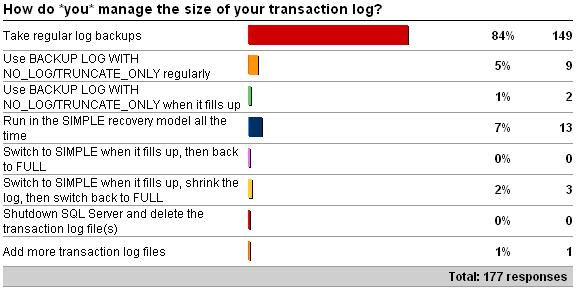
Last week's survey was on how *you* manage the size of your transaction log (see here for the survey). Here are the results as of 4/10/2009 – the most popular survey yet:
Check It Out!

In my opinion (guarantee that I'm going to say stuff that some of you won't agree with!), there are only two valid answers in this survey: #1 – run in the FULL recovery model and take regular log backups, and #4 – run in the SIMPLE recovery model all the time. The last answer is applicable if you run out of log space even though you're in either of these situations but isn't a general strategy like #1 or #4. IMHO, you should be in one of these two situations and in the rest of this editorial I'll explain why. I'm not going to touch on *why* your transaction log might start to fill up, instead here are some links:
-
Understanding Logging, Recovery, and the Transaction Log – feature article I wrote for the Feb 2009 TechNet Magazine
-
How to determine why your log has filled up – blog post examining some of the common causes
Now for the survey options:
- Take regular log backups. I'm very pleased to see the vast majority of respondents doing this, as it's the only valid log size management strategy when in the FULL recovery model (same thing applies to BULK_LOGGED of course, but with a few twists). Once you take that first database backup in the FULL recovery model, SQL Server assumes you're going to manage the transaction log size from that point on by taking log backups. Unfortunately that isn't documented in big, red flashing letters in Books Online – so people can get themselves into troubel inadvertently. Also, the FULL recovery model is the default, and is required for database mirroring – which further adds to the potential for people (such as involuntary DBAs) to accidentally switch into I-will-take-log-backups mode and then not take them. If you don't want to take log backups for recovery purposes, or you don't want to use database mirroring, don't use the FULL recovery model – it's as SIMPLE as that (ha ha). You might argue and say that you're only using FULL because of database mirroring, and don't want to take log backups. I'd argue back and say that if you care enough to have hot standby of your database, you must also take backups – as you can't rely solely on a redundant copy of your database on a different server.
- Use BACKUP LOG WITH NO_LOG/TRUNCATE_ONLY regularly. These two commands do basically the same thing – allow the log to be cleared without taking a log backup. What's the point if you're not taking log backups? – just switch to SIMPLE and let the checkpoints clear the log. In fact, in 2008 these two commands have been removed. See my blog post BACKUP LOG WITH NO_LOG – use, abuse, and undocumented trace flags to stop it.
- Use BACKUP LOG WITH NO_LOG/TRUNCATE_ONLY when it fills up. Same as above. You might argue that you're only keeping the log around in case there's a disaster, so that you can take a log backup at that point and use it to recover up to the point of the disaster. I'd argue that's broken on two counts: 1) what if the log file is damaged and you can't back it up? 2) that's *all* the transaction log since the last full database backup you took (if you break the log backup chain and then take a full database backup, that backup becomes the base of subsequent log backups) so that may take a long time to restore and replay…
- Run in the SIMPLE recovery model all the time. If you don't need to use FULL, don't. Running in SIMPLE is perfectly acceptable, as long as you don't mind losing work in the event of a disaster.
- Switch to SIMPLE when it fills up, then back to FULL. This is like #s 2 and 3 – what's the point?
- Switch to SIMPLE when it fills up, shrink the log, then switch back to FULL. This is worse than 2, 3, or 5. If you shrink the log, then it's going to grow again – possibly causing VLF fragmentation (see Transaction Log VLFs – too many or too few?), and definitely causing your workload to pause while the log grows, as the log can't use instant initialization (see Search Engine Q&A #24: Why can't the transaction log use instant initialization?).
