In the previous post in the series I introduced SSDs to the mix and examined the relative performance of storing a transaction log on an 8-drive 7.2k SATA array versus a 640-GB SSD configured as a 320-GB RAID-1 array. The transaction log was NOT the I/O bottleneck in the system and so my results showed only a limited 2.5%-3.5% performance gain from substituting the RAID-1 SSD.
Several people pointed out that many people use such an SSD in a RAID-0 configuration instead of RAID-1, so I promised to try the same set of tests using the SSD as a 640-GB RAID-0 array.
Now, the merits of using a single SSD in a RAID-0 configuration are mixed. If used just on its own, there's no redundancy but the performance should be better, so I'd make sure my client understood the risk involved and made sure that for critical data some form of redundancy is added (e.g. synchronous database mirroring).
I re-ran the 100-GB table population tests with the transaction log on the RAID-0 SSD to see what extra performance gain could be had. To be honest, I didn't expect much, as I know the transaction log isn't the limiting factor.
Here are the graphs for the tests. On the top is the SSD configured for RAID-1, on the bottom is the SSD configured for RAID-0. Each test was performed 5 times and the average time used for the graph.
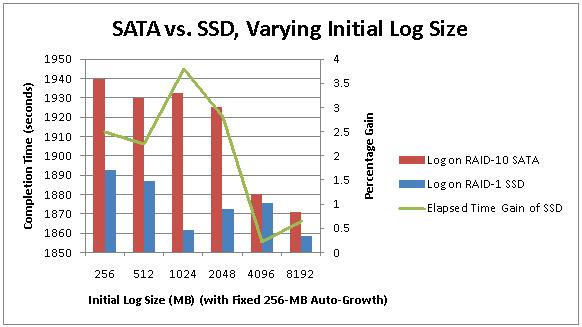
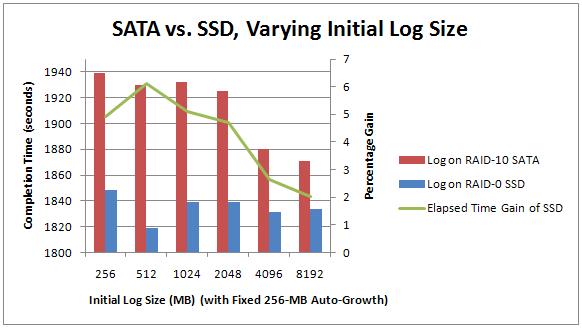
You can see that in the RAID-0 configuration, there's a higher performance gain – peaking at just over 6%.
The average perf gain for the RAID-1 SSD over the SATA array across all tests was 2.04%.
The average perf gain for the RAID-0 SSD over the SATA array across all tests was 4.25%.
Clearly the RAID-0 SSD outperformed the RAID-1 SSD (and they both outperformed the SATA array in all tests), as we'd expect, but not by much, as again, the transaction log *isn't the bottleneck*. We should see much better gains by altering the data file configuration – so that's what I'll do next.
Thanks for following the series and for all the comments. Please bear in mind that I'm taking things slowly so I won't jump straight to the best configuration – I want to analyze the changes as we go along.
PS I tried increasing the number of SQL Server connections in the test from 16 to 32 as someone suggested in a comment – the performance got 10% worse! Decreasing the number of connections didn't help either.
9 thoughts on “Benchmarking: Introducing SSDs (Part 1b: not overloaded log file array)”
It depends on the device, but I wonder if the performance varies if you keep the drive full (as full as possible). I think it is unrealistic to benchmark SSD drives that are mostly empty. The lower class of drives will likely perform worst when full, as comparison it might be useful info.
@Mike – why would it make a difference how full they are? The whole point is that the latency is uniform across the ‘surface’ of the disk. Granted there is the background process that amortizes the degradation of the flash-RAM across the disk, but I don’t think Fusion-io classes as the lower class of drives, so I’m not concerned about it.
The way SSD performs write, even if small, is to read a large section (256k?) and find an unused section to rewrite the 256k block with changes. The process of finding unused sections may be bound by available free space and the internal controllers ability to perform parallel writes to different sections (with unused space) at same time. Unfortunately the algorithms are proprietary, so its hard to know for sure. I think of it as similar to RAID and cache magic on a smaller scale. One of the easiest checks is to fill up the disk. Better class drives (Fusion-io) may maintain a large free pool on every parallel write path that are hard to fill, which helps with performance and error correction. I guess it may be possible in a benchmark test to ‘fill the unused cache’ on some drives. But, the technology changes, so my info may be outdated. HTH
Hi Paul,
You mentioned that you would change the stripe size of your platter disks to 64K. Did you do that and did it change the performance of the platter array? Also, when running the SSD in RAID 0 did you initialize the volume with a 64K stripe?
Thanks,
Sani
Paul – I’d like to recommend an article – it is a year old, and will likely take time to read but (to me) was totally worth the time. Maybe you aren’t concerned that your drives are in a "lower" class, but there are important traits about SSDs that anyone considering them should know. This article appears on the surface to be discussing a particular model of SSD, but the background explanation is what I think are really valuable. Here is the link: http://www.anandtech.com/show/2738/1 It will help shed light on why mostly filled drives perform worse than empty drives. I would just hate for you to do all your testing without knowing everything that could affect your statistics.
Then again – maybe you already know :)
Nope – didn’t change the stripe size on the platter disks yet – one change at a time!
@faamasani No. As with all my benchmarking posts, I make it very clear what changed and what didn’t. You all need to be patient for me to find the time to run these tests :-)
We have a pair of servers set up with 6 of these FIO cards in each, currently just on 1 big stripe.
Not doing anything fancy, just dumping the lot on the one stripe – tempdb, systemdbs, data and logs – man SQL2008 installs quickly when the media and install path on fusionio!
I can backup and restore locally at well over 1GB/s.
SQLIO stats are absolutely outrageous compared to SAN/DAS.
For redundancy its mirrored (synchronous), far above the BOL recommendations with no noticeable problems.
Average queries have shattering performance gains, comfortably averaging at least 10x improvement.
Really notice this for things like index rebuilds – and now really notice the various things that operate multithreaded! As long as I have enough cores to drive the ssds, tasks complete super fast. The single threaded ones are still quicker, but in comparison feel appallingly slow – when you get used to the 2008 resource monitor telling you disk activity is in GB/s with all cores maxed out, its irritating to see only 500MB/s and a single core gone loopy!
2 things to worry about – and make sure you aren’t hitting.
1. Got enough RAM – the cards themselves seem to demand a lot of memory to run.
2. Enough CPU – I found early on that 1 i920 was very easily flooded by just 2 cards in a stripe. The cards seem to send data back to the CPU faster than it can deal with it – queries that were fine on a ‘normal’ server end up flooding the cpu with the card in place – giving a repeatable 10-15 second delay in even opening a new query window… so things lock up really quickly.
Look forward to reading any more you put together on these.
Rich
Ok Rich. What did that setup cost you?