Way back in the mists of time, at the end of the last century, I wrote DBCC SHOWCONTIG for SQL Server 2000, to complement my new invention DBCC INDEXDEFRAG.
I also used to wear shorts all the time, with luminous orange, yellow, or green socks.
Many things change – I now have (some) dress sense, for one. One other thing that changed was that DMVs came onto the scene with SQL Server 2005. DBCC SHOWCONTIG was replaced by sys.dm_db_index_physical_stats. Under the covers though, they both use the same code – and the I/O characteristics haven’t changed.
Check It Out!

This is a blog post I’ve been meaning to do for a while now, and I finally had the impetus to do it when I heard about today’s T-SQL Tuesday on I/O in general being run by Mike Walsh (Twitter|blog). It’s a neat idea so I decided to join in this time. In retrospect, reading this over before hitting ‘publish’, I got a bit carried away (spending two hours on this) – but it’s one of my babies, so I’m entitled to! :-)
This isn’t a post about how to use DMVs in general, how to use this DMV in particular, or anything about index fragmentation. This is a blog post about how the DMV works.
DMV is a catch-all phrase that most people (myself included) use to describe all the various utility views in SQL Server 2005 and 2008. DMV = Dynamic Management View. There’s a catch with the catch-all though – some of the DMVs aren’t views at all, they’re functions. A pure DMV gets info from SQL Server’s memory (or system tables) and displays it in some form. A DMF, on the other hand, has to go and so some work before it can give you some results. The sys.dm_db_index_physical_stats DMV (which I’m going to call ‘the DMV’ from now on) is by far the most expensive of these – but only in terms of I/O.
The idea of the DMV is to display physical attributes of indexes (and the special case of a heap) – to do this it has to scan the pages comprising the index, calculating statistics as it goes. Many DMVs support what’s called predicate pushdown, which means if you specify a WHERE clause, the DMV takes that into account as it prepares the information. This DMV doesn’t. If you ask it for only the indexes in the database that have logical fragmentation > 30%, it will scan all the indexes, and then just tell you about those meeting your criteria. It has to do this because it has no way of knowing which ones meet your criteria until it analyzes them – so can’t support predicate pushdown.
This is where understanding what it’s doing under the covers comes in – the meat of this post.
LIMITED
The default operating mode of the DMV is called LIMITED. Kimberly always makes fun of the equivalent option for DBCC SHOWCONTIG, which I named as a young and foolish developer – calling it WITH FAST. Hey – it’s descriptive!
The LIMITED mode can only return the logical fragmentation of the leaf level plus the page count. It doesn’t actually read the leaf level. It makes use of the fact that the next level up in the index contains a key-ordered list of page IDs of the pages at the leaf level – so it’s trivial to examine the key-ordered list and see if the page IDs are also in allocation order or not, thus calculating logical fragmentation.
The idea behind this option is to allow you to find the fragmentation of an index by reading the minimum number of pages, i.e. in the smallest amount of time. This option can be magnitudes faster than using the DETAILED mode scan, and it depends on how big the index’s fanout is. Without getting too much into the guts of indexes, the fanout is based on the index key size, and determines the number of child-page pointers an index page can hold (e.g. the number of leaf-level pages that a page in the next level up has information about).
Consider an index with a char(800) key. Each entry in a page in the level above the leaf has to include a key value (the lowest key that can possibly appear on the page being referred to), plus a page ID, plus record overhead, plus slot array entry – so 812 bytes. So a page can only hold 8096/812 = 9 such entries. The fanout is at most 9.
Consider an index with a bigint key. Each entry is 13 bytes, so a page can hold 8096/13 = 622 entries. The fanout is at most 622, but will likely be smaller, depending on operations on the index causing fragmentation at the non-leaf levels.
For a table with 1 million pages at the leaf level, the first index will have 1 million/9 = 111112 pages at least at the level above the leaf. The second index will have at least 1608 pages. The savings in I/O from using the LIMITED mode scan will clearly differ based on the fanout.
I’ve created a 100GB clustered index (on the same hardware as I’m using for the benchmarking series) with 13421760 leaf-level pages and a maximum fanout of 540. In reality, I populated the index using 16 concurrent threads, so there’s some fragmentation. The level above the leaf has 63012 pages, an effective fanout of 213. Still, the LIMITED mode scan will read 213x less than a DETAILED scan, but will it be 213x faster?
