(Check out my Pluralsight online training course: SQL Server: Index Fragmentation Internals, Analysis, and Solutions.)
Back in April I kicked off a survey where I asked you all to send me some information about your buffer pools – how much memory is being used for data file pages and how much of that memory is storing empty space. I got back data from 1394 servers around the world – thanks!
The reason I’m interested in this, and you should be too, is that memory is one of the most important resources that SQL Server uses. If you don’t have enough memory, your workload will suffer because:
- You’ll be driving more read I/Os because more of the workload can’t fit in the buffer pool.
- You’ll be driving more write I/Os because the lazywriter will have to be tossing dirty pages from the buffer pool.
- You may encounter RESOURCE_SEMAPHORE waits because queries can’t get the query execution memory grants that they need.
- You may cause excessive plan recompilations if the plan cache is too constrained.
And a bunch of other things.
One of the memory problems that Kimberly discussed in depth last year (and teaches in depth in our Performance Tuning classes) is single-use plan cache bloat – where a large proportion of the plan cache is filled with single-use plans that don’t ever get used again. You can read about it in the three blog posts in her Plan Cache category, along with how to identify plan cache bloat and what you can do about it.
This post is about the memory the buffer pool is using to store data file pages, and whether good use is being made from it.
Tracking data density
The sys.dm_os_buffer_descriptors DMV gives the information stored by the buffer pool for each data file page in memory (called a BUF structure in the code). One of the things that this structure keeps track of is the free_space_in_bytes for each page. This metric is updated in real-time as changes are made to the page in memory (you can easily prove this for yourself) and so is a reliable view of the data density of the used portion of the buffer pool.
Data density? Think of this as how packed full or data, index, or LOB rows a data file page is. The more free space on the page, the lower the data density.
Low data density pages are caused by:
- Very wide data rows (e.g. a table with a 5000-byte fixed-size row will only ever fit one row per page, wasting roughly 3000 bytes per page).
- Page splits, from random inserts into full pages or updates to rows on full pages. These kind of page splits result in logical fragmentation that affects range scan performance, low data density in data/index pages, and increased transaction log overhead (see How expensive are page splits in terms of transaction log?).
- Row deletions where the space freed up by the deleted row will not be reused because of the insert pattern into the table/index.
Low data density pages can be detrimental to SQL Server performance, because the lower the density of records on the pages in a table:
- The higher the amount of disk space necessary to store the data (and back it up).
- The more I/Os are needed to read the data into memory.
- The higher the amount of buffer pool memory needed to store the extra pages in the buffer pool.
Survey results
From the survey results I took all the SQL Servers that were using at least one GB of buffer pool memory for data file page storage (900 servers) and plotted that amount of memory against the percentage of that memory that was storing free space in the data file pages.
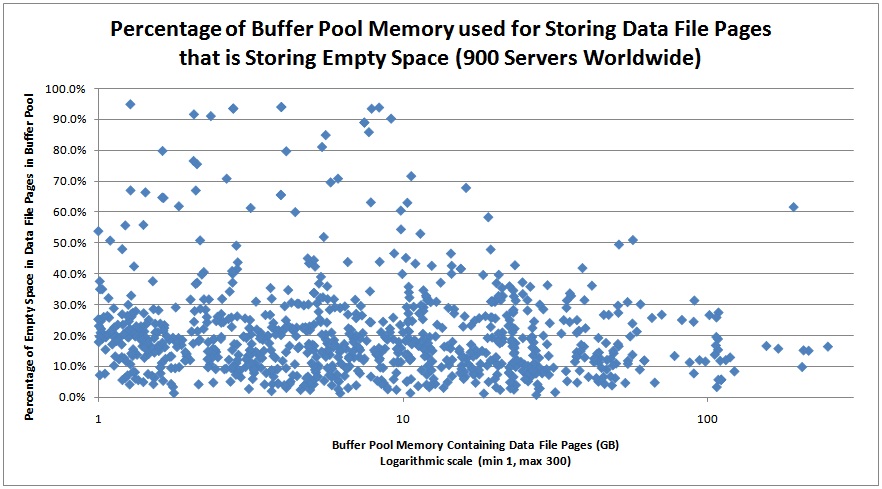
Wow! That’s a lot of servers with a lot of buffer pool memory storing nothing useful.
Low data-density solutions
So what can you do about it? There are a number of solutions to low page density including:
- Change the table schema (e.g. vertical partitioning, using smaller data types).
