Last month I kicked off a survey asking you to run some code to send me data on the size, number of files, and number of filegroups in your databases. I got back more than 17000 results, and I’m presenting a couple of ways of interpreting the data here. Interestingly, I only had a handful of results for databases above 100GB and for databases with more than 100 files, so to keep the graphs readable, I’ve chosen to exclude those.
Single Filegroup
First off, for databases with only a primary filegroup, how many files were there in that filegroup?
Check It Out!

- 24 files: 3 databases
- 20 files: 1 database
- 16 files: 3 databases
- 15 files: 1 database
- 12 files: 1 database
- 10 files: 1 database
- 8 files: 10 databases
- 7 files: 1 database
- 6 files: 50 databases
- 5 files: 6 databases
- 4 files: 56 databases
- 3 files: 27 databases
- 2 files: 67 databases
- 1 file: 16121 databases
Unsurprisingly, single file plus single filegroup is the most common physical layout. We see this over and over, regardless of the size of the database.
As your databases start to increase in size, you need to consider splitting them up (note I’m not using the overloaded term ‘partitioning’) to allow you to do:
- Targeted restores in the event of wholesale data loss, helping to reduce downtime. If you have multiple filegroups, you can potentially do a partial restore of only the data required to get the OLTP portion of your workload up and running, restoring the rest of the filegroups later.
- Targeted maintenance to reduce the time and resources necessary to manage fragmentation. If your indexes are split of multiple filegroups (using partitioning) you can rebuild or reorganize just the index portion that has fragmentation.
- Targeted performance management. If your workload uses/affects multiple portions of your database, it may be beneficial to place those different portions of the database on different sections of your I/O subsystem.
None of these things can be done with a single file plus single filegroup database.
Data Files vs. Filegroups
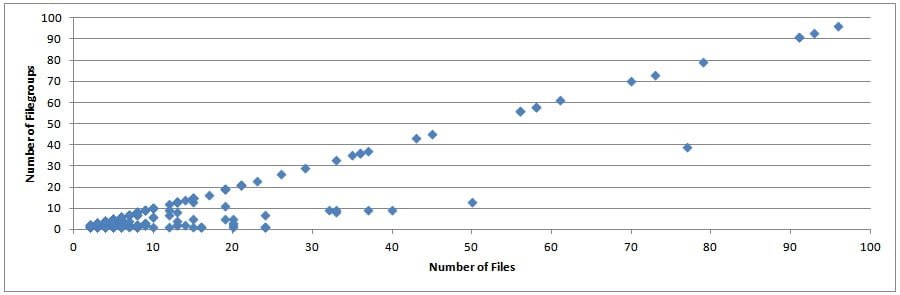
This is really interesting. The majority of databases that had more than one filegroup had the number of data files equal to the number of filegroups. I was prepared for this, with quite a few respondents pointing this out in their data and explaining that the database is from a third-party vendor application.
As a general rule of thumb, I recommend each filegroup having 2-4 data files, as this will give overall better I/O performance than a single data file. I’ve seen this over and over on client systems and you can see quite a few data points on the graph above reflecting that too. I also have some empirical evidence from various performance tests I’ve done (narrow scenarios, but definite proof-points):
Just to be clear, based on comments, this is because of parallelism at the I/O subsystem level (not one thread per data file, as that’s a myth, but being able to write to multiple points on the array during checkpoints), and this does not apply if you only have a single physical drive on which to put your data (and I don’t mean what Windows sees as a single drive letter, I really mean just one actual drive). In fact, if you only have a single drive, you have other problems because that gives you no redundancy – you’re living on a knife-edge.
Note that I didn’t include tempdb in this survey. Tempdb is a whole different kettle of fish (excellent British phrase!), where multiple data files can be required to alleviate in-memory contention for allocation bitmaps (classic PAGELATCH_UP/EX contention). For tempdb guidelines see: Tempdb configuration survey results and advice.
Data Files vs. Database Size
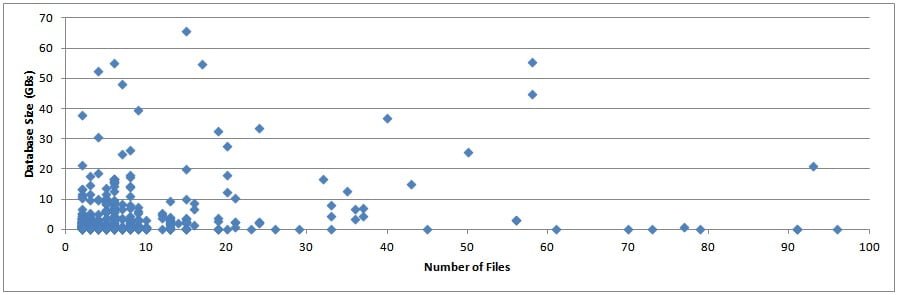
This is also really interesting. Without knowing what these databases are being used for, it seems that many of these databases have too many files for the size of the database (my gut feel, based on experience). My guess is that the file/filegroup layout was chosen based on rules that don’t equate to the normal reasons for having multiple file/filegroups, as I described above. What’s particularly surprising is the number of database less than 1-GB in size that have many, many data files.
