After writing the FILESTREAM whitepaper for Microsoft, I’ve had lots of questions about the structure of the FILESTREAM data container. The FILESTREAM data container is the technical term for the NTFS directory structure where all the FILESTREAM data is stored.
When you want to use FILESTREAM data, you first add a filegroup (during or after database creation):
ALTER DATABASE [FileStreamTestDB] ADD FILEGROUP [FileStreamGroup1] CONTAINS FILESTREAM; GO
And then add a ‘file’ to the filegroup:
ALTER DATABASE [FileStreamTestDB] ADD FILE ( NAME = [FSGroup1File], FILENAME = N'C:\Metro Labs\FileStreamTestDB\Documents') TO FILEGROUP [FileStreamGroup1]; GO
The ‘file’ is actually the pathname to what will become the root directory of the FILESTREAM data container. When it’s initially created, it will contain a single file, filestream.hdr, and a single directory $FSLOG. Filestream.hdr is a metadata file describing the data container and the $FSLOG directory is the FILESTREAM equivalent of the database transaction log. You can think of them as equivalent, although the FILESTREAM log has some interesting semantics.
The question I most often get is: are all the FILESTREAM files for a database stored in one gigantic directory? The answer is no.
The root directory of the data container contains one sub-directory for each table (or each partition of a partitioned table). Each of those directories contains a further sub-directory for each FILESTREAM column defined in the table. An example is below, with the screen shot taken after running the following code:
CREATE TABLE [FileStreamTest1] (
[DocId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[DocName] VARCHAR (25),
[Document] VARBINARY(MAX) FILESTREAM);
GO
CREATE TABLE [FileStreamTest2] (
[DocId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[DocName] VARCHAR (25),
[Document1] VARBINARY(MAX) FILESTREAM,
[Document2] VARBINARY(MAX) FILESTREAM);
GO
INSERT INTO [FileStreamTest1] VALUES (NEWID (), 'Paul Randal', CAST ('SQLskills.com' AS VARBINARY(MAX)));
INSERT INTO [FileStreamTest1] VALUES (NEWID (), 'Kimberly Tripp', CAST ('SQLskills.com' AS VARBINARY(MAX)));
GO
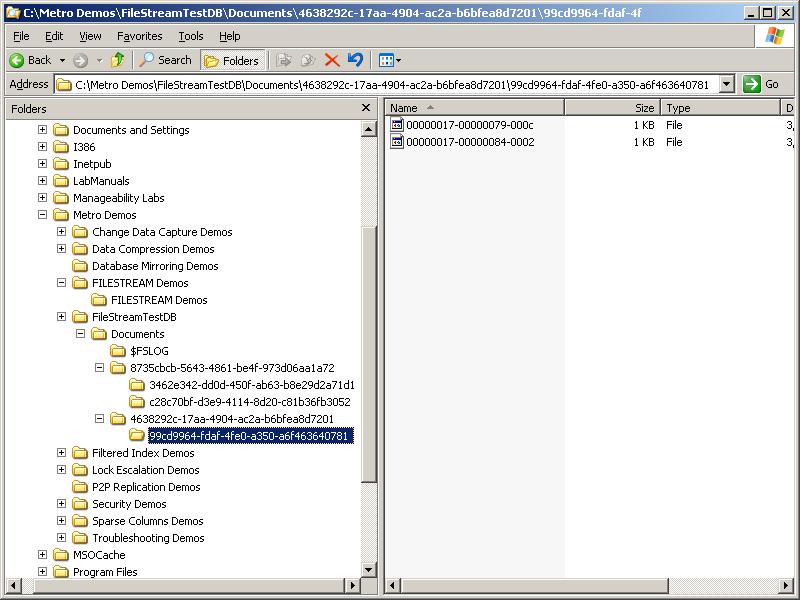
This image shows the FILESTREAM data container for our database that has two tables with FILESTREAM columns, each with a single partition. The first table has a two FILESTREAM columns and the second has a single FILESTREAM column. The filenames of all these directories are GUIDs and I explain how to match directories to tables and columns in this post.
