I received a great question in email and it’s something I cover in our IEPTO1 (Immersion Event on Performance Tuning, Part 1) so I thought I’d write a post about it…
Question:
When you have a non-unique key value in a nonclustered index, SQL Server adds the RID / Row Identifier (if the NC is on a heap table) or the clustered key (if the table has a clustered index) to the navigational structure (the b-tree) of the nonclustered index to make non-unique index rows unique. What is the reason behind that implementation?Answer:
SQL Server requires the lookup value (the RID or the clustering key) to go up the tree when a nonclustered key is non-unique in order to efficiently locate rows in the leaf level.
Scenario: Take a non-unique, nonclustered index on gender (on an employee table that’s clustered by EmployeeID). To show this, I’ll create a simple tree structure with only 24 rows (12 female and 12 male employees).
Check It Out!

Note: this is NOT exactly what the index looks like but for simplicity, I’ll use this. Also, this data set is small for simplicity (you can understand this problem with a small data set); the problem is even more exaggerated for larger and larger data sets. Finally, if you’re new to index internals, consider checking out my online course here.
Possible Option 1: Only push the non-unique nonclustered key up the tree
If the leaf level is sorted only by the nonclustered key of gender then there’s no order to the EmployeeID values within each gender grouping:
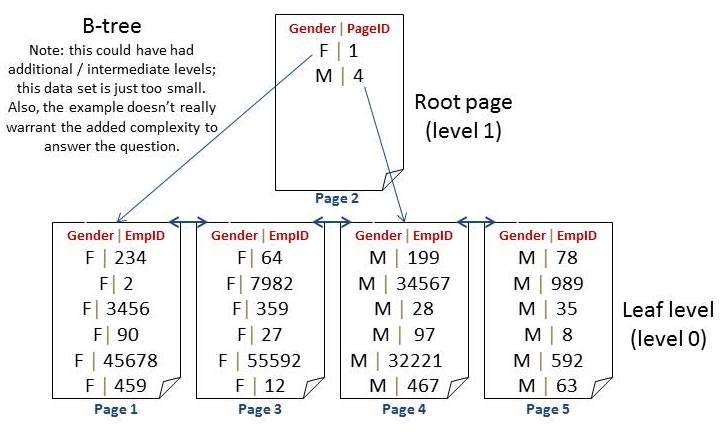
In this case, the index has very few uses. We can get a count of Female or Male employees easily but not much else is efficient. A SELECT will have to scan (from the start – every time); it can stop once the record is found (EmployeeID is unique) but the cost of always starting at page 1 (for female) or page 4 (for male) would be too expensive with many rows / pages.
Having said that though, you might even start by wondering what an index on gender would benefit anyway? The most useful requests are exactly that (counts by gender, list by gender). So, for most queries this structure could work and it really wouldn’t matter for queries. Inserts could just go to the end of each section. But, what about deletes? What if an employee were to leave? If you were to execute the following:
DELETE [Employee] WHERE [EmployeeID] = 27; GO
How would SQL Server find that row? They would know that the employee is female when they went to the data row itself. But, finding this row within the female grouping of this nonclustered index would ALWAYS require a scan through all female rows. The same would be true for an update.
So, while this could work for inserts as well as some queries, it’s horribly inefficient for updates and deletes.
Possible Option 2: Sort the leaf level but still ONLY push the non-unique nonclustered key up the tree
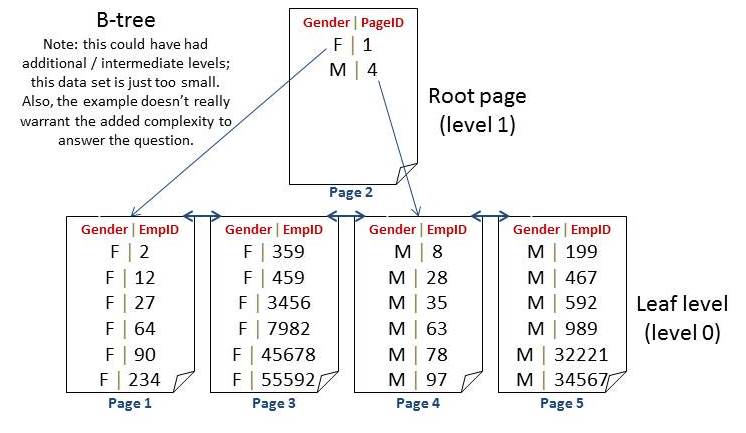
Here we don’t save much; we can still stop a scan once a value was found. But, we can do that in the structure for Option 1 (as long as EmployeeID was defined as unique). About the only added benefit of this structure is for an ORDER BY query.
SELECT [EmployeeID], [Gender] FROM [Employee] ORDER BY [Gender], [EmployeeID]; GO
For Option 1 this query would have to add an additional sort. For Option 2, we’d save this. But, we’d still have the same problem for a DELETE / UPDATE; we’d have to scan to find the specific row to modify.
So, we’re really back to the same issues as Option 1: this could work for inserts as well as even a few more queries, it’s horribly inefficient for updates and deletes.