Summary
So how many data files and filegroups should you have? There’s no right answer, and the sweet spot is going to vary for all of you.
Some general rules of thumb:
- As your databases get larger, it becomes more likely that you’re going to need multiple files and filegroups
- Multiple filegroups give you enhanced possibilities for targeted disaster recovery, easier manageability, and I/O subsystem placement
- Each filegroup should have 2-4 files at least, with tempdb being a special case
Whatever you do, don’t forget to test to figure out the optimal configuration for your workload.
29 thoughts on “Files and filegroups survey results”
We have a 45Gb database I found that not only using different filegroups is awesome about performance and mostly parallel IO in RAID 10 but also fragmentation is a big win !!
We create different operating system partitions and in each partition we have a filegroup. Each filegroup contains only a table and her indexes
For example a 8Gb table is on a filegroup that is on a SO partition of 25GB another filegroup of 6Gb in a partition of 20GB etc
Using this when adding records to the biggest tables there is no more mixed records and the records get a continious aligment in the DB, reducing defrag times and faster scans, if the 8GB is on the main filegroup so defagmenting the table makes the db a lot bigger and also creating holes in the DB
Is that a good policy ? We will be splint OLTP and back mantenience tables in different filegroups based on ur suggestion for fast restores
If you’ve got a table and its indexes in the same filegroup, then the extent contiguity isn’t going to be any better than having multiple tables and indexes mixed in a filegroup. It’s not a model I’d recommend, but if you’ve done benchmarking and determined that this layout gives you the best possible performance, and you’ve deemed the complexity worthwhile, then go for it.
Paul, you are right but most of the tables just use the cluster index, and the others have a fill factor on indexes that allow not too much defrag, are only splited after a ton of ops and get defragmented on weekends :)
But about SO partitions, is a good policy or anyway in the same SO partition the filegroups can work fine, ie, using a partition we can ensure that defragmenting the indexes we get physical continuity with filegroups in same partition the filegroup can physical defrag but logical continuity ?
Thanks !! you rock !!
I wasn’t talking about fragmentation, I was talking about extent contiguity.
I don’t know what you mean by ‘SO’ – I’ve never heard that term before.
Sorry for the wrong terms paul, I need to enhace a bit my speach :P we are talking about the same thing but different words
About SO I misspelled it: “OS” Operating System partition
Thanks for all ur articles and replies :)
Marcos (Argentina)
I still don’t know what you mean I’m afraid, even with that clarification.
I ask if u only have a mirrored disk, ie, u can’t span the filegroups in different IO subsystems because is only one, is a good practice to use disk partitions for each filegroup ? so the files in a filegroup can acomodate in that partition easying the file operations ?
Thanks !!
No – I’d keep it simple by just using a single partition.
Hi Paul,
Would you still recommend 2-4 files for a single filegroup on a single LUN on a SAN striped across many spindles if there was no noticable PFS, GAM or SGAM contention?
Rob
Yes – the 2-4 files at least has nothing to do with in-memory bitmap contention, it’s just to parallelize I/Os and spread out the write points when checkpoints occur. That was the scenario in the benchmark posts I linked to.
Hi Paul,
Hope I’m reading this right. You’re saying 2-4 data files for in single filegroup on a single LUN performs better than 1 data file in a single filegroup on a single LUN because of I/O parallelization?
Doesn’t I/O parallelization happen if they’re on separate LUN? Is this I/O parallelization is some sort of SQL internal code? i.e. one worker thread for each data file? I thought this was a myth.
Thanks,
Joe
Yes, I’m saying exactly that. But not because of multiple threads (which is a myth), because the I/Os being done by checkpoint are hitting multiple points on multiple drives and so there isn’t an insertion point hot spot. My benchmarking numbers show exactly that, and there is plenty of other client evidence showing the same thing.
Thanks Paul, I get it now. The multiple data file is to spread the write points when checkpoints occur, and that makes sense.
Cheers,
Joe
I’m confused. You said “the I/Os being done by checkpoint are hitting multiple points on multiple drives” and it’s good for performance. I think the question involved only ONE drive. I’m certainly no expert on drive technology, but I do not understand how ONE drive could be hit at multiple points unless ONE drive has multiple independent read/write heads and a controller to handle them. Please clarify what you mean. Is there any benefit in having more than one data file on the same drive? Thanks!
Right – this only applies if you have multiple drives – a single drive is going to degrade performance with multiple files. But you have other problems – with a single drive you have no redundancy at all so you’re living on a knife-edge all the time.