In the example, you can see two FILESTREAM files in a column-level directory. The FILESTREAM file names are actually the log-sequence number from the database transaction log at the time the files were created. You can correlate these by looking at the data with DBCC PAGE, but first finding the allocated pages using sp_AllocationMetadata (see this blog post):
EXEC sp_AllocationMetadata FileStreamTest1; GO
Object Name Index ID Alloc Unit ID Alloc Unit Type First Page Root Page First IAM Page --------------- -------- ----------------- --------------- ---------- --------- -------------- FileStreamTest1 0 72057594039697408 IN_ROW_DATA (1:169) (0:0) (1:170) FileStreamTest1 0 72057594039762944 ROW_OVERFLOW_DATA (0:0) (0:0) (0:0) FileStreamTest1 2 72057594039828480 IN_ROW_DATA (1:171) (1:171) (1:172)
Notice there’s a nonclustered index as well as the heap – that’s the index that’s enforcing the uniqueness constraint on the UNIQUEIDENTIFIER column. Now we can use DBCC PAGE to look at the first page of the heap, which will have out data records in:
DBCC TRACEON (3604); DBCC PAGE (FileStreamTestDB, 1, 169, 3); GO
(snip) Slot 0 Offset 0x60 Length 88 Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS Record Size = 88 Memory Dump @0x514EC060 00000000: 30001400 140d5047 2ca9f24f 874d35ca †0.....PG,©òOM5Ê 00000010: e9e77649 03000002 00280058 80506175 †éçvI.....(.X.Pau 00000020: 6c205261 6e64616c 03000000 00000080 †l Randal........ 00000030: 140d5047 2ca9f24f 874d35ca e9e77649 †..PG,©òOM5ÊéçvI 00000040: 01000000 68020000 00000000 17000000 †....h........... 00000050: 79000000 0c000000 †††††††††††††††††††y....... Slot 0 Column 1 Offset 0x4 Length 16 Length (physical) 16 DocId = 47500d14-a92c-4ff2-874d-35cae9e77649 Slot 0 Column 2 Offset 0x1d Length 11 Length (physical) 11 DocName = Paul Randal Document = [Filestream column] Slot 0 Column 3 Offset 0x28 Length 48 ColType = 3 FileId = -2147483648 UpdateSeq = 1 CreateLSN = 00000017:00000079:000c (23:121:12) TxFMiniVer = 0 XdesId = (0:616) (snip)
You can see that the CreateLSN above matches the filename of the first FILESTREAM file in the example image.
Hopefully this explains how the FILESTREAM files are stored – more on this in the next post where I’ll explain how updates and garbage collection are implemented.
39 thoughts on “FILESTREAM directory structure”
Hi Paul,
I am an avid reader of your blog, it is pretty straight and simple – however I got "shocked" reading following statement in your msdn white-paper.
"deleting or renaming any FILESTREAM files directly through the file
system will result in database corruption"
Is there any work-around? because it sounds scary!
please reply, thanks
Jeet
Yes – don’t allow anyone access to the FILESTREAM data container directly. The Windows admin will always be able to obtain access whatever ACLs and OS you’re on, but if you don’t trust your admins, you have other problems.
Thanks…Great work…the command – [EXEC sp_AllocationMetadata FileStreamTest1] returns only 10 rows in our case; however, we expect 13,000 rows. Any tips and tricks ?
Why do you expect 13000 rows? It’s returning information about the allocation units in the table.
Hi Paul,
How does the directory structure look like for 2012? I know it’s a new feature in 2012 you can have multiple data container files in a single file group.
Thanks
Patrick
Haven’t played with that yet – will do.
hi
how filestream and rbs linked together in sharepoint and sql server
how orphan blobs will be created and how Microsoft maintained to delete these orphans blobs,
here I am facing one issue,
I taken backup of a rbs enabled content db in sql server 2012
and I restored to a new database, then I observed after some time of restore , some files are keep deleting from rbs storage folder.
I don’t know. Suggest you post this question in an MSDN Sharepoint forum.
When you do a FULL backup of the FILESTREAM database using SQL Studio Management Studio, does it automatically backup the data container folder?
Thanks
Yes
Thanks for posting this, Paul. I’m learning more about Filestreams thanks to you.
Question: I have SQL Server Enterprise and have multiple databases with the same structure—many tables, but just one of the tables has one varbinary(max) column, connected to its own filestream db, and its own filegroup. In the case of one of these databases, the table with the varbinary(max) column has over 1.5M records in it. This is much more than the 300,000 recommended max, per folder, for NTFS, and think this is why I’m seeing slow performance, when adding new records to this table. (I do not update rows, only insert and delete. I have also tried to use optimal settings in terms of turning off 8.3 filenames, no compression etc. etc.)
