In last week's survey I asked you two things, as a precursor to a whitepaper I'm writing for Microsoft
The first question was what is your maximum allowable downtime SLA (either for 24×7 operation or not). See here for the survey. Here are the results as of 5/30/09.
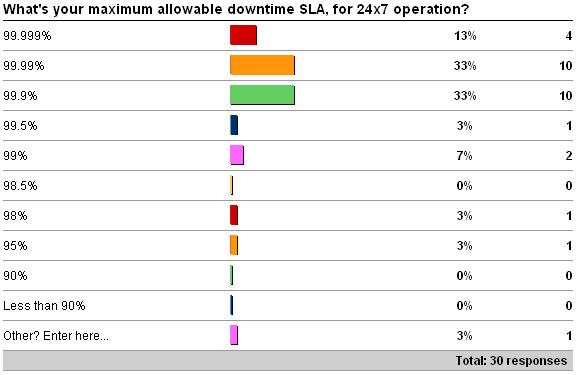
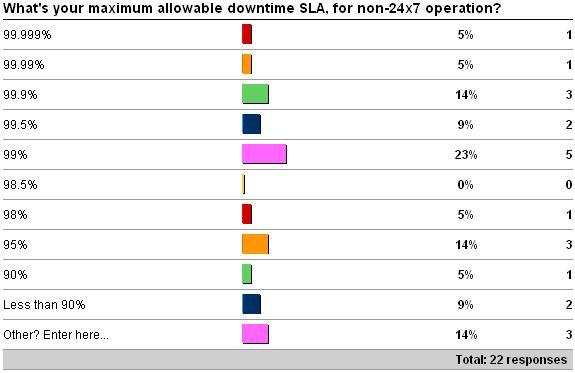
The Other values were all about not having SLAs defined. And I think that's why this survey had a poor response rate – most of you out there don't have defined SLAs.
If you take a standard 365-day year, which means the year has 524160 minutes. Some example maximum allowable downtimes for 24×7 operations:
- 99.999% (a.k.a 'five-nines') = slightly over 5 minutes downtime per year
- 99.99% (a.k.a 'four-nines') = almost 52.5 minutes downtime per year
- 99.9% (a.k.a 'three-nines') = almost 8.75 hours downtime per year
- 99% (a.k.a 'two-nines') = just over 3.5 days of downtime per year
- 98.5% = almost 5.5 days of downtime per year
- 98% = just over a week of downtime per year
- 95% = just over 2.5 weeks of downtime per year
You might be thinking – wow – whoever only has a target of 95% uptime must have a pretty crappy setup BUT it totally depends on the application and business requirements. 95% may be absolutely fine for some companies and utterly devastating to others (imagine the revenue loss if Amazon.com was down for more than 2 weeks…)
On the other end of the spectrum, you might be thinking – wow – 99.999% target is completely unattainable for the majority of businesses out there, BUT again it totally depends on the application and business requirements. This may be attainable for a simple application and database that doesn't generate much transaction log, or for a large, very busy OLTP database that generates lots of log but the company has lots of money to throw at the HA problem and can afford redundant clusters in separate data-centers with fat, dark-fiber links between them.
Defining SLAs, and not just for maximum allowable downtime, is incredibly important. When done properly, defining SLAs shows that the technical staff in a company and the business management in a company are in tune. It shows they have extensively analyzed the business requirements of an application and balanced them against the technical, space, power, HVAC, manpower, budgetary, and other limitations which may prevent a higher percentage being set as the target. It provides a meaningful input into the design and architecture of systems, and the choices of technologies (note the plural) required to achieve the target SLAs. It shows the company shareholders that the business managers understand the criticality of applications involved in running the business and that they are taking steps to safeguard the shareholders' equity interests.
Note I said 'when done properly'. Technical staff picking SLAs without business input, or vice-versa is a recipe for disaster. If the technical staff don't understand the business requirements, how can they pick appropriate SLAs? If the business managers don't understand the technical limitations, how can they pick achievable SLAs? Everyone has to be involved. And one of the most important things to consider is whether the SLA covers 24×7 operation, or just the time that the application has to be available, if not 24×7.
How to go about using the SLAs to pick appropriate technologies is one of the things I'll be going into in the whitepaper (due for publication around the end of September).
The second questions was what was your measured uptime (again, either for 24×7 operation or not) over the last year. See here for the survey. Here are the results as of 5/30/09.
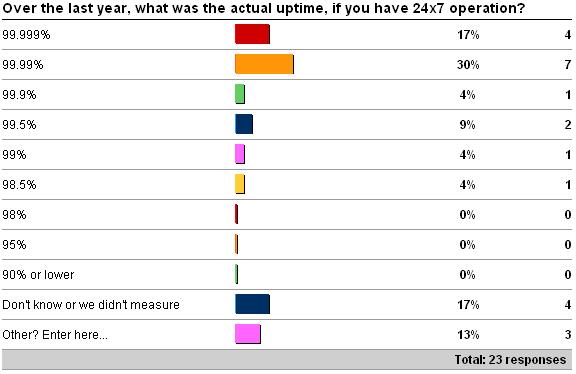
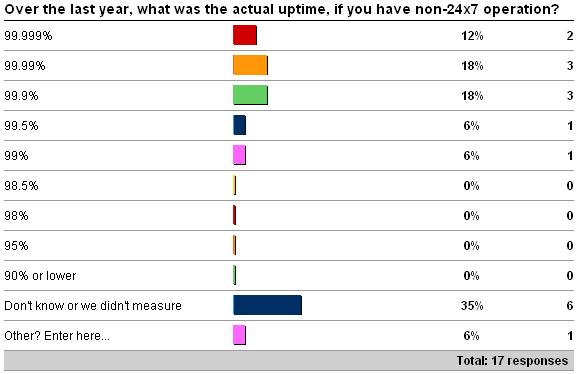
The Other values for 24×7 were 2 x '96', and 1 x 'it varies across customers'. The Other value for non-24×7 was '92'.
Of course, this would be a little more meaningful if we could correlate target downtime with actual downtime achieved, but the free survey site doesn't reach that level of sophistication (and I don't think people have enough time to get into that much detail) while casually reading a blog post.
Nevertheless, the results are interesting, although not really statistically valid from this small a sample-size. The most interesting data point is that some respondents don't know what they achieved last year, or just didn't measure. I think this is the case for the majority of readers. Having well-defined and appropriate SLAs is the key to defining a workable strategy, and what's the point of defining the SLAs if you don't measure how well you did against them? If you don't meet the target you need to revisit the strategy, the SLAs, or maybe even both.
The fact that many people don't have SLAs speaks to the general poor state of high-availability and disaster-recovery planning in the industry, IMHO. And Kimberly just chimed in stating that it also shows how the PC-based server market doesn't focus anywhere near as much on regimented policies and procedures as the older, more traditional, mainframe market did/does.
There's a lot of work to be done. Many times this stuff just isn't high up in the priority list until a disaster actually happens. Invariably it then becomes very, very important. Get ahead of the curve and be proactive – one of the things we always tell our clients.
Next post – this week's survey!