- Change the index key columns (usually only applicable to clustered indexes – e.g. changing the leading cluster key from a random value like a non-sequential GUID to a sequential GUID or identity column).>
- Use index FILLFACTOR to reduce page splits, and…
- Periodically rebuild problem indexes.
- Consider enabling data compression on some tables and indexes.
From the graph above, bear in mind that some of the ‘wasted’ space on these servers could be from proper index management where data and index pages have a low FILLFACTOR set to alleviate page splits. But I suspect that only accounts for a small portion of what we’re seeing in this data.
The purpose of my survey and this post is not to explain how to make all the changes to reduce the amount of free space being stored in memory, but to educate you that this is a problem. Very often PAGEIOLATCH waits are prevalent on systems because more I/O than necessary is being driven to the I/O subsystem because of things like bad plans causing table scans or low data density. If you can figure out that it’s not an I/O subsystem problem, then you as the DBA can do something about it.
Helpful code to run
Below is a script to analyze the buffer pool and break down by database the amount of space being taken up in the buffer pool and how much of that space is empty space. For systems with a 100s of GB of memory in use, this query may take a while to run:
SELECT
(CASE WHEN ([database_id] = 32767)
THEN N'Resource Database'
ELSE DB_NAME ([database_id]) END) AS [DatabaseName],
COUNT (*) * 8 / 1024 AS [MBUsed],
SUM (CAST ([free_space_in_bytes] AS BIGINT)) / (1024 * 1024) AS [MBEmpty]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id];
GO
And here’s some sample output from a client system (made anonymous, of course):
DatabaseName MBUsed MBEmpty ------------------- -------- --------- Resource Database 51 11 ProdDB 71287 9779 master 2 1 msdb 481 72 ProdDB2 106 17 model 0 0 tempdb 2226 140
Below is a script that will break things down by table and index across all databases that are using space in the buffer pool. I’m filtering out system objects plus indexes where the amount of space used in the buffer pool is less than 100MB. You can use this to identify tables and indexes that need some work on them to allow your buffer pool memory to be used more effectively by SQL Server and increase your workload performance.
EXEC sp_MSforeachdb
N'IF EXISTS (SELECT 1 FROM (SELECT DISTINCT DB_NAME ([database_id]) AS [name]
FROM sys.dm_os_buffer_descriptors) AS names WHERE [name] = ''?'')
BEGIN
USE [?]
SELECT
''?'' AS [Database],
OBJECT_NAME (p.[object_id]) AS [Object],
p.[index_id],
i.[name] AS [Index],
i.[type_desc] AS [Type],
--au.[type_desc] AS [AUType],
--DPCount AS [DirtyPageCount],
--CPCount AS [CleanPageCount],
--DPCount * 8 / 1024 AS [DirtyPageMB],
--CPCount * 8 / 1024 AS [CleanPageMB],
(DPCount + CPCount) * 8 / 1024 AS [TotalMB],
--DPFreeSpace / 1024 / 1024 AS [DirtyPageFreeSpace],
--CPFreeSpace / 1024 / 1024 AS [CleanPageFreeSpace],
([DPFreeSpace] + [CPFreeSpace]) / 1024 / 1024 AS [FreeSpaceMB],
CAST (ROUND (100.0 * (([DPFreeSpace] + [CPFreeSpace]) / 1024) / (([DPCount] + [CPCount]) * 8), 1) AS DECIMAL (4, 1)) AS [FreeSpacePC]
FROM
(SELECT
allocation_unit_id,
SUM (CASE WHEN ([is_modified] = 1)
THEN 1 ELSE 0 END) AS [DPCount],
SUM (CASE WHEN ([is_modified] = 1)
THEN 0 ELSE 1 END) AS [CPCount],
SUM (CASE WHEN ([is_modified] = 1)
THEN CAST ([free_space_in_bytes] AS BIGINT) ELSE 0 END) AS [DPFreeSpace],
SUM (CASE WHEN ([is_modified] = 1)
THEN 0 ELSE CAST ([free_space_in_bytes] AS BIGINT) END) AS [CPFreeSpace]
FROM sys.dm_os_buffer_descriptors
WHERE [database_id] = DB_ID (''?'')