Here’s a perfmon capture of the LIMITED mode scan on my index:
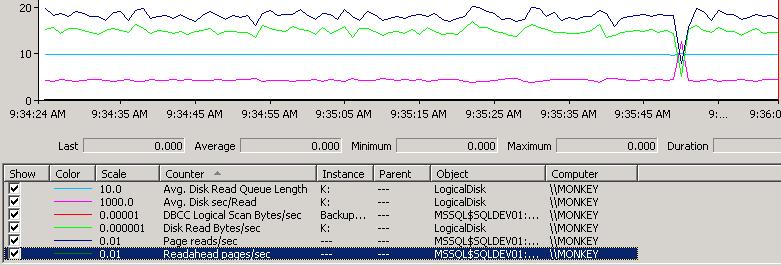
There’s nothing special going on under the covers in a LIMITED mode scan – the chain of pages at the level above the leaf is read in page-linkage order, with no readahead. The perfmon capture shows:
- Avg. Disk Read Queue Length (light blue) is a steady 1.
- Avg. disk sec/Read (pink) is a steady 4ms.
- Disk Read Bytes/sec (green) is roughly 14.5million.
- Page reads/sec (dark blue) is roughly 1800.
DETAILED
The DETAILED mode does two things:
- Calculate fragmentation by doing a LIMITED mode scan
- Calculate all other statistics by reading all pages at every level of the index
And so it’s obviously the slowest. It has to do the LIMITED mode scan first to be able to calculate the logical fragmentation, because it reads the leaf level pages in the fastest possible way – in allocation order. DBCC has a customized read-ahead mechanism for allocation order scans that it uses for this DMV and for DBCC CHECK* commands. It’s *incredibly* aggressive and will hit the disks as hard as it possibly can, especially with DBCC CHECK* running in parallel.
Here’s a perfmon capture of the DETAILED mode scan on my index:
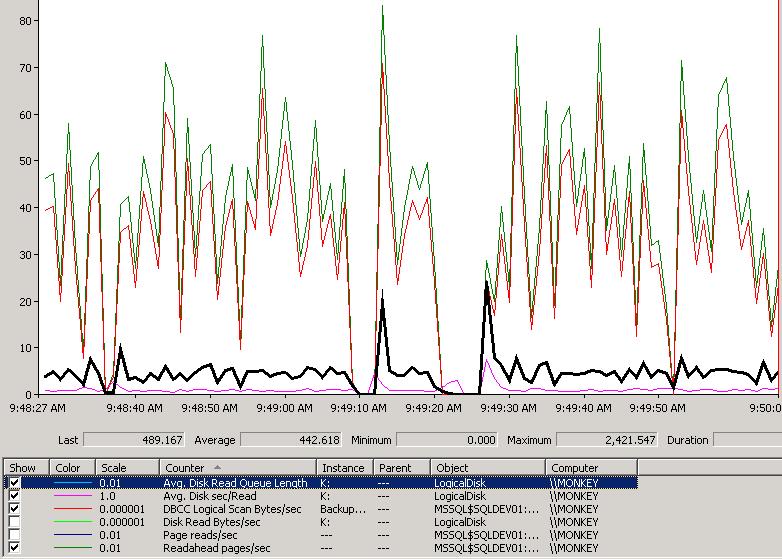
Not quite as pretty as the LIMITED mode scan, but I like it :-) Here’s what it’s showing:
- Avg. Disk Read Queue Length (black) is in the multiple hundreds. Clearly its appetite for data is outstripping what my RAID array can do. It basically tries to saturate the I/O subsystem to get as much data as possible flowing into SQL Server.
- Avg. disk sec/Read (pink line at the bottom) is actually measuring in whole seconds, rather than ms. Given the disk queue length, I’d expect that.
- DBCC Logical Scan Bytes/sec (red) varies substantially as the readahead mechanism throttles up and down, but it’s driving anywhere up to 80MB/sec. You can see around 9:49:20 AM when it drops to zero for a few seconds.
- Readahead pages/sec (green) is tracking the DBCC scan. This is a buffer pool counter, the DBCC one is an Access Methods counter (the dev team I used to run during 2005 development). If I had Disk Read Bytes/sec and Pages reads/sec showing, they’d track the other two perfectly – I turned them off for clarity.
So the DETAILED mode not only reads more data, but it does it a heck of a lot more aggressively so has a much more detrimental effect on the overall I/O capabilities of the system while it’s running.
SAMPLED
There is a third mode that was introduced just for the DMV. The idea is that if you have a very large table and you want an idea of some of the leaf level statistics, but you don’t want to take the perf hit of running a DETAILED scan, you can use this mode. It does:
- LIMITED mode scan
- If the number of leaf level pages is < 10000, read all the pages, otherwise read every 100th pages (i.e. a 1% sample)
Summary
There’s no progress reporting from the DMV (or DBCC SHOWCONTIG) but if you look at the reads column in sys.dm_exec_sessions you can see how far through the operation it is. This method works best for DETAILED scans, where can compare that number against the in_row_data_page_count for the index in sys.dm_db_partition_stats (yes, you’ll need to mess around a bit if the index is actually partitioned).
