A long time ago, in a blog post far, far away (well before I went offline in July) I kicked off a weekly survey about how often you run consistency checks (see here for the survey). Now I'm back online again, and so here are the results as of 8/3/09.
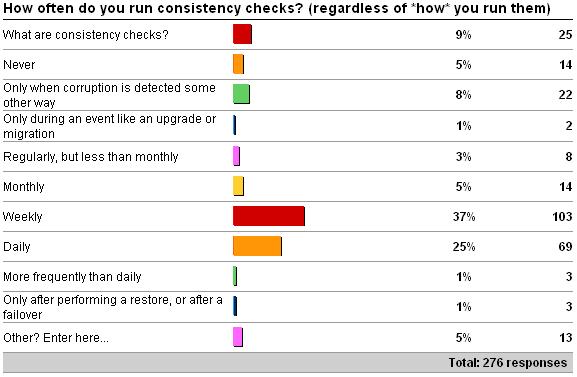
The results are actually surprising – I didn't expect so many people to be running consistency checks so frequently – 25% daily and another 37% weekly – very cool!
Check It Out!

The number of people who don't know what consistency checks are may look a little depressing but I think it's probably a symptom of the number of people coming into the SQL world as involuntary DBAs. For those people, consistency checks are a way of proactively checking for database corruption, which is nearly always caused by the I/O subsystem. You can read a good introduction to consistency checking and other database maintenance topics in the article I wrote for TechNet Magazine in August 2008 – Top Tips for Effective Database Maintenance and bit more in the previous survey Importance of how you run consistency checks.
Basically you need to run regular consistency checks. There's a myth that you don't need to run consistency checks – this was perpetuated by various marketing folks when SQL 7.0 shipped, because SQL 6.5 used to cause allocation corruptions and the rewrite for 7.0 removed all the corruption problems. Now, of course there have been bugs in SQL Server that cause problems, but they account for a tiny fraction of the corruptions out there. Nearly all corruptions are caused by something going wrong in the I/O subsystem – and you can't predict when that will or won't happen. Jim Gray once likened the disk heads in a hard drive as akin to a 747 flying at 500mph 1/4 inch above the ground – scary stuff. You DO need to run consistency checks, because corruptions do happen. You can read more about the causes of corruptions in this blog post: Search Engine Q&A #26: Myths around causing corruption.
So – how often should you run consistency checks? Well, it depends. When I'm teaching I like to give two examples:
-
You have a dodgy I/O subsystem that is causing corruptions. You have no backups. You have a zero data-loss requirement. With no backups, your only way to get rid of corruptions is to run repair, which usually leads to data loss (see Misconceptions around database repair). In that case, you want to know about corruption as soon as possible to limit the amount of data loss from running repair. Contrived example for sure, but you'd be surprised what I've seen…
-
You have a rock-solid I/O subsystem, with all drivers and firmware up-to-date. You have a comprehensive backup strategy which you've extensively tested and you've confident you can recover from corruptions with zero-to-minimal downtime and data loss. In this case you may be comfortable running consistency checks once a week, say.
The overwhelming factor in how often to run consistency checks is you. How comfortable are you with the integrity of your I/O subsystem and your ability to recover from a corruption problem. If you have corruptions in your database today, you'll probably run DBCC CHECKDB on it every day for a month, right?!?
Part of any database maintenance of high-availability strategy is proactively making sure that corruption doesn't exist in the database – otherwise when you DO discover it, it may be more pervasive and it will take you longer to recover, and potentially with more downtime. Therefore the answer really is that you should run it as often as you can. Sometimes that can be difficult for very large databases (your definition is likely to be different than mine – I think 500GB and larger – depends on your hardware etc) as CHECKDB can take a long time to run (see CHECKDB From Every Angle: How long will CHECKDB take to run?), but there are ways you can effectively consistency check even a VLDB – see CHECKDB From Every Angle: Consistency Checking Options for a VLDB.
So – I'm very pleased to see so many people running regular consistency checks. However, maybe I'm just a pessimist but I did expect some of the less than optimal options to have higher numbers. Let's look at each in turn.
Only when corruption is detected some other way. By the time corruption has occurred and is detected through regular operations, it's likely to be more pervasive. Many databases do not see all their data read/updated as part of regular operations, which means that if a part of the database that's not used for a while gets corrupted, and you're not running consistency checks, you're not going to know. That means you're not going to know that your I/O subsystem is causing problems – and so more corruption will occur. You might think this isn't a big deal, but it can be depending on what part of the database (or maybe system databases) gets corrupted. Some things can be restored or repaired relatively simply – but what if, say, the boot page of master is corrupted? Your entire instance is down until you sort that out. It's always better to proactively discover corruption before it hits you in a way that really messes you up.
Only during an event like an upgrade or migration. In this category I see people running consistency checks AFTER doing an upgrade but not before. From release to release, DBCC CHECKDB has improved – especially from 2000 to 2005, where system catalog consistency checks were added. If you run consistency checks after an upgrade and find the database is corrupt, what do you do? Run repair? Go back to the earlier version and run repair? Restore your backups? The odds are that if you've got corruption, it's also in your backups too. Also, you may think that the upgrade itself caused the corruption – I've never seen this. It's always been that the corruption was there before and only got discovered after the upgrade. Always run consistency checks BEFORE doing an upgrade – to make sure you've got a chance of putting things right before (potentially irrevocably) moving to the newer version.
Only after performing a restore, or after a failover. This is, of course, a good practice, but shouldn't be the only time a consistency check is performed – for most of the same reasons as I've explained above. What do you do if the database is found to be corrupt after restoring backups? You're looking at data loss now.
To summarize: make sure you're running regular consistency checks – with the regularity in-line with your comfort zone and your maintenance/high-availability strategies.
Next up – the next survey!
8 thoughts on “Importance of running regular consistency checks”
Hi Paul,
I have a question on your suggestion under the header: –Only when corruption is detected some other way–
If the database is corrupt will it not go to suspect mode? We have tools to alert us when the database goes suspect or inaccessible. At that time we can jump in and decide whether its worth even running a checkdb or simlpy do a point in time restore. if log file is corrupt we will loose data anyway even if we run checkdb(i.e. point in time recovery will not be possible).
So, are there any consistency errors that won’t take the database into suspect mode and we will not know about those errors until the checkdb would run.
Kind Regards
Abhay
Kind Regards
Abhay
A database will only go suspect because of a corruption that prevents a transaction rolling back, or some corruptions that are detected on critical pages in the database (boot page, some allocation bitmaps). Table corruptions will not set the database suspect unless a transaction rollback fails.
So you mean that there will be situations where the corruption would be caused but there are high chances that we will not know about it because it may take good time for that to surface(i.e. until rollback or commit failure)? I’m sorry to be pedantic here but just trying to understand this a bit more (and thanks a lot for your time).
Situation 1: We run checkdb once a day. Lets say the database got corrupt moments after a daily checkdb finished and came out clean. Now next checkdb wold run after 24 hours. Based on your experience Paul, what are the chances that we will not detect it i.e. error in the T-log or database going suspect before the next checkdb kick off in another 24 hours. This is on the critical DB.
Situation 2: We run checkdb once a week. Rest of the situation is same i.e. are there good chances that we will live with corruption for a week and there will be no messages anywhere that the database is corrupt? And then we will see it in checkdb?
Correct, this is why regular consistency checks are necessary.
1) High, unless by some chance the workload hits the corrupt page(s). The chance increases as the database gets bigger and the daily workload touches a smaller proportion of the database.
2) Correct.
Roger that. Thanks a ton!