GROUP BY [allocation_unit_id]) AS buffers
INNER JOIN sys.allocation_units AS au
ON au.[allocation_unit_id] = buffers.[allocation_unit_id]
INNER JOIN sys.partitions AS p
ON au.[container_id] = p.[partition_id]
INNER JOIN sys.indexes AS i
ON i.[index_id] = p.[index_id] AND p.[object_id] = i.[object_id]
WHERE p.[object_id] > 100 AND ([DPCount] + [CPCount]) > 12800 -- Taking up more than 100MB
ORDER BY [FreeSpacePC] DESC;
END';
And here’s some sample output from the same client system with the more comprehensive script:
Database Object index_id Index Type TotalMB FreeSpaceMB FreeSpacePC -------- ------ -------- ------------ ------------ ------- ----------- ----------- ProdDB TableG 1 TableG_IX_1 CLUSTERED 531 130 24.5 ProdDB TableI 1 TableI_IX_1 CLUSTERED 217 48 22.2 ProdDB TableG 2 TableG_IX_2 NONCLUSTERED 127 27 21.8 ProdDB TableC 1 TableC_IX_1 CLUSTERED 224 47 21.4 ProdDB TableD 3 TableD_IX_3 NONCLUSTERED 1932 393 20.4 ProdDB TableH 1 TableH_IX_1 CLUSTERED 162 33 20.4 ProdDB TableF 5 TableF_IX_5 NONCLUSTERED 3128 616 19.7 ProdDB TableG 9 TableG_IX_9 NONCLUSTERED 149 28 19.1 ProdDB TableO 10 TableO_IX_10 NONCLUSTERED 1003 190 19 ProdDB TableF 6 TableF_IX_6 NONCLUSTERED 3677 692 18.8 . .
This is cool because it’s a lot less intrusive way to figure out which tables and indexes have data density issues than running sys.dm_db_index_physical_stats (see this post for an in depth view of this DMV). You can mess around with the script to make it create a table to hold all the data for all databases and slice+dice however you want. I have a much more comprehensive script that I use on client systems but this one will provide you with lots of relevant data.
Have fun! Let me know if this is useful!
81 thoughts on “Performance issues from wasted buffer pool memory”
Thanks Paul. That was fun and yielded some valuable memory information about our SQL Server.
Thanks Paul. Use rebuilding Indexes.
Paul I had a question regarding that query that lists out tables and indexes in the buffer.
I have a clustered index from a table on DB1 in the buffer for DB2.
I also see the TotalMB as 3754 but the entire size of the table is only 400 MB.
How would this happen to have the buffer almost 10 times the size of the table?
@Will – not sure without looking at your system. Can you send me an email with the output?
In the second script ‘USE ?’ should be replaced by ‘USE [?]’.
Paul Using your script when I run on one of my Prod server and I seeing lots of MB free in TempDB but there are not details which index/tables consuming the memory. is there any way I can check?
Thanks.
Yes – use the sys.dm_db_task_space_usage DMV – see the whitepaper Working With Tempdb for more details.
Paul, good morning
It would be great if you could include SQLSkills logo on your blog images.
This will save time for die-hard fans (like me) who refer your work very frequently and
mention the source. Sorry if this suggestion is invalid
Thanks
Ram
Not sure I understand – you mean have the logo embedded in every blog post? That’s not practical.
Paul, Good Morning
I mean, pictures created by you and used in your blog posts.
For example, in this blog post, there is a chart (with no SQLSkills identity). It would be nice if you include “SQLSkills” as text or logo as part of the picture. guess you got what i mean.
Have a nice day :-)
Ram
Thanks Paul.
Are these statistics still relevant when a snapshot is in effect?
We snapshot pristine (defragged/stats updated prior to snapshot) baselines to begin a dev cycle. The quick reverts allow for faster dev/sqa/deployment cycles.
I see larger FreeSpaceMB when running the scripts on a fresh snapshot as compared to the original baseline.
With a snapshot you actually have other issues – because accessing a page through a snapshot creates an extra copy of the page in the buffer pool (one owned by the snapshot, one owned by the ‘real’ database). Depending on how much fragmentation causing activity there is in the real database, you could end up using more buffer pool space because the snapshot exists.
Hi Paul
Thanks for your posts. By the way, is there a way to figure out the most frequently accessed objects in memory? I cannot find any useful dmv to reveal it.
Easiest way is to create an XEvents session watching table locks in all modes being taken on objects.
Hi Paul – Second script is not working!
