Continuing on our path to understanding the basics and core concepts, there’s a big topic that’s often greatly misunderstood and that’s partitioning. I know I’m going to struggle keeping this one an introductory post but I’ve decided there are a few critical questions to ask and a few very important things to consider before choosing a partitioning strategy / design / architecture. I’ll start with those key points!
Partitioning is Not About Performance
I’m often asked – how can I use partitioning to improve this or that… and they’re often queries. I remember one where someone said they had a 3 billion row table and one of their queries was taking 15 minutes to run. Their question was – how can they best partition to improve query performance. I asked if I could look at the query and review their schema (secretly, that meant I wanted to see their indexes ;-)). And, sure enough, I asked if they were open to trying something. I gave them an index to create and asked them to run their query again. Without ANY changes to their table’s structure and only one added index, their query ran in 9 seconds.

Now, don’t forget – indexes aren’t all unicorns and rainbows… indexes have a downside:
- An index requires disk space / memory / space in your backups
- An index adds overhead to your inserts / updates / deletes
- An index needs to be maintained
So, you’d still need to determine if this is the right approach. But, the main point – partitioning really isn’t designed to give incredible gains to your queries. It’s meant to be better for data management and maintenance. However, some partitioning designs can lead to query performance benefits too.
Partitioning for Manageability / Maintenance
The primary reason to consider some form of partitioning is to give you option in dealing with large tables; I tend to start thinking about partitioning as a table approaches 100GB AND it’s not going away (but, even if some of it will regularly “go away” then partitioning is definitely an option to help manage that regular archiving / deleting). I wrote a detailed post about this in response to an MSDN Webcast question I was asked about range-based deletes on a large table. It’s a very long post but it revolves around “how to make range-based deletes faster.” You can review that here. (NOTE: That post was written before we converted our blog to the new format and I’ve not yet gone through and manually converted all of my old posts… so, the formatting isn’t great. But, the content / concepts still apply!)
So the real reasons to consider partitioning are:
- Your table is getting too large for your current system to manage but not all of that data is accessed regularly (access patterns are really the key). There isn’t a magic size for when this happens; it’s really relative to your hardware. I’ve seen tables of only 40GB or 50GB cause problems on systems that only have 32GB or 64GB of memory). No, you don’t always need to put your entire table in memory but there are many operations that cause the table to end up there. In general, as your tables get larger and larger – many problems start to become more prominent as well. Often, a VLDB (Very Large Database) is considered 1TB or more. But, what I think is the more common problem is the size of your critical tables; when do they start causing you grief? What is a VLT (Very Large Table)? For me, as your table starts to really head toward 100GB; that’s when partitioning should be considered.
- You have varying access patterns to the data:
- Some data is recent, critical, and very active
- A lot of data is not quite as recent, mostly only reads but with some modifications (often referred to as “read-mostly”)
- The bulk of your data is historical and not accessed often but must be kept for a variety of reasons (including some large / infrequent analysis queries)
And that second point, is the most common reason to consider partitioning… but, it’s the first point that’s probably more noticable. :-)
What Feature(s) Should Be Used for Partitioning
As I’ve been discussing partitioning, I’ve been trying to generalize it as more of a concept rather than a feature (NOT tied directly to either SQL Server feature: partitioned tables [2005+] or partitioned views [7.0+]). Instead, I want you to think of it as a way of breaking down a table into smaller (more manageable) chunks. This is almost always a good thing. But, while it sounds great at first – the specific technologies have many considerations before choosing (especially depending on which version of SQL Server you’re working with).
Partitioned Views (PVs)
These have been available in SQL Server since version 7.0. They were very limited in SQL Server 7.0 in that they were query-only. As of SQL Server 2000, they allow modifications (through the PV and to the base tables) but with a few restrictions. There have been some bug fixes and improvements since their introduction but their creation, and uses are largely the same. And, even with SQL Server 2016 (and all of the improvements for Partitioned Tables), there are still scenarios where PVs make sense – sometimes as the partitioning mechanism by itself and sometimes combined with partitioned tables.
