 2014 (I’d also heard it was working in 2012 SP2 but anecdotal evidence says it’s not).
45 thoughts on “How does DBCC CHECKDB WITH ESTIMATEONLY work?”
Thanks for posting this! Pure gold!
That’s cool post. Thanks.
As always, Paul is a wealth of knowledge!
Thank’s for that.
What can we run in the SQL Azure? why can not we see results just for the tables? for each DB?
@Pini No idea – I don’t deal with Azure at all.
Hi Paul,
what about the output in SQL 2012?
CU
tosc
What about it? What’s your question?
Oh,
excuse me, I mean ” a bug in SQL Server 2008 R2 where the output is incorrectly very low” depends on 2012 too?
It looks like it’s still broken to me.
Excellent!
Does dbcc checkdb read in allocation order only pages for tables and indexes within its current batch (with tf2562 resulting in a single batch for the database)? That would seem to yield the least page reads when 512 or more tables/indexes in a database and some fragmentation present. Also seems to make sense for code reuse in conjunction with dbcc checktable.
Thanks!
Yes – always in allocation order.
It seems interleaving of index contents that aren’t part of the current dbcc checkdb batch can lead to less efficient operations for dbcc checkdb, particularly on RAID5 hard drives. Something else for me to think about as I consider the most appropriate way to evaluate and handle index fragmentation on the systems I work with.
You mean because it will have to do smaller I/Os because of interleaved extents from other tables/indexes? That will always happen unless you carefully rebuild each index with MAXDOP 1 and never add more data to them (i.e. producing giant contiguous runs of extents for a single index) – very impractical.
I’m not too concerned about the size of dbcc checkdb reads. Moreso how much of the database file each batch of dbcc checkdb will seek over to retrieve extents/pages.
If all tables and indexes of a single-file database fit within one dbcc checkdb batch, every extent and every page could be read and the fact tables built in one pass more or less straight through the database file.
If a database instead requires 50 batches to complete dbcc checkdb, there’s a high chance that many of the batches will seek over most of the database file retrieving extents/pages for the batch.
If the database storage is RAID 10 hard drives with a read only workload while dbcc checkdb runs, one side of the mirrored pair can service checkdb reads while the other services “user” requests. For RAID5 HDD the dbcc checkdb reads will block other read activity due to disk head movement on the only disk that can satisfy the read when there is no mirror.
Even though the tempdb load may be significant with trace flag 2562, it may be more important for dbcc checkdb to be a better neighbor by finishing quickly in the smallest number of passes through the file.
In my case, there is a possibility that lots of small tables might be combined. This could yield a smaller number of batches for the default checkdb.
Yup – that’s why the entire workload (including maintenance) needs to be considered when designing the I/O subsystem.
Paul: Here if i remove fragmentation, will it be faster as less space to check.
No – that won’t make a big difference, it doesn’t work like that.
Hi Paul,
I have almost 1 TB database TempDB allocated 1gb for file and 500mb for log. When I ran DBCC checkDB on Prod server the tempdb started filling upto 98% within 10 min.
I ran DBCC CHECKDB (‘DBname’) WITH ESTIMATEONLY it gave me around 500+ mb space.
Now my question is can I allocate TempDB size to 100GB (100 times more) and Logfile to 25GB and don’t worry anymore?
If I do that will there be delay when the sql starts?
What’s the best things to do? please suggest.
That’s a really tiny tempdb (gut feel) for such a large prod database. You’ll need to see how large tempdb grows to when running DBCC CHECKDB – that’s the minimum size it’ll need to be. Tempdb size doesn’t influence start up delay.
Hi Paul,
Another very interesting blog post.
In relation to SQL Server 2012 you say “It also seems to be broken in SQL Server 2012.”
I am running SQL 2012 SP2 Enterprise Edition and when running ESTIMATEONLY it appears to be performing the full CheckDB checks – do you know if Microsoft are looking at fixing this? I am struggling to find any official word from Microsoft detailing this bug.
DBCC results for ‘DatabaseA’
Estimated TEMPDB space (in KB) needed for CHECKDB on database DatabaseA = 1396.
CHECKDB found 0 allocation errors and 0 consistency errors in database ‘DatabaseA’.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Many Thanks
David
It’s working on 2012 SP2 and the message is just an artifact of how they fixed it – it’s not actually running the checks (I verified on a large database).
I’ve got 2012 sp2.
for a database that is almost 2TB it says it needs 21 kb. :)
Microsoft SQL Server 2012 – 11.0.5058.0 (X64)
May 14 2014 18:34:29
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.3 (Build 9600: ) (Hypervisor)
DBCC results for ‘sharepoint big db’.
Estimated TEMPDB space (in KB) needed for CHECKDB on database ‘sharepoint big db’ = 21.
CHECKDB found 0 allocation errors and 0 consistency errors in database ‘sharepoint big db’.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
I’m finding out the exact build number it’s fixed in – was told ‘SP2’.
Now I’m being told 2014 RTM.
SQL Server 2012 SP2 Standard Edition. ESTIMATEONLY returns 1. The database is 1.2TB. I think the issue is that one table is 1.01TB since the estimate works on smaller databases. I have broken that table out and tried it separately with CHECKTABLE but it still runs out of space in tempdb (70GB). The table has one index – the primary key and it’s clustered.