Is there a way to add more filegroups in order to redistribute the contained files, and improve performance? This is a Production db and it’s growing as I write this. Does SQL Server automatically distribute the files, or do I have to specifically indicate the filegroup when I do a read or write to this table? Since I’m using the Enterprise version of SQL Server, how can I leverage the ‘partitions’ feature in trying to improve performance?
Thanks for any help you can give!
Johnny
You’ll need to split the table into partitions so that each partition of the tab;e has a separate directory, thus lowering the number of file in each directory.
Thanks very much for your answer, Paul. We capped our one File and added three more, and performance has improved and we’re doing much better now. But, since we want to keep the related file count to under 300,000, is there a way to get a count of rows per database “File”?
Using sys.database_files, I can see the size of each File, which is great, but I can’t tell how many rows are associated with each File. Surely there is a map somewhere in the internals which indicates which File holds the physical file related to each row in the db.
If NTFS starts to perform badly after you have 300,000 files in a folder, the idea would be to have a SQL job which would add a new File, and cap an existing one when the number of rows in the latter File gets beyond 300,000 rows. I’m assuming that there is a fairly direct relationship between the number of rows and the number of related physical files in the folder for that File.
Kind of – you’d need to use partitioning to break the table up into partitions, each of which will have its own directory.
Hi Johny – Old comment, I know, but were you ever able to find a way to monitor container file counts as you described above without partitioning as suggested by Paul? Thanks!
Thank you for the useful post Paul!
We have implemented FileStream and stored unstructured data in a file table and displaying it from SSRS UI.
We were able to Browse thorough the UNC path that File Table generates using the GetFileNamespacePath() function. However, when we try to open the same path via network after converting it to a hyperlink, we are encountering an issue saying that “The network path cannot be found”.
This issue got fixed by restarting the server by disabling the filestream option on the server and re-enabling it after the reboot. Again, when we restored the backup, same issue occurs and a restart this time dint fix the issue.
I am sure this is not a network permission issue, since the user permissions to access the filestream data will be database level but not on Folder Level(FileStream Container Level).
Can you please throw some light on how to deal with this? appreciate any help.
Thanks,
Ranjit
No idea – you should contact Customer Support for assistance.
Hi Paul,
thanks for this useful article! I wanted to ask how to find (using T-SQL) in which filestream folder a file is saved.
We are using filestream partition based on a date and we have hundreds of subfolders under the main filestream folder.
I need to identify in which folder the filestream is currently writing.
thanks!
Regards
Paolo
See https://www.sqlskills.com/blogs/paul/filestream-directory-structure-where-do-the-guids-come-from/
Hi Paul,
Thanks for this nice article. Facing one issue. Please help me.
I enabled RBS for my SharePoint 2010 database. I am looking for a solution which will return the physical location of the document/file based on GUID that we will have in AllDocs table for each file that we upload to sharepoint library.
I could see files in the physical location without extensions are adding up as and when i upload file to sharepoint library.
thank you before hand
You’ll need to match the GUID directory names based on the query in https://www.sqlskills.com/blogs/paul/filestream-directory-structure-where-do-the-guids-come-from/
Hi Paul,
I’m a great fan of your articles which help me out in moments I need some help.
At this moment am I setting up a filestream configuration and I wonder, as I cannot find any documentation of this, if I could/should/want to use the fileshare which is created when enabling the Filestream option..
All the documents are about making a filegroup with a filelocation on a disk C:\temp (or whatever) but I’d wonder if the \\servername\[windows share name from SQL Server Properties Filestream] could be used and if this is a smart thing to do.
I do understand that I can have multiple databases on one server with the filestream option enabled, and in one database more filestream tables.
Thanks for your help in this and keep up the good work.
The fileshare is for applications to remotely access the FILESTREAM files – I would not use a file share for storing the FILESTREAM files remotely from the machine where SQL Server is running.
Hi Paul,
Sudenly, I’m getting an ODBCC error
Executing the query “DBCC CHECKDB(N’VisionFILES’) WITH NO_INFOMSGS
” failed with the following error: “Table error: Cannot find the FILESTREAM file “00001b01-0000016a-0028″ for column ID 2 (column directory ID dcf877c3-fccd-4aa8-94ff-074be85e9086 container ID 65537) in object ID 245575913, index ID 1, partition ID 72057594071547904, page ID (1:3188), slot ID 75.
CHECKDB found 0 allocation errors and 1 consistency errors in table ‘FW_Files’ (object ID 245575913).
