In last week's survey I asked how you manage the size of your database *data* files – see here for the survey. Here are the results as of 6/24/09.
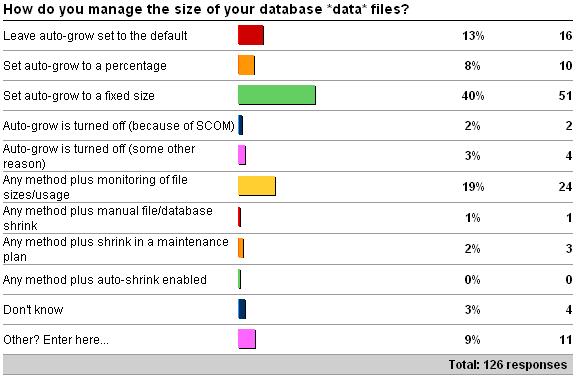
The 'other' values are as follows:
Check It Out!

-
5 x 'manual file growths and a custom mom alter to when the datafiles are 98% full. autogrow set to fixed amount in case we miss the mom e-mail'
-
1 x 'auto-grow with a procedure to keep the log file size at 20% relative to the total data file size'
-
1 x 'Create with very large initial file size, set auto-growth to %'
-
1 x 'Lots of white space in files. Auto-grow to a fixed size (in case of emergency).'
-
1 x 'set initial size for 1 yr usage, monitor size, manual grow, autogrow percentage – send alert if it does grow'
-
1 x 'set initial size for 2 year growth, capture growth stats daily, monitor physical disk space daily'
-
1 x 'Set to autogrow by fixed size to cater for emergencies, otherwise maintain 80-90% free space by daily reporting then manual off-peak size increase if necessary.'
As I mentioned in the survey itself, this is just about database *data* files. I covered log file size management in a previous survey – see Importance of proper transaction log size management.
There are really four parts to data file size management, which I'll discuss below.
The first thing I'll say is that if you're able to, enable instant file initialization on 2005+ – as it will vastly reduce the time required to create data files, grow data files, and restore backups (if the restore has to create data files). We're talking minutes/hours down to single-digit seconds. See Misconceptions around instant file initialization. If you're not one of the miniscule fraction of a percent of customers who have volumes shared between secure file servers and SQL Server instances, turn this on ASAP. Most DBAs don't know about this feature, but everyone I teach it to or show it to are amazed and then go turn it on. No brainer.
Initial data file sizing. This can be tricky. Without getting into the how-to-calculate-the-database-size quagmire, I'll simply say that you should provision as much space as you can, based upon your sizing estimates. Don't just provision for the here-and-now – if you're able to, provision space for the next year's worth of anticipated growth – to prevent auto-growth having to kick-in at all. I rewrote all the Books Online pages for 2005 (links are to the 2008 BOL) on Estimating the Size of Heaps, Clustered Indexes, and Nonclustered Indexes and in the blog post Tool for estimating the size of a database I link to a tool someone put together that codified all my formulas. You can also get sizing tools from hardware vendors too.
Data file growth. If you're able to, auto-grow should ALWAYS be turned on, as an emergency measure in case your monitoring fails – you don't want the database to have to grow but it's unable to and then it stops and the application is offline. However, you shouldn't *rely* on auto-grow – it's just for emergencies. The auto-growth default for data files used to be 10% for 2000 and before, but then changed to 1MB from 2005 onwards (log file default auto-growth remained at 10%). Neither of these are good choices. A percentage-based auto-growth means that as your files get bigger, so does the auto-growth, and potentially the time it takes if you don't have instant file initialization enabled. A 1MB autogrowth is just nonsensical. Your auto-growth should be set to a fixed size – but what that should be is a great big 'it depends'. You need to decide whether you want the auto-growth to be a quick stop-gap, or whether the auto-growth will replace manual growth after monitoring. You also need to consider how long the auto-growth will take, especially without instant file initialization. I can't give any guidance here as to what a good number is, but I'd probably settle on something around 10% (fixed), with the percentage steadily falling as the database size grows. It's very important that you have alerts setup to you can tell when auto-growth does occur, so you can then take any necessary action to grow it even more or tweak your settings.
