(Check out my Pluralsight online training course: SQL Server: Performance Troubleshooting Using Wait Statistics and my comprehensive library of all wait types and latch classes.)
Back in May I kicked off a survey about prevalent latches on SQL Server instances across the world (see here). It’s taken me quite a while to get around to collating and blogging about the results, but here they are at last!
I got information back for almost 600 servers, and if you remember, I gave you some code to run that would output the top non-page latches that are being waited on during LATCH_XX waits. Non-page latches are those that are neither PAGELATCH_XX (waiting for access to an in-memory copy of a data-file page) nor PAGEIOLATCH_XX (waiting for a data file page to be read into memory from disk).
Check It Out!

Every non-page data structure in SQL Server that must be thread-safe (i.e. can be accessed by multiple threads) must have a synchronization mechanism associated with it – either a latch or a spinlock. I blogged about spinlocks last year – see – and they’re used for some data structures that are accessed so frequently, and for such a short time, that even the expense of acquiring a latch is too high. Access to all other data structures is controlled through a latch.
Using wait statistics analysis (see here), if you’re seeing LATCH_EX or LATCH_SH wait types are one of the top 3-4 prevalent wait types, contention for a latch might be contributing to performance issues. If that is the case, you’ll need to use sys.dm_os_latch stats to figure out what the most prevalent latch is – using code similar to that below (with some example output):
/*============================================================================
File: LatchStats.sql
Summary: Snapshot of Latch stats
SQL Server Versions: 2005 onwards
------------------------------------------------------------------------------
Written by Paul S. Randal, SQLskills.com
(c) 2015, SQLskills.com. All rights reserved.
For more scripts and sample code, check out
http://www.SQLskills.com
You may alter this code for your own *non-commercial* purposes. You may
republish altered code as long as you include this copyright and give due
credit, but you must obtain prior permission before blogging this code.
THIS CODE AND INFORMATION ARE PROVIDED "AS IS" WITHOUT WARRANTY OF
ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED
TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A
PARTICULAR PURPOSE.
============================================================================*/
WITH [Latches] AS
(SELECT
[latch_class],
[wait_time_ms] / 1000.0 AS [WaitS],
[waiting_requests_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_latch_stats
WHERE [latch_class] NOT IN (
N'BUFFER')
AND [wait_time_ms] > 0
)
SELECT
MAX ([W1].[latch_class]) AS [LatchClass],
CAST (MAX ([W1].[WaitS]) AS DECIMAL(14, 2)) AS [Wait_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL(14, 2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (14, 4)) AS [AvgWait_S]
FROM [Latches] AS [W1]
INNER JOIN [Latches] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
LatchClass Wait_S WaitCount Percentage AvgWait_S ——————————— ——- ———- ———– ———- LOG_MANAGER 221.43 4659 45.81 0.0475 ACCESS_METHODS_HOBT_VIRTUAL_ROOT 199.56 7017 41.28 0.0284 FGCB_ADD_REMOVE 35.17 1047 7.27 0.0336 DBCC_OBJECT_METADATA 26.85 256490 5.55 0.0001
You can also see the latch class of the latches being waited for in the resource_description column of sys.dm_os_waiting_tasks DMV when the wait_type column is LATCH_XX.
The survey results are based on running this code, for latch classes that are the top latch class on 10 or more servers.
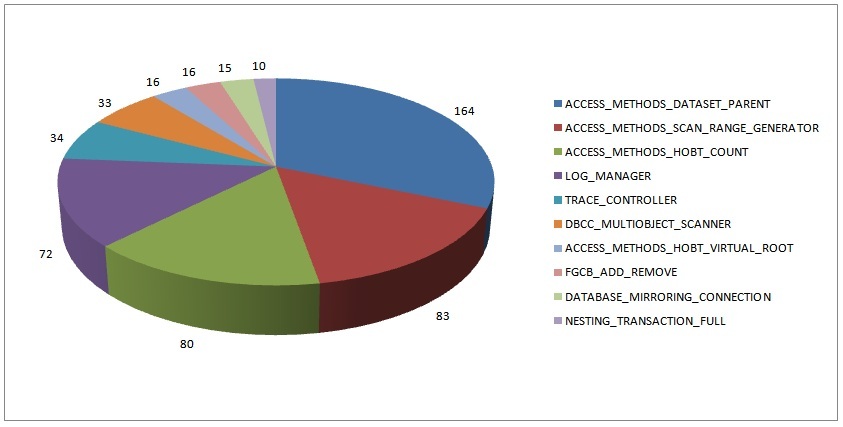
Just like the wait statistics survey results from 2010, I’m not surprised by these results as we see these over and over on client systems.
For the remainder of this post I’m going to list the 10 latch classes represented in the data above in descending order and explain what they mean. Some of this information is from my knowledge of the internals and some of it is from catching the point that latches are acquired using Extended Events and callstack dumping.