SQL Server pushes the “lookup value” up the tree
This makes each row in a nonclustered tree unique. This makes every query directly seekable to the specific page on which that row resides. We can support queries with additional predicates (such as WHERE EmployeeID >). Again, this index doesn’t provide a lot of uses BUT it’s still MORE useful when it’s sorted AND seekable by the composite key and where that key is unique up the tree.
A delete can go directly to the leaf page.
DELETE [Employee] WHERE [EmployeeID] = 27; GO
After going to the row, we’d find that EmployeeID 27 is female. Using the root page we can see that the first pointer is for EmployeeID 2 or higher. The second pointer is for EmployeeID 59 or higher. Since we’re looking for 27 – we’d use the first pointer which points to page 1 for data.
In the same way, an update can go directly to the leaf page. An insert has a specific place to insert (yes, these can cause splits).
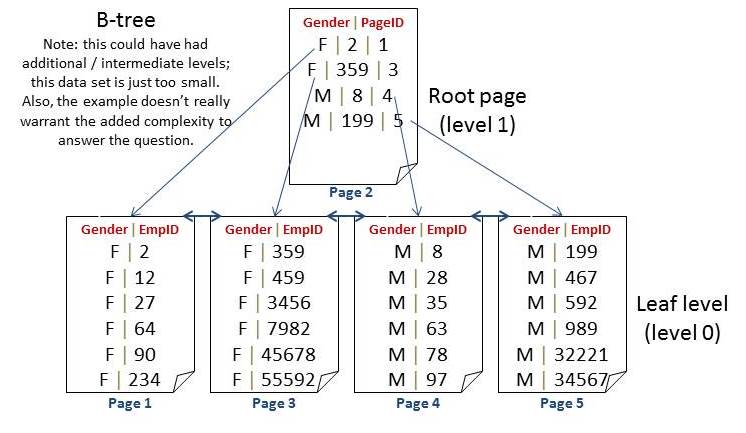
So, while I could have used a larger and more realistic example for this – this definitely shows the need for the clustering key in the b-tree portion of an index.
Have fun and keep those questions coming!
Cheers,
k
14 thoughts on “Nonclustered indexes require the “lookup” key in the b-tree when?”
Another great post. A long time ago someone asked me where I learned index analysis. I said, most of it’s from the indexing queen. :)
Thanks Mike! It’s definitely one of my favorite topics!! ;-)
kt
EmpIDs on page 1 should all be smaller than on page 3 when it is B-tree.
Right – that’s how a b-tree IS stored. The first two diagrams were “possible options” defining why a b-tree MUST have the lookup value pushed up the tree.
Not sure if this is a question or just a statement?
Cheers,
k
Thank You for reply. It tried to point out error in the third picture (probably copy&paste error), sorry if it was not obvious.
Hey there Antonin – Ha… I guess you can look at something a few times and just not see it… I didn’t notice the typo but you’re right – the first value on page 3 is supposed to be 359 and not 59. I’ve updated it in diagrams 2 and 3. Great catch – thanks!!
Cheers,
k
“This makes every query directly seekable to the specific page on which that row resides.”
What about this query?
DELETE [Employee] WHERE [EmployeeID] = 28;
GO
Which page it will go (to 1 or to 4). I believe, a single seek can’t find the appropriate row with this index?
Sorry for my delay. I’m just now wading through some comments that were buried in with a bunch of spam.
But, yes, with the correct nonclustered index – a delete is seekable to the exact page where the row resides. And, from the row in the index, we can look up the data row to find out all of the other keys needed to delete all of the other corresponding index rows and finally, delete the data row. But, yes, the index on EmployeeID is very helpful for SELECTs AND DELETEs (and UPDATES).
hth,
k
B
I am commenting on this because some of the reasoning goes against my intuition.
When talking about sorting at the leaf level you say:
Here we don’t save much; we can still stop a scan once a value was found. But, we can do that in the structure for Option 1 (as long as EmployeeID was defined as unique). About the only added benefit of this structure is for an ORDER BY query.
That assumes that the scan algorythm only scans sequentially through, having sorted the data, a binary search algorythm (as an example) would seem to me to provide a significant improvement in the speed of a scan of any individual page.
If all of the pages are in physical memory the difference between looking up the node to get the page value using the same logic we used to scan the pages counld be done in a relatively small nuber of itterations.
However if we have to load pages into memory to find the first value from each page we are scanning the load operation could be an expensive one. Now I am guessing that when this structure was devised it would have been highly likely that this was a potentially far more expensive operation than scanning the page, a clue that suggests this is that leafs map to pages one to one.
It may be on modern hardware the majority of the data could reside in physical memory and the overhead of loading page data does not arrise.
Is the answer not that loading pages is an expensive operation and storing page ids significantly reduces the number of page load operations that would need to occur?
Actually, there’s a bit more to how the records are located on the page and it has to do with the fact that rows are NOT stored in order; instead there’s a slot array that has offsets for each row. This slot array is stored at the end of the page and it can be used to help binary search and even interpolate which slot has the row requested.
The long story short though is that an ordered page has benefits as does having the lookup key when the index key is non-unique. And, you definitely don’t want to have to scan a large number of PAGEs. It’s not the record access nearly as the page access that matters here.
Hope that helps!
k