'Other' response #2 is interesting. There's been a 'best-practice' around for a while that the log file should be sized to be a percentage of the data file size. It's totally unfounded and in most cases bears no relation to reality. The vast majority of the time, the size of the log is *NOT* dependent on the data file sizes in any way. Imagine a 10TB database – would you provision a 2TB log? Of course not. Now, I can see special cases where the operations performed on the tables in the database might affect a fixed portion of the largest table in a single batch, and that could generate enough log (with reserved space too) to equal 20% of the data file size – but that's a pretty nonsensical special case, to be honest. You shouldn't use 'set the log as a percentage of the data file' as a guideline.
Data file size/usage monitoring. There's a growing movement towards monitoring the data file usage and manually growing the files as they approach 100% full – avoiding auto-growth altogether, but still having it enabled for emergencies. In my book, this is the best way to go as you have all the control over what happens and more importantly, when it happens – especially without instant file initialization. There are some quirks here though. SCOM, for instance, has logic that disables file size and usage monitoring if you enable auto-grow. It assumes that if you enable auto-grow then you're not interested in monitoring. I happened to have one of the SCOM devs in my last maintenance class I taught on the Redmond MS campus and he's going to try to get that logic fixed.
Data file shrinking. Just this morning I wrote a long blog post about this – see Why you should not shrink your data files. Running data file shrink causes index fragmentation, uses lots of resources, and the vast majority of the time when people use it, is unnecessary and wasteful. It should NEVER be part of a regular maintenance plan – as you get into the shrink-grow-shrink-grow cycle which becomes a zero-sum game with a ton of transaction log being generated. Think about this – if you run a shrink, which is fully logged, then all the log has to be backed up, log-shipped, database mirrored, scanned by the replication log reader agent, and so on. And then the database will probably auto-grow again through normal operation, or some part of the maintenance job that rebuilds indexes. And then you shrink it again. And the cycle continues…
Bottom line – make sure you size the data files with some free space, have auto-growth set appropriately, have instant file initialization enabled if you can, monitor file sizes and usage, alert on auto-grows, and don't use shrink. And don't use shrink. Really.
Next up – this week's survey!
6 thoughts on “Importance of data file size management”
Hi Paul
Thanks for yet another interesting read. My ego is still bruised from being downvoted on serverfault.com, but I’ve learnt my lesson on shrinking files, honest! :)
I’ve been up and down your site since I last commented, and I’ve learnt a lot, so thanks for that too.
Please keep up the good work. As long as you’re willing to keep us informed, fewer people will be stuck with broken or badly-behaved databases.
Paul, to your comment: "SCOM, for instance, has logic that disables file size and usage monitoring if you enable auto-grow. It assumes that if you enable auto-grow then you’re not interested in monitoring. "
That’s been a huge disadvantage for us, and I ended up writing my own Management Pack with Filegroup monitoring and DB monitoring that is not dependant on SCOM SQL Management Pack. But it certainly has been a learning process.
I used both, Auto Growth and a weekly job to grow the data file if the size reach 70% of the threshold, and I used a fixed growth size – to avoid fragmentation – on both Auto Growth and the Weekly Growth job. The Auto Growth option is used for emergency, when unexpected volume was added before the weekend job started.
I have two issues, 1. my database is made up of multiple data files which are incosistent in size so not sure if that will impact performance or not, and 2. how big should I let my data file grow too. I know there is no hard number just trying to ask for some guidance.
Allocations happen based on a proportional-fill algorithm – proportionally more allocations happen in files with more free space. This can create a hot-spot which could cause you perf issues during checkpoint writes or large reads. Ideally the files should be around the same size.
Maximum file size is a subjective thing. Consider the time it will take to restore the file/filegroup in case of a disaster and then maybe split into multiple filesgroups for faster, more targeted recovery. Actual size has no bearing on workload performance though.
I’m seeing some file growth activity on my db that I don’t understand why it happening.
Background:
I have two file groups one for Tables/Clustered Indexes and one for Non Clustered indexes. The files in each of the file groups are equal in size to the other files in the same FG and each FG has 16 file. The auto grow is set to a fixed amount of 250MB for the files in the Non Clustered Index FG and 500MB for the files in the Tables/Clustered Indexes FG.
Conundrum:
What I’m not understanding is that each of these files have over 20% free space in them and what really doesn’t make any sense is that the current size of each file is 9GB and the last growth was on the Indexes FG in which the files went from 8750MB to 9000MB. If the files were really low enough to trigger the the auto grow the amount that each file was increased by wouldn’t give 20% free space so something else is saying it’s out of space and causing the growth but what could that be? Does SQL server wait until there is 0% free to trigger file growth or is that something that can be set on a database by database case?