WordPress had mangled the code – fixed now. Assuming you figured out the simple issue too.
Great! Thanks!!
Paul,
Awesome article. I was able to clean up 720MB of wasted memory thanks to this article, bringing my Empty Space Pct down to single digits.
Thanks!
Hi Scot, “I was able to clean up 720MB of wasted memory thanks to this article, bringing my Empty Space Pct down to single digits.”
How and what did you do that to bring down Empty Space Pct?
Hi,
I used your queries and never been able to co-relate between them. I used your scripts as is copied from this website.
First query for a specific database returns 995 MBUsed and 346 MBEmpty
Second query for the same database: Sum of all TotalMB is 529 MB and Sum of all FreeSpaceMB is 320 MB.
I don’t know what am I missing and why there is so much difference in numbers.
Could you please share your theory?
Thanks!..
No idea – can you provide me with a repro?
Hi Paul,
Plz help me, how to clean space in Buffer Pool after running 2nd script (‘Below is a script that will break thing….)?
Thank you much.
You need to address the fragmentation issues that are causing low page density. There are only sledgehammer methods to freeing up space in the buffer pool – dropping all clean buffers using DBCC DROPCLEANBUFFERS or setting a database offline and then online again. Both of these are likely to cause large performance degradations in your workload as the data required is read back into memory again. Fix the fragmentation issues and the free space will sort itself out.
Thanks for quick reply sir.
Hey Paul, perhaps you could chime in on the issue this person is having with the buffer pool? He’s been using your queries and has what appears to be inexplicably high unused bytes in buffer pages: http://dba.stackexchange.com/questions/60336/empty-space-in-buffer-pool Cheers!
I’ll wait for the OP to post more data. Suspect a lot of deleted, unallocated LOB pages that haven’t been dropped from the buffer pool.
Hi Paul, Thanks for the article – still useful 3 years later! One question, what would you investigate next if you had high free space for TEXT pages?
When I ran your query I got 2 rows back, both for the same table and index. After uncommenting the other columns saw that one was for LOB_DATA (59.9%) and the other for IN_ROW_DATA(29.9%). IN_ROW_DATA I’m not so concerned about, as that likely just needs a rebuild of the clustered index. But the LOB_DATA has me a bit confused as to what to do – Unless rebuilding the clustered index would fix that too? Just thought that would be unaffected as the data is kept separately ?
Running
dm_os_buffer_descriptorsfor that DB & allocation unit I get some results which seem to say various rows are using a page but with no data? :page_type row_count free_space_in_bytes
TEXT_MIX_PAGE 1 8094
TEXT_MIX_PAGE 1 8094
TEXT_MIX_PAGE 1 3113
TEXT_MIX_PAGE 1 3337
TEXT_MIX_PAGE 1 1416
TEXT_MIX_PAGE 1 3037
TEXT_MIX_PAGE 42 1527
TEXT_MIX_PAGE 3 2907
TEXT_MIX_PAGE 3 8090
TEXT_MIX_PAGE 5 2574
These are not modified pages as well.
The table has 2 TEXT columns, ie;
[message] text NOT NULL,
[result] text NULL,
I’m just not sure what to check next, either just to figure out if it’s just some needed maintenance, or a fix to the app in how it handles text data – yes I know these should change to varchar(max) – if it’s just a case that this is an issue with TEXT fields, that’s good enough reason for me :)
Do an index reorganize and that will compact the LOB storage for the tables with low high text free space. That or export/import are your only options. The issue will still show up with new LOB types as well as the older legacy types too. Cheers
Thanks
really useful
Hi Paul,
Recently came across your blog posts and have found them extremely informative.
Was just wondering about this concept of “unused” space in pages.
In your example of a 5K per row table wasting 3K of space per page, does that mean one page correlates to one table? SQL would not use the remaining 3K on that page for some other table that does fit in the page? I guess that makes sense, otherwise the concept of a “page lock” would make no sense, right?
If that’s true, and you do have a table with “5k” sized rows (or some other odd number that results in wasted space), how would rebuilding the indexes help? It sounds like the only solution is to change the data and perhaps the structure itself to allow for more compact storage of data.
How would you go about resolving wasted buffer space, is there another blog post that gives more detail on that?