Note that when I’m describing a latch class, there may be many instances of that particular latch class. For instance, an FGCB_ADD_REMOVE latch exists for each filegroup in each database attached to the instance.
- 164: ACCESS_METHODS_DATASET_PARENT
- 83: ACCESS_METHODS_SCAN_RANGE_GENERATOR
- These two latches are used during parallel scans to give each thread a range of page IDs to scan. The LATCH_XX waits for these latches will typically appear with CXPACKET waits and PAGEIOLATCH_XX waits (if the data being scanned is not memory-resident). Use normal parallelism troubleshooting methods to investigate further (e.g. is the parallelism warranted? maybe increase ‘cost threshold for parallelism’, lower MAXDOP, use a MAXDOP hint, use Resource Governor to limit DOP using a workload group with a MAX_DOP limit. Did a plan change from index seeks to parallel table scans because a tipping point was reached or a plan recompiled with an atypical SP parameter or poor statistics? Do NOT knee-jerk and set server MAXDOP to 1 – that’s some of the worst advice I see on the Internet.)
- 80: ACCESS_METHODS_HOBT_COUNT
- This latch is used to flush out page and row count deltas for a HoBt (Heap-or-B-tree) to the Storage Engine metadata tables. Contention would indicate *lots* of small, concurrent DML operations on a single table.
- 72: LOG_MANAGER
- If you see this latch it is almost certainly because a transaction log is growing because it could not clear/truncate for some reason. Find the database where the log is growing and then figure out what’s preventing log clearing using: SELECT [log_reuse_wait_desc] FROM sys.databases WHERE [name] = N’youdbname’
- 34: TRACE_CONTROLLER
- This latch is used by SQL Trace for myriad different things, including just generating trace events. Contention on this latch would imply that there are multiple traces on the server tracing lots of stuff – i.e. you’re over-tracing.
- 33: DBCC_MULTIOBJECT_SCANNER
- This latch appears on Enterprise Edition when DBCC CHECK* commands are allowed to run in parallel. It is used by threads to request the next data file page to process. Late last year this was identified as a major contention point inside DBCC CHECK* and there was work done to reduce the contention and make DBCC CHECK* run faster. See KB article 2634571 and Bob Ward’s write-up for more details.
- 16: ACCESS_METHODS_HOBT_VIRTUAL_ROOT
- This latch is used to access the metadata for an index that contains the page ID of the index’s root page. Contention on this latch can occur when a B-tree root page split occurs (requiring the latch in EX mode) and threads wanting to navigate down the B-tree (requiring the latch in SH mode) have to wait. This could be from very fast population of a small index using many concurrent connections, with or without page splits from random key values causing cascading page splits (from leaf to root).
- 16: FGCB_ADD_REMOVE
- FGCB stands for File Group Control Block. This latch is required whenever a file is added or dropped from the filegroup, whenever a file is grown (manually or automatically), when recalculating proportional-fill weightings, and when cycling through the files in the filegroup as part of round-robin allocation. If you’re seeing this, the most common cause is that there’s a lot of file auto-growth happening. It could also be from a filegroup with lots of file (e.g. the primary filegroup in tempdb) where there are thousands of concurrent connections doing allocations. The proportional-fill weightings are recalculated every 8192 allocations, so there’s the possibility of a slowdown with frequent recalculations over many files.
- 15: DATABASE_MIRRORING_CONNECTION
- This latch is involved in controlling the message flow for database mirroring sessions on a server. If this latch is prevalent, I would suspect there are too many busy database mirroring sessions on the server.
- 10: NESTING_TRANSACTION_FULL
- This latch, along with NESTING_TRANSACTION_READONLY, is used to control access to transaction description structures (called an XDES) for parallel nested transactions. The _FULL is for a transaction that’s ‘active’, i.e. it’s changed the database (usually for an index build/rebuild), and that makes the _READONLY description obvious. A query that involves a parallel operator must start a sub-transaction for each parallel thread that is used – these transactions are sub-transactions of the parallel nested transaction. For contention on these, I’d investigate unwanted parallelism but I don’t have a definite “it’s usually this problem”. Also check out the comments for some info about these also sometimes being a problem when RCSI is used.
I hope you found this interesting and it helps you out with your performance troubleshooting!
48 thoughts on “Most common latch classes and what they mean”
Wow great stuff. Can you recommend any good articles on normal parallelism troubleshooting methods?
The NESTING_TRANSACTION_* latches have to do with RCSI. I’ve fought with them quite a bit over the last couple of years and ended up working with product support, although it’s still unclear to me whether the contention that I regularly see on them is a bug or not. Regardless, the solution is to not use RCSI; changing isolation level to READ COMMITTED (using the READCOMMITTED table hint), READ UNCOMMITTED, or even full SNAPSHOT, solves the problem in every case I’ve seen to date.