- Shutdown SQL Server and delete the transaction log file(s). Just don't get me started on this one – I'm glad no-one 'fessed up to doing it. There are many reasons why this is daft, including: 1) you have to shutdown to do it, so your workload is off-line 2) if the database wasn't cleanly shut down, it won't be able to be started again without using EMERGENCY mode repair, and your data will be transactionally inconsistent 3) as the log can't be instant initialized, the database won't come online until the log has been created and zero'd. Just don't do this. Ever.
- Add more transaction log files. As a general strategy for managing the size of the log, this is not good. Extra log files have zero effect on performance (the myth that SQL Server writes in parallel to the log files is just that – a myth) and make management more tricky. However, if your log fills up for some out-of-the-ordinary reason, then adding another log file may be the only way to allow the database to keep running. If you have to do this though, make sure that you remove the extra log file(s) when you can to keep log management uncomplicated.
To summarize, if you want to be able to take log backups to aid in point-in-time or up-to-the-second recovery, use the FULL recovery model. If not, use SIMPLE and you won't need to mess around with the log when it fills up because you're not taking log backups.
Next post – this week's survey! (And thanks to all those who are responding to them!)
PS For those of you who sent me details about your databases from the survey back at the start of March (see here) – I haven't forgotten. I was waiting to get a decent sample size and now I'm going to go through the data. If you want to send me any more data, you've got until Sunday.
24 thoughts on “Importance of proper transaction log size management”
Paul,
Nice writing. A short note on option #2 and #3: I wrote a sentence very similar to yours about using BACKUP LOG WITH NO_LOG and one of my readers explained that they have database mirroring, so they’re bound to FULL recovery model but they’re absolutely not interested in retaining the transaction log, so they truncate it regularly. Admittedly, this is not the average reason, but I’m getting used to the never-say-never feeling :) For #7 – I didn’t believe this can be thought seriously until I met a technical advisor who did it (and suggested their clients for a bunch of money).
Erik
They should be interested in retaining the transaction log even with mirroring. I had a client with similar desires and I quickly showed them that it was a Really Bad Idea to not have the t-log backups. Mirroring is far from foolproof. What I wound up doing (as space was an issue) was to have a shorter cycle of t-logs preserved.
Absolutely agree – but sometimes you just can’t persuade people *until* they have a disaster and find that something goes wrong with their primary HA technology.
There are many reasons why this is daft, including: 1) you have to shutdown to do it, so your workload is off-line 2) if the database wasn’t cleanly shut down, it won’t be able to be started again without using EMERGENCY mode repair, and your data will be transactionally inconsistent 3) as the log can’t be instant initialized, the database won’t come online until the log has been created and zero’d. Just don’t do this.
Setting up the production server tomorrow including backup. First test? Yank the power and verify log backups worked. That way there *is* a disaster.
Hi Paul, I have always been taught to have only one log file, but was wondering about the strategy of having two log files, a “primary” one that is carefully sized through capacity planning and has autogrowth shut off, and a “secondary” log file that would hopefully never be reached but that can be used and autogrow in case the first one fills up due to unforeseen multiple open transactions? (I read about a DBA using this strategy on a blog, sorry don’t have the details anymore.)
What would be the negative consequences of implementing such a strategy? I am not experienced enough to know whether this could be effective but it seemed like a cool idea, however due to the general consensus against multiple logfiles I am hesitant to accept this unusual but interesting strategy.
No perf issues, but for disaster recovery, the more log space there is, the longer it takes to zero initialize it when restoring from scratch.
What I don’t understand why in my case the ldf file is still growing whilst the recovery model is Full and every hour backup taken of the ldf file.
Checked active transaction with DBCC OPENTRAN and result was : No active open transactions.
Any suggestions?
Thanks.
What’s the result of “SELECT log_reuse_wait_desc FROM sys.databases” for your database?
Hello Paul,
I am reading a lot lately about recovery models, log backups and so on, including your great posts. But I still have some unanswered questions in my mind. Recently I came across a sceneario where due to SQL’s AAG, the recovery model of the databases was set to full. No transaction log backup was being done, but full backups happened every night.
1. Why does the transaction log keep growing uncontrolled?
2. In case of failure wouldn’t be enough to have the full backup and the log just being filled from that point of time?
3. If full backups inlcude log file backup (is that right?), why does this not help keeping the transaction log small?
Thanks a lot!
Jaime
1) Because you’re not performing transaction log backups
2) No
3) No. Full backups only include enough log necessary to recover the full backup when restored.