On top of that, based on my budding understanding, I imagine bad statistics or insufficient indexes greatly contribute to wasted buffer space right? If an index has sql retrieve 1000 rows and then another index is needed to complete the ‘filter’ operation and return perhaps 2 rows to the client, we end up with 1000 rows in memory when we really only needed two at the end, right?
Thanks!
A page is wholly owned by and used by a single table (or one of its indexes). There is no concept of pages being shared by tables in SQL Server.
If you have wasted space from large rows, rebuilding indexes won’t help at all – only changing the schema (or maybe using compression) will help. Rebuilding indexes (or reorganizing them) only helps in the case of logical fragmentation and wasted space caused by page splits. Lots more info in my Pluralsight course on index fragmentation that was just published a few weeks ago.
Yes, if a poor query plan is chosen because statistics are incorrect, then more space may be taken up in the buffer pool from inefficient use of indexes to get at the required data.
Thanks for the reply. I’ll try and find the Pluralsight course you mentioned.
In regards to the poor query plan, I actually ran a test myself.
If you have a case when you query a table where fieldA=@x, fieldB=@y, and fieldC=@z, and there is an index ONLY on fieldA and fieldB, what SQL will sometimes do is use that index, get the records matching fieldA=@x and fieldB=@y, then look up those records in the clustered index to get the value for fieldC and complete the where clause.
What I was able to demonstrate is that if the condition of fieldA=@x and fieldB=@y yields, say, 100k rows, and we now go to the cluster for those 100k rows and it turns out that due to fieldC=@z we cut down the 100k to 50k, it seems that the 100k will already be, and stay in, the buffer.
Therefore, due to the index not wholly supporting the query, you end up with 100k rows worth of data in the buffer even though the client gets back 50k.
Does that make any sense, or am I misunderstanding my results?
Yes, because it has to read in all the pages with the matching rows for fieldA and fieldB, and then only returns those that match fieldC. You’ll generally be better off avoiding the Key Lookup to the clustered index and having the nonclustered index INCLUDE fieldC to make it a covering index.
Hi Paul.
I’ve been using this query alot lately to find tables that are either queries inefficiently or setup to be too wide (i.e. 5K).
One thing I noticed is that while querying a large table that had a 1GB Clustered index, I noticed that this query was saying the table’s clustered index (i.e. “TYPE” was CLUSTERED) was taking up 15GB in the buffer.
How can the cluster take up 15GB in the buffer if the entire index is only 1GB? I’m getting the index size by simply right clicking the table > properties > storage, and looking at the index space number, there’s only a cluster so I imagine the 1GB it shows is talking about that.
What am I missing?
I also always wondered how the clustered index isn’t the same size as the table, if it contains the entire table, unless it’s just pointers to the actual data pages with the data which makes more sense then duplicating the data pages..
Thanks as always,
Shalom Slavin
How are you calculating 15GB? Please send me your results in email.
Also, run a sys.dm_db_index_physical_stats against the table and send those results too.
Closing the loop for anyone watching this – table is 55GB according to dm_db_index_physical_stats, so my script is correct.
Hi Paul!
A very nice article! Could I ask you one more thing? Do we have opportunity to clean up specific data from buffer(for specific tables). I know that we have command DBCC DROPCLEANBUFFERS, but this command will clean whole buffer.
Nope – only the whole thing, or for an entire database by flipping the database offline then online.
Hi Paul,
After your class in London, I started diving into this. I have used compression to reduce the size of the biggest table, and that worked very well in size (after compress, table is about 20% of its original size), but I cannot see this totally reflected in the buffer pool. The table is clearly using less buffer pool space, but it is using far more than its size. Table is about 2 GB (using SSMS > table properties > storage: data space + index space), but it is occupying 8 GB in the buffer pool?
Do you have any explanation for this or a link I can check for more info?
Thanks,
Jeroen.
Check the table size using sys.dm_db_index_physical_stats – it’s likely that SSMS is wrong/out-of-date.
Hi Paul
I am having a doubt, we are useing windows server 2012 and sql server 2012 priviously server had 32gb RAM after we have increased RAM to 64GB same as CPU six to Ten. we are using splunk to monitor server Memory utilization erlear it shows utilization of RAM is Below 30GB but after increase now it shows utilization is 50+GB by Sql server. I just want to know why it is showing like We don’t set max server and min Server memory settings.
Because SQL Server will use all the memory it’s able to for the buffer pool. This is perfectly normal. You need to set max server memory to leave some memory for the OS. See Jonathan’s blog post on memory.
