Back in November I kicked off a survey that had you run some code to get some details about your cluster keys, nonclustered indexes, and table size. I got results from more than 500 systems across the world, resulting in 97565 lines of data – thanks!
The purpose of the survey is to highlight one of the side-effects of not adhering to the general guidelines (i.e. there are exceptions to these) for choosing a clustered index key. It should be, if possible:
-
Narrow
-
Static
-
Ever-increasing
-
Unique
The survey and this post are intended to show how not adhering to Rule #1 can lead to performance problems.
Check It Out!

Both Kimberly and I have explained in the past the architecture of nonclustered indexes – where every nonclustered index row has to have a link back to the matching heap or clustered index record. The link must be a unique value as it must definitively match a single record in the heap or clustered index. For nonclustered indexes on a table with a clustered index, this link is the cluster key (or keys) as these are guaranteed to be unique. Ah, you say, but what about when the clustered index is NOT defined as unique? That’s where Rule #4 comes in. For a non-unique clustered index, there will be a hidden 4-byte column (called the uniquifier) added when necessary as a tie-breaker when multiple clustered index records have the same key values. This increases the clustered index key size by 4 bytes (the uniquifier is an integer) when needed.
But I digress. The crux of the matter is that every nonclustered index record will include the cluster keys. The wider the cluster key size is (e.g. a few natural keys), the more overhead there is in each nonclustered index record, compared to using, for instance, an integer (4-byte) or bigint (8-byte) surrogate cluster key. This can mean you’ve got the potential for saving huge amounts of space by moving to smaller clustered index keys – as we’ll see from the data I collected.
The survey code I got you to run returned:
-
Number of nonclustered indexes