I’m still confused, but now for a different reason. You said “with a single drive you have no redundancy”, but maybe we are defining “drive” differently. The OS may see one “drive”, even if the one “drive” consists of several hard disks in a RAID configuration. Such a “drive” would have all the necessary redundancy, but it still seems like it’s not going to improve performance to have multiple database files. I think the RAID controller would spread writes across the hard disks the way it sees fit, without regard for database files. I think multiple files applies to situations where there’s a “drive” to host each file. Am I misunderstanding something? Thanks!
Yes, I mean a single physical drive. When you have a RAID array with several drives, multiple data files gives better performance, as I’ve proven previously.
Paul, After reading this I’m trying visualize how to put this in practice with a large database (4+TB) spread across several 1-TB SAN drives. My first thought is a strategy that would essentially stripe the file groups across the drives. i.e. FG1 files on drives a, b, c. FG2 has files on drives b,c,d. FG3 has files on drives c,d,e, etc. Am I missing something? What are the problems/pitfalls with a strategy like this?
Thanks.
Is each drive an individual spinning disk or a RAID array? What targeted restores do you need to be able to do? How do you need to split up index maintenance? Are you using partitioning? Are there performance issues? The answers to all these questions play into your physical layout. I certainly would never have filegroups overlapping on the same sets of storage – that’s a recipe for disaster if something goes wrong with one of the drives (e.g. drive c in your example above) – you lose all the filegroups in one go.
Hi Paul, Thanks for the survey very interesting. Am I correct in saying that this should not be seen as a way of saving space, If I have 100GB MDF database file and create 4 X 20GB NDF files in separate filegroups on different drives. After I have completed this, I am still left 100GB MDF File and even though 80GB maybe free this file should not be shrunk.
A filegroup can contain more than one file, file can be specified when creating a data table to put the data on the filegroup ,but the data can save the file that you want to put on a file? Thanks!
I don’t understand “but the data can save the file that you want to put on a file?”. Can you rephrase it please?
Paul,
If I have a single RAID array visible to the OS as a single drive (say drive F:), with my database file and file group on that drive and I purchase a second set of RAID arrays to give me one more drive (say G:).
What would be the best use of my capital outlay for drive G: – should I create a 2nd file group and point it to G: and move some tables to that file group, or would I get a better performance improvement if I added a 2nd data file (NDF file) on G: and have SQL proportionally fill both F: and G: with data – giving me a boost with some I/O concurrency?
I don’t have a particularly strong requirement for maintenance partitioning (like backups that run too long(, so i don’t really have a need to use that feature of the extra file group.
As a twist, what do you think would be faster – adding the 2nd data file on G:, or say adding a 2nd file group on G: and in this case specifying that all clustered indexes go on 1 file group and all non-clustered indexes on the other file group?
It’s impossible to say for sure without knowing your workload and the capabilities of the I/O subsystem. Generalizations are to have 2-4 files in a filegroup instead of one, and to separate log from data, but again, that may not make any difference to the performance of your workload. Best approach is always to test various configs and see which gives best perf for your environment.
Hi Paul – thanks for these helpful articles. I’ve been reading most of sqlskills over two days trying to find advice to fix my problem. We inherited a DB that caught fire when the TX log reached 600GB and filled the disk. Also about to delete 1000+ _dta_xxxx hypothetical and applied indices which will free significant data space.
My question: What is the best way to consolidate NDFs? I discovered that PRIMARY fg has “too many” same-sized files on same volume (SAN LUN) – totaling 400GB.
After reading your “don’t shrink the data” — DBCC SHRINK EMPTYFILE still seems to be my solution – followed by plenty of REBUILD. But I found another article where you suggest using ALTER TABLE to move to a new FG to reduce fragmentation effects – but there are 100’s of tables and 1000’s of indices (yeah I could script this).
There aren’t any partitions or other obvious reasons for this structure (I suspect 1 file per CPU myth). For mostly maintenance/complexity reasons I want to reduce the number of files to 4 – for example auto-grow fires multiple times per day for 20MB growth (times each file). Changing this param requires “too many” ALTER statements. Your benchmark posts suggest 4 or 8 are a sweet spot.
Thanks.
Ugh – either method (rebuild into new filegroup or shrink plus reorganize to remove fragmentation) is going to require scripting unless you already have a fragmentation removal job that you can run after shrinking. It really depends on your workload, ability to cope with lots of transaction log being generated, and so on, which one you choose. I’d really be tempted to create a new filegroup and CREATE INDEX … WITH (DROP_EXISTSING=ON) the indexes into the new filegroup, leaving the primary as small as possible.
Hi Paul!
Thank you for your information.
Is there a way to remove the filegroup with defunct data files.
Data files became DEFUNCT during the piecemeal restore for database in simple recovery model.
Nonclustered indexes was resident in the defunct data files.
The filegroup is offline.
The first result in a Google search takes you to the Microsoft docs…
Thanks for your reply!
Yes, but it not work.
I can’t do any operation on it because it’s offline