CHECKDB found 0 allocation errors and 1 consistency errors in database ‘VisionFILES’.
repair_allow_data_loss is the minimum repair level for the errors found by DBCC CHECKDB (VisionFILES).”. Possible failure reasons: Problems with the query, “ResultSet” property not set correctly, parameters not set correctly, or connection not established correctly.
I’ve done some research and cannot find an answer. Could you help me?
Something or someone delete that file, or a table row wasn’t deleted properly. The former is more likely. You can run repair on the table, which will delete the row, or restore your backup to a different location and copy in the missing FILESTREAM file.
Thank you for your response, I’ll try the second option.
One more q.
From the error, which one is the fileID?
The file name is ‘00001b01-0000016a-0028’ in the directory ‘dcf877c3-fccd-4aa8-94ff-074be85e9086’.
Paul, thank you for responding.
I just want to say that I was able to resolve the issue by creating a dummy file. As I realized I did not have a back up prior to the error. Our DB is large, so I only keep 3 days.
I looked for the file repository/ DB properties/found the directory ‘dcf877c3-fccd-4aa8-94ff-074be85e9086’, placed a new file, rename it to ‘00001b01-0000016a-0028’
Run DBCC, got no error. Then run the maintenance plan just to be sure. All is good!
Bottom line we lost one file, but we have no errors and the maintenance plan is running with no issues.
I’m putting some detail in case someone else gets this error.
Thanks again for your help.
How to get the logical used and free space for FILESTREAM database or filegroup set for FILESTREAM ….
Shrink file property page is showing zero MB allocated space & Zero MB available free space however its folder is consuming 150 gigs
Any idea … how to get the actual usage and then shrink it accordingly …
You have to use Windows tools to do that, as there’s no tracking of the FS space used within SQL Sever.
Thank you. Paul – For the clarification!
Thanks for the great article, Paul.
What about the windows share name that we configure when enabling FILESTREAM from configuration manager, what is it used for?
For applications to access the FILESTREAM files from another server. And you’re welcome!
Hi, first of all, wonderful post! many thanks for it!.
Question: We use to have a database with filestream and from the OS perspective, directory and files names were “normal” and from there we allowed users to upload files to the folders thru a shared drive. Now, from one day to another we have the folders and files named as GUIDs, and from there the shared drive is now non-functional and users are now disabled to upload files.
any idea on how to return the funtionality? Thanks in advance!
Guesses: somehow the filestream configure setting was changed, or fsagent.exe isn’t working, or it’s a permissions issue suddenly.
Hi Paul,
I’m getting the an error for multiple files, tried to restore old db backup and still getting same error for the filestream. Not sure what to do.
Msg 7907, Level 16, State 1, Line 1
Table error: The directory “*************3c1-test” under the rowset directory ID ******************e0f3 is not a valid FILESTREAM directory in container ID 65537.
Msg 7904, Level 16, State 2, Line 1
Table error: Cannot find the FILESTREAM file “*****************0002” for column ID 3 (column directory ID **********************c83c1 container ID 65537) in object ID ************40, index ID 1, partition ID ***********600, page ID (1:253288), slot ID 1.
Msg 7904, Level 16, State 2, Line 1
If your backup has the same error in them, one thing to do and two to consider: do run repair. Consider performing checkdbs and backups more frequently. Thanks
Hi Paul. I am receiving the following error when trying to do a document merge:
Errors encountered during saving of the documents.
The operating system returned the error ‘0xc0000427(The requested operation could not be completed due to a fie system limitation)’ while attempting ‘NtCreateFile’ on ‘c:\xxxxxxxx\xxxxxxxx\DATA\LIPM_MB.LIPM_MLB_DVM_FSData\c78b10ca-3541-4907-93ef-510cc1464050\a3c89a3b-ec9e-4627-91a4-fd939d2e56da\0000b9b9-000026af-00d2’. The statement has been terminated.
SQL server 2014 running on Windows Server 2016. There are 2 million itedm in the FS folder. I have already run a defrag on the C:\ drive. What else can I do. Please help.
I’ve never encountered that before, but you’re right that the drive fragmentation is the underlying cause. The file you’re trying to add has too many fragments and so the fragment list max capacity for the file has been reached. I’ve seen people (not referencing SQL Server) say that copying the file, deleting the original, renaming the copied file back could solve it. I’ve never tried that before on a Filestream folder so if you want to attempt it, it’s at your own risk. I can’t thing of anything else.