A few weeks ago I kicked off a survey about tempdb configuration – see here for the survey. I received results for more than 600 systems! Here they are:
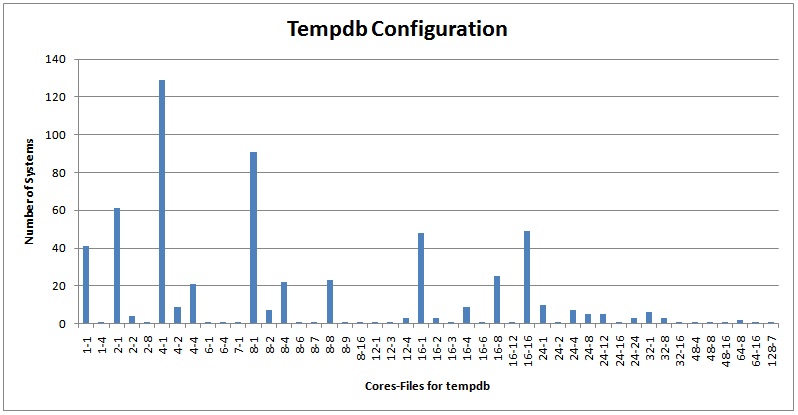
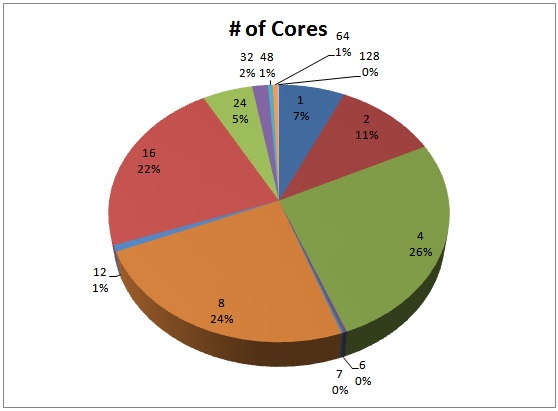
These are very interesting results, for several reasons:
-
It shows the relative distribution of core-count for SQL Servers, with a pronounced shift to 8+ cores (55%), but still with a quarter of respondents using 4-core machines – they've got a lot of life left in them.
-
It shows a result from someone with 128 cores on their server (at time of writing I didn't know what kind of machine, but the machine owner was kind enough to add a comment – it's an 8×8 with hyperthreading enabled and 2TB memory!).
- It shows that across the board, just over half of all servers are configured to have a single tempdb data file, regardless of the number of cores.
- For the 7 systems with 48 or more cores, none had a single tempdb data file.
One of the hidden causes of poor performance can be incorrect tempdb configuration. There has been a lot of info posted about tempdb, so I don't want to repeat it here, but instead give you some pointers.
Is tempdb I/O a bottleneck? Use the sys.dm_io_virtual_file_stats DMV (one of my favorites) to see the read/write latencies. Jimmy May (blog|twitter) has a great script using this DMV here that calculates per-I/O latency for all files on a SQL Server instance. If you see latencies higher than you'd expect from your I/O subsystem (say 15ms or more), then you need to take action. Adding more files or moving tempdb to a faster I/O subsystem is not necessarily the answer. It could be that you have some workload making use of tempdb that shouldn't be – e.g. a large sort or hash join operation that's spilling to tempdb, or someone using snapshot isolation in a database and causing a lot of read/write activity because of the version store. Take a look at the whitepaper Working with tempdb in SQL Server 2005. It also applies to 2008 and will show you how to diagnose tempdb performance issues. If you know what's going on with tempdb and it all looks ok, then you will have to reconfigure tempdb. This could mean adding more files to allow I/O parallelizing (just to be clear – I mean I/Os being serviced by different portions of the I/O subsystems, not multiple outstanding I/O requests from SQL Server – which happens all the time), moving to faster storage, moving away from other database files. The solution will be different for everyone, but a generalization is to separate tempdb from other databases, and sometimes separate tempdb log from tempdb data files.
Is tempdb allocation a bottleneck? This is where in-memory allocation bitmaps become a contention point with a workload that has many concurrent connections creating and dropping small temp tables. I've discussed this many time – most recently in the post A SQL Server DBA myth a day: (12/30) tempdb should always have one data file per processor core. This post has lots of links to scripts where you can see if this is a problem for you, and discusses trace flag 1118 and how to work out the cores:tempdb-data-files ratio for your situation.
Note: if you are going to add more tempdb data files, ensure that all tempdb data files are the same size. There is a known bug (which has been there forever and is in all versions) that if tempdb data files are not the same size, auto-growth will only occur on the largest file. You can work around that using trace flag 1117 (which forces all files to auto-grow at the same time) but that applies to *all* databases, just like trace flag 1118, which may not be the desired behavior.
Bottom line: you've only got one tempdb – take care of it!
10 thoughts on “Tempdb configuration survey results and advice”
I’m the guy with the 128 Cores.. It’s HP DL980 box with 8 sockets 64 Cores (128 with hyper-threading enabled) 2 TB of RAM.
I’ve got tempdb latency issues and have tried the simple things: 1 file, 2 files, 4 files, upping the drive count from 6 drives in RAID10 to 10 drives in RAID10. I even tried splitting the RAID10 array into 2 4 drive RAID10 arrays. Nothing has made a significant difference. (Positive or negative.)
I think I need to look at the process and remove some of the tempdb usage and try again. (No simple silver bullet for this.)
First stop will be the whitepaper you linked to. Thanks!
us a Solid State Drive!!!
(sorry, couldn’t resist)
The 128 core machine is most likely an eight socket server with Xeon X7560 processors, something similar to this: http://www.tpc.org/tpce/results/tpce_result_detail.asp?id=110102601
Greg,
I have considered that, but that is a fairly large ticket item, and I would have to have at least two so I could mirror them. Also, HP currently only offers 120 GB drives, and my tempDB is just slightly smaller than that, so to allow for growth I would need 4 drives (RAID10)
However I see that HP shows that in "early 2011" they are going to release new SSD drives in the 200+GB range, with a life of 3-5 years. (The current drives are listed at 3 years with constrained writes.)
So I will try to stick this on my wish list for the FY12 budget. ;)
Thanks Mark – I’ve updated the post. Nice box!
In your post, you mention "adding more files to allow I/O parallelizing" as a way to improve tempdb performance. With the exception of backup/restore and file initialization, I thought that parallel IO would occur even with a single database file because any worker thread can issue an IO request. Can you explain how adding more files affects parallel IO?
I clarified what I meant – I/Os being serviced by multiple parts of the I/O subsystem. Multiple outstanding I/Os happens all the time as I’ve discussed previously, and as you say.
Hi Paul,
I am working with a reporting database, and have monitored to capture that 8 files by 4 GB each should perfect for this workload. But the white paper seemed to be a little vague about file growth and extent size. Should I add some larger extents? or is tempdb designed to work with uniform extents?
Lannie
Not sure what you mean – you can’t change the extent size. File growth should be set equally for all data files in tempdb, and the amount depends on whether you have instant file initialization enabled.