Partitioned Tables (PTs)
Partitioned tables were introduced in SQL Server 2005 and have had numerous improvements from release to release. This list is by no means exhaustive but some of the biggest improvements have been:
- SQL Server 2008 introduced partition-aligned indexed views so that you could do fast switching in / out of partitioned tables even when the PT had an indexed view. And, SQL Server 2008 introduced partition-level lock escalation (however, some architectures [like what I recommend below] can naturally reduce the need for partition-level lock escalation).
- SQL Server 2008 R2 (SP1 and 2008 SP2) offered support for up to 15,000 partitions (personally, I’m not a fan of this one).
- SQL Server 2012 allowed index rebuilds to be performed as online operations even if the table has LOB data. So, if you want to switch from a non-partitioned table to a partitioned table (while keeping the table online / available), you can do this even when the table has LOB columns.
- SQL Server 2014 offered better partition-level management with online partition-level rebuilds and incremental stats. These features reduce what’s read for statistics updates and places the threshold to update at the partition-level rather than at the table-level. And, they offer the option to just rebuild the partition while keeping the table and the partition online. However, the query optimizer still uses table-level statistics for optimization (Erin wrote an article about this titled: Incremental Statistics are NOT used by the Query Optimizer and Joe Sack wrote an article about partition-level rebuilds titled: Exploring Partition-Level Online Index Operations in SQL Server 2014 CTP1.)
- SQL Server 2016 further reduced the threshold for triggering statistics updates to a more dynamic threshold (the same as trace flag 2371) but only for databases with a compatibility mode of 130 (or higher). See KB 2754171 for more information.
However, even with these improvements, PTs still have limitations that smaller tables don’t have. And, often, the best way to deal with a very large table is to not have one. Don’t misunderstand, what I’m suggesting is to use PVs with multiple smaller tables (possibly even PTs) unioned together. The end result is one with few, if any, real restrictions (by physically breaking your table into smaller ones, you remove a lot of the limitations that exist with PTs). However, you don’t want all that many smaller tables either as the process for optimization is more complicated with larger numbers of tables. The key is to find a balance. Often, my general recommendation is to have a separate table per year of data (image “sales” data), and then for the older years – just leave those as a single, standalone table. For the current and future years, use PTs to separate the “hot” data from the more stable data. By using standalone tables for the critical data you can do full table-level rebuilds online (in EE) and you can update statistics more frequently (and they’re more accurate on smaller tables). Then, as these standalone months stabilize you can switch them into the year-based PTs to further simplify their management moving forward.
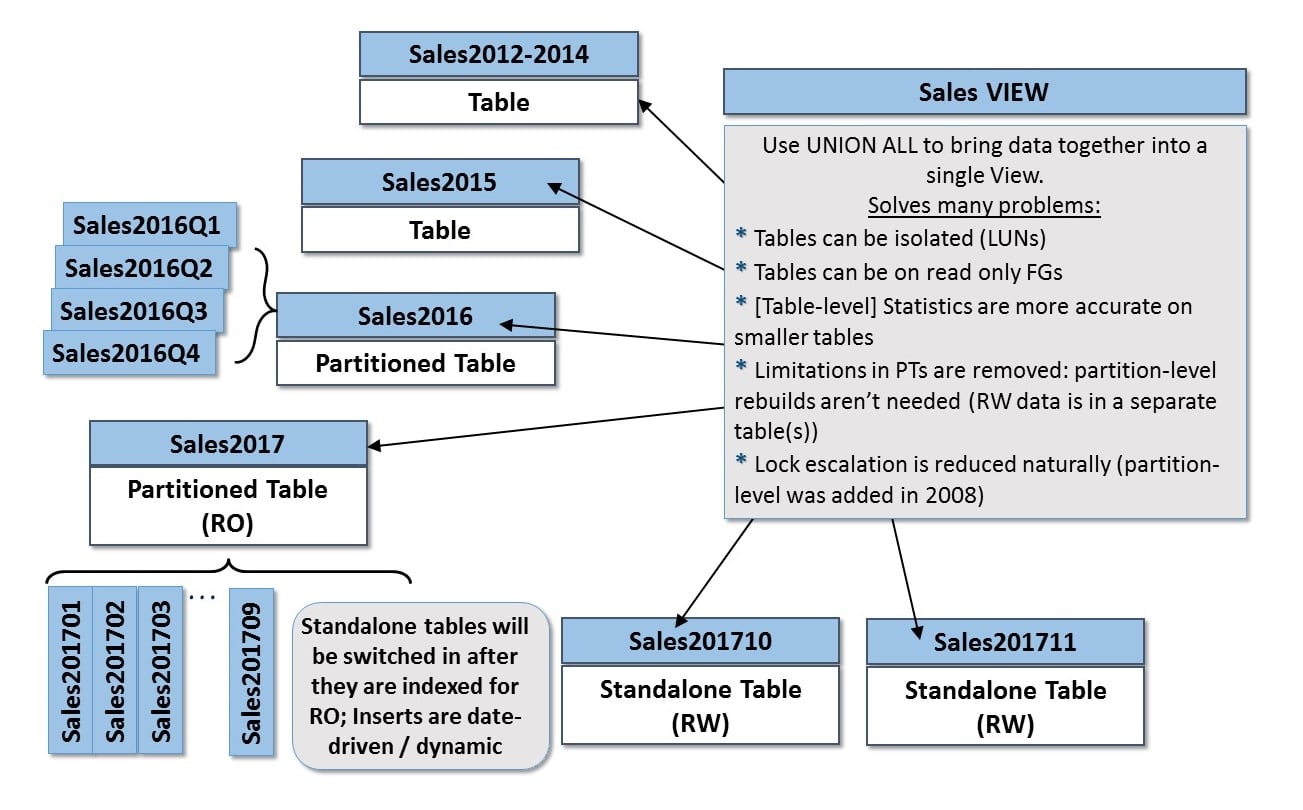
This architecture is complex but highly effective when designed properly. Doing some early prototyping with all of the features you plan to leverage is key to your success.
Key Points Before Implementing Partitioning
Partitioning is not really directly tied to performance but indirectly it can be extremely beneficial. So, for a SQL101 post, the most important point is that partitioned views still have benefits; they should not be discounted only because they’re an older feature. Both partitioning strategies provide different benefits; the RIGHT solution takes understanding ALL of their pros/cons. You need to evaluate both PVs and PTs against your availability, manageability, and performance requirements – and, in the most likely case, use them together for the most gains.
Since it’s concepts only, I still feel like it’s a SQL101 post. But, getting this right is a 300-400 level prototyping task after quite a bit of design.
Thanks for reading!
Kimberly
One thought on “SQLskills SQL101: Partitioning”
One thing that simplifies the choice of Views/Tables is the SQL Edition. At least through 2014 PT are Enterprise only and some of us are still limited Standard :).
I implemented an automated system based on updateable partitioned views for a number of tables in our system that are both very large and have a high turn over. One of the first is a good example. At the time the table received more than 10M rows/week and needed to retain about 90 days of data. The cleanup job was trying to delete about 10K rows per pass and running almost continuously. Deadlocks were common and blocking was constant.
Today (after 4+years) the table receives ~35M rows/week (~10GB) but the cleanup time is trivial. Just alter the view and truncate/drop the old table.
We have extended and automated the approach to cover more than a dozen similar tables including logging, history, etc.
The partitioning may not directly improve query performance but it has significantly reduced/eliminated the time required for cleanup. Now any blocking is caused by application queries and deadlocks are unknown.
Kimberly, your original posting on this topic was the inspiration for the initial work
Thanks,