In terms of timing, I ran all three scan modes to completion. The results:
- LIMITED mode: 282 seconds
- SAMPLED mode: 414 seconds
- DETAILED mode: 3700 seconds
Although the LIMITED mode scan read roughly 200x less than the DETAILED scan, it was only 13 times faster, because the readahead mechanism for the DETAILED scan is way more efficient than the (necessary) follow-the-page-linkages scan of the LIMITED mode.
Just for kicks, I ran a SELECT COUNT(*) on the index to see how the regular Access Methods readahead mechanism would fare – it completed in 3870 seconds – 5% slower, and it had less processing to do than the DMV. Clearly DBCC rules! :-)
Although the DETAILED mode gives the most comprehensive output, it has to do the most work. For very large indexes, this could mean that your buffer pool is thrashed by the lazy writer making space available for the DMV to read and process the pages (it won’t flush out the buffer pool though, as the pages read in for the DMV are the first ones the lazywriter will kick out again). One of the reasons I advise people to only run the DMV on indexes they know they’re interested in – and better yet, run it on a restored backup of the database.
Hope this is helpful!
PS Oh, also beware of using the SSMS fragmentation wizard. It uses a SAMPLED mode scan, but I found it impossible to cancel!
15 thoughts on “Inside sys.dm_db_index_physical_stats”
Thanks for your post! I still have to read in detail but it looks good. I just noticed something I missed the first time… The whole fellow-MVP part. Not me :-) There is a Mike Walsh who is an MVP in the SharePoint world (though I should get some points for spelling SharePoint "right"). He is a different Mike Walsh, however.
Sounded nice, though = )
Nice, detailed post. Yes, the SSMS Fragmentation wizard is quite evil, I learned my lesson a while back, and I never use that. T-SQL is the only way to go when running sys.dm_db_index_physical_stats
What about a SMO objects in PowerShell, it uses the DMV with LIMITED…
Hi Paul,
I´ve been using for a long time the detailed mode for searching for fragmented indexes. So, if any level of an indexes is fragmented, i make a rebuild or reorg based in avg_fragmentation_in_percent. Am i exaggerating in this criteria? Should i just consider leaf level?
Regards
Andre
Quoted from above:
“The DETAILED mode does two things:
•Calculate fragmentation by doing a LIMITED mode scan
•Calculate all other statistics by reading all pages at every level of the index”
If this is the case, then why does sys.dm_db_index_physical_stats (7, NULL, NULL, NULL, ‘LIMITED’) calculate a different avg_fragmentation_in_percent, fragment_count, and page_count than sys.dm_db_index_physical_stats (7, NULL, NULL, NULL, ‘DETAILED’)
It doesn’t. The fact that you’re saying the page count is different is telling me that in between runs of the DMV, or even while the DMV is running, the index is changing. This is especially likely given that you’re running the DMV on all indexes on all tables in the database.
Running sys.dm_db_index_physical_stats (7, NULL, NULL, NULL, ‘DETAILED’) returns two sets of results, one for the leaflevel (level 0) and one for the B-Tree (level 1). These may vary significantly. Like 3.5% at the leaflevel but 95% at the B-Tree level.
The big question for me is: Should one use the LIMITED (level 0) results to decide on Rebuild/Reorg/Stats, or the level 1 results, or some average? From my research it looks like most DBAs use the LIMITED option.
Generally most people use the LIMITED mode, as it’s the leaf level fragmentation that can cause problems, not non-leaf levels. But don’t discount the possibility of perf issues from wasted page space where there isn’t logical fragmentation – see https://www.sqlskills.com/blogs/paul/performance-issues-from-wasted-buffer-pool-memory/
I’ve around 340 GB DB, for which I’ve ran sys.dm_db_index_physical_stats for 50 mins and stopped it. Now it is almost 4 hours but it is not stopping.
Can I kill it using activity monitor?
It should just stop – so you can try killing the SPID.
Thank you for your reply.
I’ve Killed SPID but the query window is still showing as “Cancelling Query”. I do not see this query anymore in Activity Monitor.
Please advice if I should just close my SSMS window and it should be fine or there is anything to concern about this.
Thank you once again.
In terms of locking… Is it better to determine fragmentation in a table-by-table manner (exec sys.dm_db_index_physical_stats (, ,NULL, NULL, NULL), or just in one step, for the whole database (exec sys.dm_db_index_physical_stats (, NULL, NULL, NULL, NULL)? My gut feeling is that the latter can take considerable time, compared to the former.
Also, I always do a reorg/rebuild of indexes on a table, starting with a clustered index first.
No – only run the DMV on indexes that you know removing fragmentation will help workload performance.
With all the different workloads that a database suffers, it there an automatic (easy) method to determine which indexes will actually provide a performance benefit to any workload?
My “feeling” is “No” but I thought I’d ask the guy (you) that knows more about this type of thing than anyone else.
I don’t know of an automatic way of doing that as there are a lot of variables to consider to know whether general performance increased because of defragging an index.