You must perform log backups when in the full recovery mode otherwise your log will grow forever.
See https://www.sqlskills.com/blogs/paul/the-accidental-dba-day-7-of-30-backups-recovery-models-and-backup-types/
Hi Paul! I’ve a situation related to log. In a database that is not involved in any replication schema (and never was) after a backup log a got the message “SQL Server Log File Won’t Shrink due cause “log are pending replication” “…. First all a have to mention that the database is in simple mode (sql version 10.0.5500), after an alert i got noticed that log file was growing and growing… So… a got full database backup, put database in full mode and take backup log (and then i got initial message posted)… the log_reuse_wait_desc field of sys.databases for database shows “replication”… the workaround was (after try an sp_repldone which with sense shows “The database is not published. Execute the procedure in a database that is published for replication.” , also select DATABASEPROPERTY(‘databasename’,’ISPublished’) shoes an expected Zero) to execute sp_removedbreplication…
I didn’t found a explicit microsoft bug o case opened for this situation… Do you now what could be the root cause for my situation in order to prevent it if is possible.. .Thanks a lot in advance, and congratulations for all your posts.
No idea what could have caused that, but I’ve heard of it before. You’ll need to run sp_removedbreplication in that database.
well i was wondering if any hit issue with rebuild indexes fill up disks in few min time .
we just upgraded the storage and now we can have 6GB/SEC IO from it . . .
was doing some testing and i manage to create 400GB of LDF in 1min for 500GB db …
so running log backups dont help and DISK fill up .
i think i can limit I/O with resource govener or somthing from storage .
but what the point in upgrading storage then …
cant use simple mode … this should be part of ALWAYS ON group … no way i can transfer 400GB on the net to secondery as well under one minut (have sync and async nodes ) …
was thinking to do it table by table with some waiting in between or somthing , IO wise and Network wise .
smart script with reorge for less then 30% will help as well but i dont like this risk
fun fun fun
You should be able to back up the log between index rebuilds, but a single index rebuild is one transaction, so log backup won’t clear the log from that until the rebuild finishes.
If you’re using an AG, you’ll likely have to switch to using index reorganize instead of rebuild, and consider using staggered index maintenance – see http://sqlmag.com/blog/efficient-index-maintenance-using-database-mirroring
Hi Paul,
My database is in AAG 2014 and the log file keeps on increasing even though regular log backups are been taken but the log file still goes on increasing. If I shrink the log file on primary will it effect the performance or give any consistency issues. What could be the reason for log file growth even though regular log backup happen please suggest.
You need to look at the value of log_reuse_wait_desc for the database. See https://www.sqlskills.com/blogs/paul/worrying-cause-log-growth-log_reuse_wait_desc/
Hello Paul,
It’s a good to have your article. But what if, the .ldf file size is 207 GB and I just need to reduce a size of a file then what should I do?
Shrinkfile, log backup, shrinkfile, log backup, repeat until it shrinks down to where you want it.
Thanks for the reply!
Is there any suggestion to shrink a log file?
Do you mean how to shrink it? DBCC SHRINKFILE.
Yes, I have below script to do the same.
USE ;
GO
— Truncate the log by changing the database recovery model to SIMPLE.
ALTER DATABASE
SET RECOVERY SIMPLE;
GO
— Shrink the truncated log file to 1 MB*.
DBCC SHRINKFILE ;
GO
— Reset the database recovery model.
ALTER DATABASE
SET RECOVERY FULL;
GO
IS there any impact? if I want to recover the the database after some days from the logfile shrink.
That’s the absolute worst way to do it as it breaks the log backup chain. Log backup, shrink, repeat in full recovery model.
My predecessor choose option 4. Recently I needed disk space and shrinked the transaction files of one the databases (the less important) to gain 53GB, I’m not sure of what you were meaning with “If not, use SIMPLE and you won’t need to mess around with the log when it fills up because you’re not taking log backups.”
I’m not taking log backups but 53GB in a ldf file need to be messed if you need space and have to measure to ask for more disc space to your superiors or shrink the useless file. (Now I don’t know when regrowth will claim the space again, I believe it took at least the 6 years I’m working at the firm to reach that size, the another ldf file is at 37485,24 MB)