We had only 5% free memory(out of 128GB) and sql server was going to crash. I restarted the sql service and now its 7% but its eating memory very fast…
It was 7% 1 hour back after restart and now its 9%.. Does anyone know why SQL server 2012 is eating memory?
We have sharepoint and sharepoint search running here.
We have 4000 running workflows item instances (7 total workflows running for 4k items) with wait in each waiting for one week.
I ran a query from below
https://www.mssqltips.com/sqlservertip/2393/determine-sql-server-memory-use-by-database-and-object/
and attached is the screenshot so tempdb and usagedb databases are taking huge buffer space. Can I shrink or limit this somehow?
SQL Server will use all memory available to it – by design.
Hi Paul,
Thanks for your posts and queries, these are really helpful.
I am having a doubt, may be you can guide me.
From the 2nd query in this post, I got to know that one particular table is having 11GB of Total Space but 95% of this table is free space. This particular table is having zero records. This server is heavily in use so I am not sure why this 11 GB is being held up and not freed.
Please note that this table is having no primary key or index. It is a SQL Server 2008R2 machine.
It’s because heaps usually can’t delete empty pages as they go along so you need to take care of it manually. Try doing an ALTER TABLE … REBUILD or just truncating the table.
Thanks a lot Paul. It did help in increasing the PLE count of the server.
Paul,
My server memory is 48 gb, almost total memory is full when i ran your query one of the table primary key using 13GB buffer memory.How can i release this memory from buffer pool.Please suggest.There is no much fragmentation on this index.
Leave it alone – if the table’s in memory that’s because it’s being used by queries.
Hi Paul, I understand you are busy with the SQL intersection this week (I attended the spring event and it was very good) and I was hoping I could get some help on a tempdb issue or point me in the right direction. Based on the overall memory usage of the databases query, my list shows tempdb as the highest (around 25G out of 75G memory server). However when I check the sys.dm_db_task_space_usage, there is no indication of any objects or sessions taking up that much of memory at the moment. Although the space is released eventually, they do raise up pretty high again. We are on SQL 2014 SP2 CU1 and did not have this issue prior to the upgrade from SQL 2008. I do notice the tempdb internal space increasing to around 4G by some of the queries and also one of the process puts around 4G of data to tempdb. But I am unable to justify where 25G of tempdb buffer cache is been allocated. We are facing memory pressure due to this every now and then. We are on SQL 2014 SP2, CU1 and using AlwaysOn. I have other systems setup similarly but tempdb does not show using more than 5G of memory. The version cleanup and generation rate looks good. Are there any known issues with tempdb memory consumption in SQL 2014? Is there anything I could do to (other than telling the developers to perhaps revisit the code) release this memory from tempdb without a restart?
Only thing I could find when searching is https://support.microsoft.com/en-us/kb/3005011 about Service Broker taking up lots of space in tempdb.
Hi Paul,
I’m wondering if there’s any downside of querying sys.dm_os_buffer_descriptors frequently? Our managed service provider queries our SQL server which has 512GB of memory every 2 mins. We noted sometimes our query can return over 2 minutes slower for the same query plan and no physical reads.
Thank you.
There shouldn’t be. But why are they querying that so frequently?
Hi Paul,
We have two servers with same configurations 256GB ram, same CPUs and SQL server 2012SP3 standard installed. But query on prod server takes bit longer than test server. There is only one database on prod server and same on test server. We refresh the test database from prod backup on weekly basis. We execute rebuild/reorganize job on the indexes on weekly basis on both the servers. All the SQL level configurations are same on both servers. But on prod server, reporting and analysis services are installed, though no one is using those services. The number of datafiles in tempdb are 8 on prod server while number of datafiles are 2 in test server. Max memory allocated to SQL server is 215GB on both servers. I made many changes on prod server and made the configuration comparable on both servers, this has improved the performance of prod server, but test server is still running faster than prod server. Normally the same operations are being performed on both the servers on daily basis. Any thing you can suggest please to improve the performance.
If they’re exactly the same hardware, with the same I/O subsystem, and exactly the same Windows and SQL Server settings, and the exact same workload, then the query should run the same. And I’m assuming the query plans are exactly the same too. Not something we can debug through the comments here, but do some wait statistics analysis and see where the extra time is being spent. Shoot me an email if you’d like some consulting help. Thanks
thank you Mr. Randal
Mr. Malek KEMMOU recommended me to follow your blogs, I confirm that they are really interesting.
