A couple of weeks ago I kicked off the latest survey, on what the physical layout of your databases are and why you have them that way (see here for the survey). I let the survey run for a while to get a good sampling, and I wasn't disappointed, with over 1000 responses! Here are the results as of 4/27/2009.
Just like any other 'best practice' kind of topic, the question of how to design the physical layout of a database provokes a lot of (sometimes heated) discussion. There are lots of options and there are even more factors to consider – so the best answer is my perennial favorite "it depends"! In this post, I don't want to tell you how I think you should layout your database – instead I want to discuss some of the options and let you make up your own mind, with the added benefit of data on what your peers are doing with their databases. The main point of this survey was to see what people are doing, rather than as a driver for an editorial blog post.
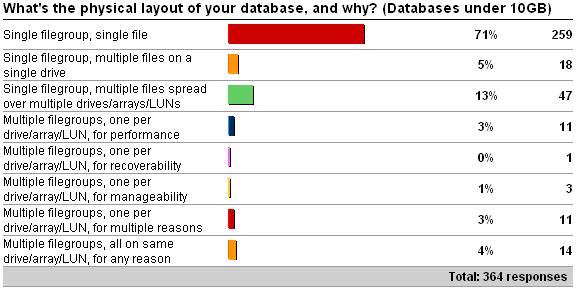
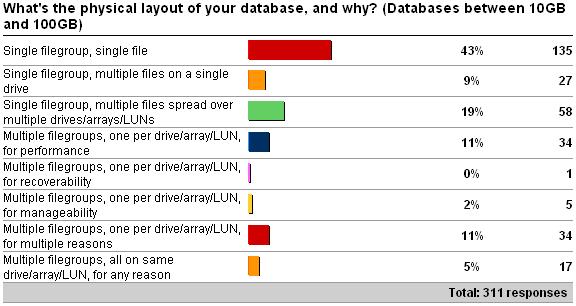
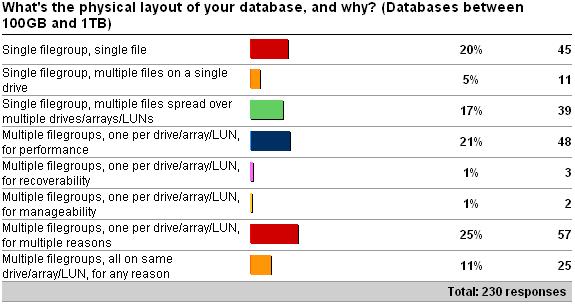
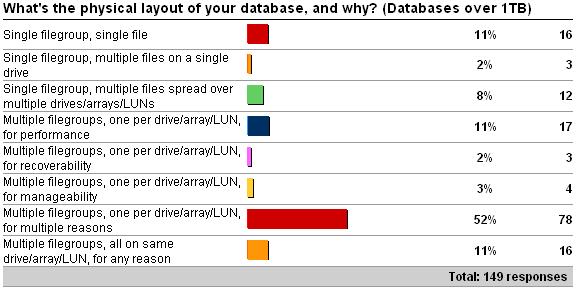
As you can clearly see from the results above, and predictably, the distribution of layout types shifts as the database size increases – but I was very surprised by the number of single file databases over 10GB. Rather than go through each option in the survey, I'm going to talk a bit about some of the things to consider when planning a layout.
Underlying I/O subsystem
This could be the most important factor to consider. If you only have a single physical drive, for instance, there's arguably not much point creating multiple data files, as that will force the disk heads to bounce back and forth to the different file locations on the disk. On the other hand, if you have a SAN with several thousand drives grouped together into multiple LUNs, your possibilities are a lot wider (and maybe much harder to come up with the optimal layout). Several people asked if I'd go into depth around having multiple controllers, and different drive layouts in a SAN – and my answer is no. I'm not an expert at storage design, which, like indexing, is both an art and a science. There's a good whitepaper that discusses some of this: Physical Database Storage Design, which I helped review back in my MS days.
Performance, recoverability, manageability
Having multiple files with separate storage for each allows reads and writes to be parallelized for increased performance, lowering the amount of disk head contention. When a checkpoint occurs, and pages are written to disk, spreading the I/O load over multiples files can speed up the checkpoint and reduce the IOPS spikes that you may see. It can also lead to reduced contention for the various allocation bitmaps – in the same way as I've described for tempdb. In user databases with a very high rate of allocations, contention can arise on the GAM pages – but it's not common. Some people also advocate having separate filegroups for tables and indexes, and although this can sometimes be more trouble than it's worth, and often turns into a religious debate, I have heard of people getting a perf boost from this.
One of the most convincing reasons (I find) for having multiple filegroups is the ability to do much more targeted recovery. With a single file database, if it gets corrupted or lost, you have to restore the whole database, no matter how large the file is – and this can seriously affect your ability to recover within the RTO (Recovery Time Objective) agreement. By splitting the database into multiple filegroups, you can make use of partial database availability and online piecemeal restores (in Enterprise Edition) to allow the database to be online as soon as the primary filegroup is online, and then restore the remaining filegroups in priority order – bringing the application online as soon as the relevant filegroups are online. You can even use this layout to spread your backup workload – moving to filegroup-based backups instead of database backups, although this isn't very common.
As far as manageability is concerned, there are a few reasons to have multiple filegroups. Firstly, you can isolate a table that requires a lot of I/O (e.g. in terms of index maintenance) on separate storage from other tables, so that maintenance operations (and the I/O overhead of doing them) doesn't interfere with the I/O of the other tables. Also, you can provision different kinds of storage for different tables – in terms of disk speed and RAID level (redundancy), for instance. If you want to be able to move data around, you can do it much more easily if the database is split up, than if it's a single file.
Summary
Ok – so I lied. I *am* going to offer advice – against one of the options: single filegroup, single file. For smaller databases, this is fine – but as the database size gets larger, say, over tens of GB, then having a single file can become a serious liability. With a single file database (or even a single filegroup database), you lose most of the benefits mentioned above.
Bottom line – as your databases get larger, you're going to need to think more carefully about their layout, otherwise you could run into big problems as your workload increases or when disaster strikes. As the survey results show, this is what your peers are doing.
Next post – this week's survey!
5 thoughts on “Physical database layout vs. database size”
I’ve seen a lot of people recommending and/or implementing one data file per processor core for user databases, I suspect often without understanding the origin or context of the recommendation.
If you have a few minutes free, could you perhaps do a blog post on that?
Thanks
Paul,
I agree with your recommendations. The only challenge I have that is worth mentioning is with vendor applications. Some vendors say any changes to their schema may violate support agreements. I can understand this argument to a degree as it relates to tables (columns, data types, etc.) and other possible DB objects, but it is a fine line to extend that policy to files and file groups. In my opinion, the physical DB implementation should be enough removed from the application schema to not affect the application.
Any comments or history regarding physical DB design and vendor applications? Do you suspect that some / many DBAs have their hands tied by such vendor policies?
Although not directly related, it is similar to the common application vendor position of:
“We will not support version vvvv of our application aaaa on SQL Server xxxx until mm/dd/yyyy (if at all)”
– Or-
“We will only support version vvvv of our application aaaa on SQL Server xxxx”.
Scott R.
It comes from the tempdb recommendations, and doesn’t apply to user databases. I did a big blog post on that last week. Thanks
Sorry, must have missed that one.
@Scott Yup – prime example is SharePoint. Only one filegroup allowed and indexes can’t be added without breaking the support agreement. Sigh.