-
Number of cluster keys
-
Total cluster key size
-
Number of table rows
-
Calculation of bytes used in all the nonclustered indexes to store the cluster keys in each row
I did not take into account filtered indexes in 2008, or variable length cluster key columns, as to be honest although these will make a difference, for the purposes of my discussion here (making you aware of the problem), they’re irrelevant. It also would have made the survey code much more complex for me to figure out :-)
Now let’s look at some of the results I received. To make things a little simpler, I discarded results from tables with less then ten thousand rows, and with clustered index key sizes less than 9. This dropped the number of data points from 97565 down to 22425.
The graphs below show the estimated amount off savings that could be had in GB from moving to an 8-byte bigint, plotted against the first four factors in the list above.
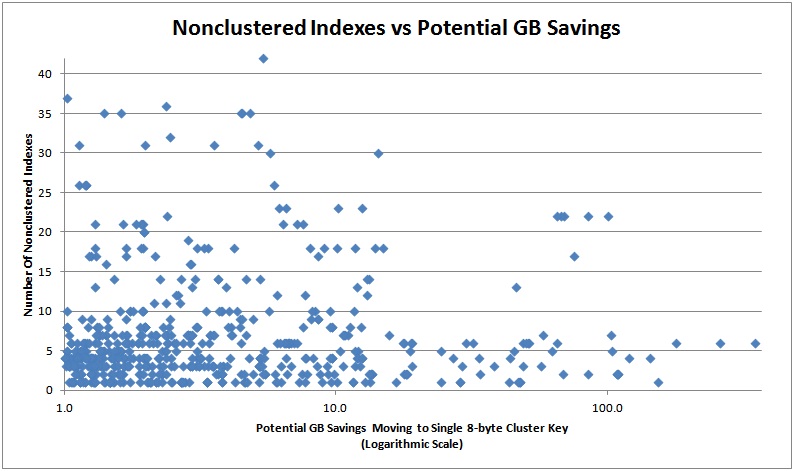
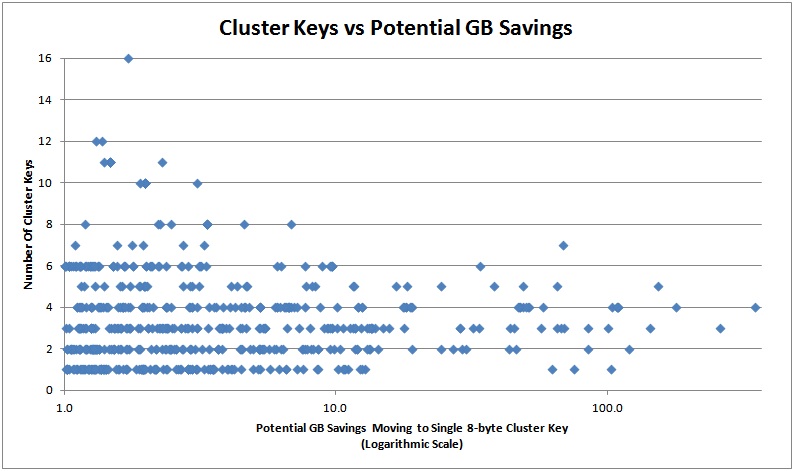
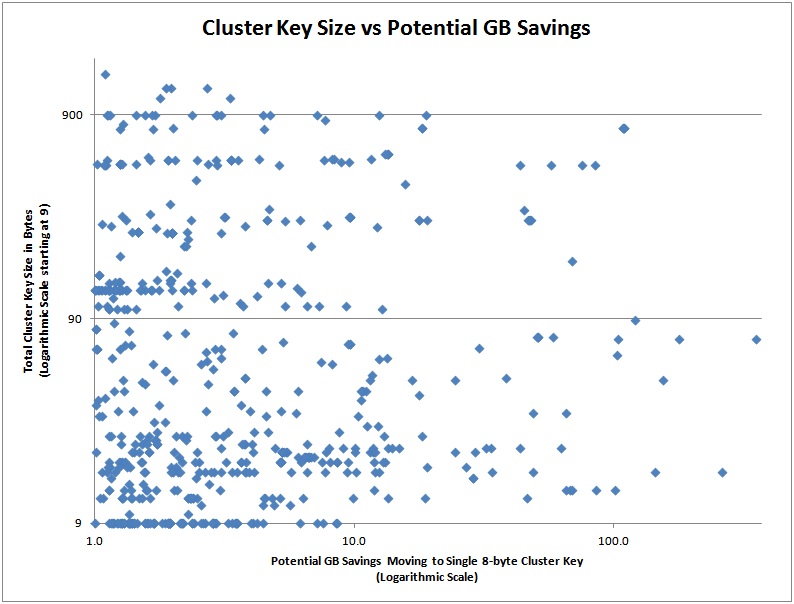
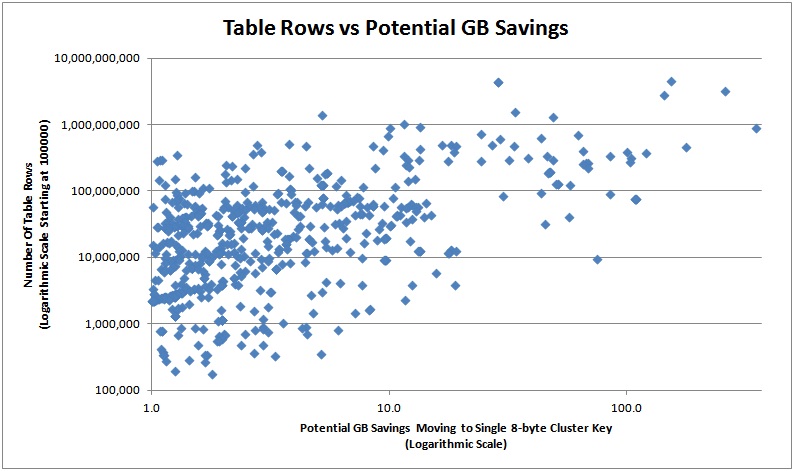
And here are the top 20 in terms of potential savings so you can see how the rough table schema:
NCIndexes ClusterKeys KeyWidth TableRows KeySpaceGB SavingsGB
——— ———– ——– ————- ———- ———
6 4 72 891,751,171 358.8 352.1
6 3 16 3,189,075,035 285.1 261.4
1 5 45 4,479,327,954 187.7 154.4
6 4 72 453,251,463 182.4 179.0
4 3 16 2,766,814,206 164.9 144.3
4 2 89 371,745,035 123.3 120.5
2 4 774 76,337,053 110.1 109.5
2 4 774 76,331,676 110.0 109.5
2 4 774 75,924,837 109.5 108.9
2 4 774 75,533,539 108.9 108.3
5 4 72 318,217,628 106.7 104.3
7 1 60 269,590,810 105.5 103.4
22 3 13 389,203,725 103.7 100.8
22 3 13 329,772,049 87.8 85.4
2 2 509 90,311,271 85.6 85.0
17 1 510 9,334,362 75.4 75.3
22 3 13 267,380,864 71.2 69.2
2 7 172 219,929,560 70.5 68.8
22 3 13 261,967,851 69.8 67.8
6 5 31 395,800,250 68.6 65.6
Wow – that’s some pretty amazing stuff – and that doesn’t even account for the space taken up by page headers etc.