I would need a clarification: the first query gives me 9 GB cached for a db, but if I remove all where condition in second query sum(TotalMB) is much smaller. There is one allocation_unit_id in sys.dm_os_buffer_descriptors that use 6 GB but not exists in sys.allocation_units.
What could it be?
I saw that this happens later an DBCC DBREINDEX or ALTER INDEX REBUILD command, but I did not understand when this big chunk of memory is released… Can you help me please?
Do you mean the space being used by the index rebuild? That’s the new index being built. The old one is deallocated after the new one is built.
Ok, but the old one still remains in the buffer pool? (sys.dm_os_buffer_descriptors with allocation_unit_id that is no longer in sys.allocation_units) Thx
Yes – until it’s deallocated by the deferred-drop background task.
Is there a way to measure active pages in the buffer pool? A kind of MB/sec for read and modified pages?
Example: I know that in the buffer page I have 10GB but I would like to know if there are only 10-100-200-X MB/sec touched for logical reads. The same thing for the written pages.
Yes – see Page Lookups/Reads/Writes in https://docs.microsoft.com/en-us/sql/relational-databases/performance-monitor/sql-server-buffer-manager-object?view=sql-server-2017
I understand that page reads-writes/sec refer to physical i/o in progress, I have not found anything that refers to logical reads-writes.
Right. So take the Page Lookups/sec and subtract Page Reads/sec and that gives you logical reads/sec.
Thx! For Page Lookups/sec I understood something different… :-)
But with eg 100 pages/sec I do not know if I read the same page or 100 different pages, thus if I touched 8KB or 800KB in RAM?
Yup – no way to do that without an Extended Event session, which will likely slow down the instance.
Why do you care?
I would like to measure the trend of the data “width” for which there is access in the buffer pool memory.
Why? It seems interesting to do it…
Hi Pall
when running
SELECT DB_NAME(database_id),
COUNT (*) * 8 / 1024 AS MBUsed
FROM sys.dm_os_buffer_descriptors
GROUP BY database_id
ORDER BY COUNT (*) * 8 / 1024 DESC
one of the databases is using 16gig of the 25 gig allocated to SQL server. It was initially 6 gig, but after I can the index rebuild it grew to 16gig. Is their any way I can free up from of the memory without having to restart SQL services?
Thanks
Dimitri
You don’t need to – the buffer pool will manage itself and reuse the memory for other pages/databases. If you *really* want to drop everything from the database out of memory, set it offline and online.
Hi, Paul!
Why the number of logical reads is more than physical read?
Even after running DBCC Dropcleanbuffers.
Could be that you didn’t run a checkpoint on the database you’re using, or one of a thousand different reasons based on the query plan.
Mr. Paul,
My server has 250 GB RAM and it’s a physical server. Max memory configured to 230 GB when ran a DMV sys.dm_os_buffer_descriptors with joining other DMV, I found a table taking almost 50 GB Buffer pool space. My question is, Is this an Issue? If so what’s the best way to tackle, if Not what happens the database will take most of the memory in the Buffer pool?
Thanks.
I don’t know :-) Do you expect that table to be taking up a lot of space in memory? It depends on your workload. Are you seeing excessive PAGEIOLATCH or RESOURCE_SEMAPHORE waits? Query plans doing table scans instead of index seeks? Without knowing your workload, it’s impossible to say whether it’s a problem or not.
Just wanted to know in the normal circumstance is it normal that a table takes almost 20% memory in the buffer pool!! By the way the PLE is very high 6000-10,000 and no PAGEIOLATCH or RESOURCE_SEMAPHORE waits.
Another word, how much is too much? 10%, 50, or 90% memory taken by a table.
Thanks
There is no answer to your question, and there’s no normal. It entirely varies by workload. You might have a database with one table and it’s all in memory, for instance. You need to understand how that table is being used by the workload and then only you can decide whether the percentage of the buffer pool it’s using make sense or not. But if you’re not seeing any of those waits, you’re not under memory pressure in the buffer pool, so it doesn’t look like a problem.
I am seeing PAGEIOLATCH. Any suggestion please?
https://www.sqlskills.com/help/waits/pageiolatch_sh/
How can bring “FreeSpacePC” down on above query?
Did you read the post? It outlines a bunch of possible solutions.