DBCC results for ‘BigDB’.
Estimated TEMPDB space (in KB) needed for CHECKDB on database BigDB = 1.
CHECKDB found 0 allocation errors and 0 consistency errors in database ‘BigDB’.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Is there some “formula” that can be used to get an estimate of space needed to properly size tempdb?
I’m finding out the exact build number it’s fixed in – was told ‘SP2’.
Now I’m being told 2014 RTM.
Thanks – unfortunately moving the database is not an option. I was able to convince the business to purge some data. This just started happening 2 weeks ago so the size must have gone over a threshold. If they purge enough it may make the difference. Just need to have them do it on a regular basis.
I did enabled traceflag 2562, now the estimated for CheckAlloc is 450MB and for CheckTable is 750GB !!!. Looks like enabling trace flag 2562 and getting estimates is the way to go. Does the estimate including data and log file usage for tempdb?
Those numbers look way too high for me – possibly there’s a bug with TF 2562 on your version. The numbers are for data only.
Paul, we had an interesting case recently on SQL 2014. The Db size is 49GB, one of the tables in 4GB, tempdb 39GB. Checkdb is failing as it could not allocate space, doing a estimate of this 4GB table returns 56GB of tempdb requirement. There is another table which is 24GB, estimate for that table is far less, only a few GB of tempdb. Defragging the table, adding a clustered index did not change the estimate either. It looks like it is over estimating the tempdb requirement, unless a certain criteria is met, which is forcing it estimate almost 14 times the table size. Do you have any thoughts or know of any cases similar to this?
Would appreciate if you can reply, when you get a chance.
Yes, there’s definitely something wrong there. I’m checking with the dev team.
There was an issue on 2012 like this that was fixed in 2012 SP3 – are you sure it was on 2014?
Sorry, was off for few days, so couldn’t respond.
Yes, definitely it is SQL 2014 on Win 2012. We recently migrated this database from SQL 2005 to SQL 2014 and is in production. Our Microsoft DSE was looking at this issue and mentioned the same, that it was an issue in SQL 2012 but was fixed with SP3. I even tried to restore the db on to another SQL 2014 server and I still get the same skewed estimates.
Ok – cool. I checked with the dev team and they’d like you to work with Product Support (or have your DSE open a case) for them to investigate this. Thanks!
Hi Guys,
Till the issue is open. We have around 1TB database, it took more over above the size of user database size.
Once done we restart the server after that only the Tempdb size will release.
Is there anyway to maintain this, it will help.
Thanks
Udhayaganesh Pachiyappan
Apologies about commenting on an older thread, but thought this question may be relevant. We have a SQL Managed Instance in Azure where we normally run DBCC Checkdb physical only Mon-Sat, and with data purity on Sundays (using Ola Hallengren’s scripts). We recently uploaded a large DB, and the Sunday check failed due to space. Sure enough, taking the snapshot for data purity would put us over our storage allocation.
However, when I ran with ESTIMATEONLY, I got the same error, which is strange. Managed instances are SQL 2017 technology, but our uploaded DB is still in 2014 compatibility mode. Would that have an effect on ESTIMATEONLY?
Hi Gaby – no, compatibility level has nothing to do with the Storage Engine – just how some query syntax behaves. The snapshot is required always, not just for data purity. You also don’t need to specify data purity, that’s done automatically always. Thanks
Ahh thanks! I misread that…much appreciated.
Paul,
We have DB around 1 TB and from last few days DBCC CheckDB job is skipping this DB as other database is fine but no error message into he logs.
How we can troubleshoot?
We are on Sql 2008 unfortunately but we have similar version in Production and it’s running fine.
Run the job SQL manually and see what messages you get from the DBCC command.
hi Paul,
hope you are doing well in these uncertain times.
I’ve run in to an issue with my DBCC checkDB on a database which is about 3TB. Largest table is around 1.1TB with 500GB data and 600GB indexes.SQL server is running this version:
SQL Server 2016 (SP2-CU3) (KB4458871) – 13.0.5216.0 EE.
The DB is part of an AG.
I get this error; 140745327312896′ in database ‘tempdb’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files
If I run DBCC checkDB ( dbname) with ESTIMATEONLY still get a large estimate as well.
Estimated TEMPDB space (in KB) needed for CHECKDB on database OTCS_PRD = 1965209359.
Any idea what I should do to resolve this?
thanks
No choice I’m afraid – you need to make tempdb bigger so it can check that table. Then you might consider partitioning the database for easier checks, restores, and so on.
thanks Paul :-) it’s a 3rd party application.
I can’t do much myself
Hi Paul
forgot to mention that this job did successfully completed 4 weeks ago and even then the tempDB was no bigger than 100GB. and certainly the largest table did not have large data increase over this 4 weeks – could that be something internal?
Date 3/14/2020 5:11:56 AM
Message
DBCC CHECKDB (dbname) WITH maxdop = 8 executed by mlcl\svc-XXXX-p found 0 errors and repaired 0 errors. Elapsed time: 2 hours 11 minutes 55 seconds. Internal database snapshot has split point LSN = 0002d609:0003e704:0004 and first LSN = 0002d603:0002b8c2:0001.