You might be thinking – why do I care? There are plenty of reasons:
- If you can save tens or hundreds of GBs by changing the cluster key to something much smaller, that translates directly into a reduction in size of your backups and data file disk space requirements.
- Smaller databases mean faster backups and restores.
- Making the nonclustered indexes smaller means that index maintenance (from inserts/updates/deletes) and index fragmentation removal will be much faster and generate less transaction log.
- Making the nonclustered indexes smaller means that consistency checking will be much faster – nonclustered index checking takes 30% of the CPU usage of DBCC CHECKDB.
- Reducing the width of nonclustered index records means the density of records (number of records per nonclustered index page) increases dramatically, leading to faster index processing, more efficient buffer pool (i.e. memory) usage, and fewer I/Os as more of the indexes can fit in memory.
- Anything you can do to reduce the amount of transaction log directly affects the performance of log backups, replication, database mirroring, and log shipping.
As you can see, there are many reasons to keep the cluster key as small as possible – all directly translating into performance improvements. For those of you that think that moving to a bigint may cause you to run out of possible keys, see this blog post where I debunk that – unless you’ve got 3 million years and 150 thousand petabytes to spare…
One thing I’m not doing in this post is advocating any particular key over any other (although bigint identity does fit all the criteria from the top of the post) – except to try to keep it as small as possible. Choosing a good cluster key entails understanding the data and workload as well as the performance considerations of key size that I’ve presented here. And in some very narrow cases, not having a cluster key at all is acceptable – which means there’s 8 bytes in each nonclustered index record (just to forestall those who may want to post a comment arguing against clustered indexes in general :-)
Changing the cluster key can be tricky – Kimberly blogged a set of steps to follow plus some code to help you on our SQL Server Magazine blog back in April 2010.
Later this week I’ll blog some code that will run through your databases and spit out table names that could have significant space savings from changing the cluster key.
I won’t be blogging or tweeting much in January as we’ll be in Indonesia diving, but I will be posting photos later in the month.
Enjoy!
6 thoughts on “How cluster key size can lead to GBs of wasted space”
interesting indeed. In light of above what would you say about a theory that clustered indexes should not be unique rather they should be placed on columns that are not-so selective. this way data access speed would be increased as similar data would be packed into a smaller number of pages/extents?
Any discussion about how to choose an appropriate cluster key really needs to include an understanding of the data being indexed and the queries that will be run on them. Sometimes it makes sense to pick the cluster key based on one criteria, sometimes others – but narrowness is always desirable. I haven’t heard the theory you’re describing though.
This is some astounding results. Thanks for sharing. Have fun diving!
sometimes i end up doing the opposite but only on a case by case basis
few years ago our developers changed some code to allow multiple threads to run against a 200 million row table that had a cluster index on a bigint column that was unique. in QA testing we started seeing locks at once. some queries returned over 7 million rows and locking the entire table. I suggested changing the clustered index to another bigint column that wasn’t unique. far from it. the locks went away
query was select col1, col2, col3, col4, col5, col6, col7 where col2 = <bigint number>
original CI was on col1. changed it to col2 and the locks went away
it’s basically a batch process to create bills. select data, work on it in application, update/insert/delete data back into table. code changed to allow creation of more than one customer at a time.
i have missing indexes DMV’s running daily and sometimes change the CI to a non best practices column but only when the DMV says to create a nonclustered index with A LOT of included columns and it won’t impact other queries on the table. i’ve noticed we have some tables where the index to data ratio is 2 to 1 or so and part of the reason is complex indexes of multiple columns and included columns. Most of the problem is data in these cases. columns will have a lot of similar data like bit columns, open/closed status and similar where we end up making complex indexes to improve performance
Thanks for sharing this information. I was interested in finding out if the width of variable length columns (VARCHAR / NVARCHAR) affects performance in any way, especially when these columns are a part of the Clustering Key (for clustered indexes) or non-clustering key (for non-clustered indexes).
Our primary concern is that we may have defined some of our Index Key columns too wide (for e.g. NVARCHAR(64)) whereas the data stored in them perhaps never exceeds 10 characters. If we decide to reduce the widths of these columns from 64 to 10 in future, will we see any performance benefits at all? To put this question in another perspective, if we know that a variable length column is never going to contain more than 10 characters, does it make any difference if we define it as NVARCHAR(64) vs. defining it as NVARCHAR(10)?
No. Variable-length columns only use the amount of space required to store the data. A varchar(64) storing 10 bytes takes the same space as a varchar (10) storing 10 bytes.