I’m seeing a lot of ACCESS_METHODS_DATASET_PARENT latches. We haven’t gotten reports about performance issues, but if we’ve got a problem I’d like to try to fix it preemptively.
Is there a way to find out what queries/tables/databases are causing those latches, other than running sys.dm_os_waiting_tasks repeatedly and hoping to see it in action?
Cool! I’ll watch for his post.
Nothing specific that I’ve blogged about but I added some suggestions inline in the post.
Yup – under some circumstances the transaction manager will use parallel nested transactions when scanning version chains too. They’re not *specifically* to do with RCSI though, that’s just one of the times this transaction type is used. Trace stack calls and you’ll see them popping up when there’s no RCSI on the system. I haven’t seen this be a problem with RCSI yet – good knowledge to add to the general corpus – thanks Adam.
Apart from that you could run an extended events package that look for that latch class in the latch_suspend_begin event from 2008 onwards – Jon’s writing a blog post about it that I’ll link in when it’s published later this morning.
Big thanks for completing the survey with an excellent post about the details and causes!!!
Hi Paul,
first of all: thank you for this great information. Another valuable insight into SQL Server.
I’m seeing 60% of SERVICE_BROKER_TRANSMISSION_WORKTABLE and 39% ACCESS_METHODS_DATASET_PARENT latch waits.
I don’t know if this high value of SERVICE_BROKER_TRANSMISSION_WORKTABLE is (un)common when Service Broker is in place and I have found no description of the latch class either in BOL (see http://msdn.microsoft.com/en-us/library/ms175066%28v=sql.105%29.aspx)
Do you have any hint for me if I can ignore this latch class since it may is for internal use only or should I dig a bit deeper into the service broker usage implemented by the devs?
Regards
Dirk
Hmm – that’s one I don’t know. Can you capture some call stacks for it using the technique I describe in the spinlocks and SOS_SCHEDULER_YIELD post from last year?
I ran the query on our prod server and we get a 60% wait on ACCESS_METHODS_ACCESSOR_CACHE, I can’t find any documentation on this, any help would be greatly appreciated.
This latch controls access to a cache of mechanisms for pulling columns out of rows. I haven’t seen this be a problem. What percentage of the overall waits (from dm_os_wait_stats) are LATCH_SH/UP/EX?
We recently see server hanging several times under the ACCESS_METHODS_ACCESSOR_CACHE latch. Being the compatibility level of the db @2016 we have been able to reduce some occurrence by ebabling the async feature of the statistics updates, but sometimes server hangs the same way
Here is a hot minute snapshot
StartDate EndDate LatchType Wait_S WaitCount Percentage AvgWait_Sec
2018-08-24 10:40:00 2018-08-24 10:41:00 ACCESS_METHODS_ACCESSOR_CACHE 20964.65 36261 99.69 0.5782
What do you mean by ‘hang’? Performance goes down or the server stops responding?
Performance goes down because almost all SPIDs wait on the ACCESS_METHODS_ACCESSOR_CACHE (same address), also for several seconds.
In these day we removed the GROUP_MAX_REQUESTS limit settings from all the workload groups and the problem disappeared.
With 2016 SP1 and the db in the 2010 Compatibility level 2010 this was never happening
I experience a similar issue on my system. We currently see 1-7s spikes where a lot of LATCH_SH/LATCH_EX waits occur around 5 times a day, always for the same specific query. Using your scripts it seems like a spike in the ACCESS_METHODS_ACCESSOR_CACHE latch class observed by an extended event session. I was able to get a memory address of the latch that all sessions are waiting for (from the latch_suspend_begin event) but I do not know where to go from here. I cannot seem to find much information on this latch class a part from your pages.
PAGELATCH SH/UP/EX make up ~1.7% of the total waits since over 100 days of DB up time (so is it even worth looking into?) but the spikes worry me. Can it simply just be that the specific query is called too much? (~900/s during spike)
All of that’s nothing to worry about.
Thanks for the reply!
The specific query that is experiencing the LATCH_SH spike is run for a lot of RPCs in our application and will stall a lot of requests during the spike (so it affects the client). Although it does not happen often it is the only problem we have right now and I would like to try and resolve it somehow… do you have any pointers on how I can address this further?
We’d need to look at the query/workload to diagnose further – let me know if you’re interested in some consulting help. Thanks
Paul’s course on http://www.pluralsight.com/ is required viewing of you really want to get a handle on latches. Joe Sack’s has a great overview of wait stats but Paul’s course if just awesome.
we got this error from sqlagent.out (SQL Server 2008 R2) and cos some of queries being slow with cpu high than normal.
SQLServer Error: 845, Time-out occurred while waiting for buffer latch type 4 for page (1:1679), database ID 4. [SQLSTATE 42000] (ConnExecuteCachableOp)
could be msdb corruption ? and how to fix this ?
thanks
Maybe. What does CHECKDB of msdb return? Could also be delays in the I/O subsystem or an I/O subsystem problem.
i checkdb of msdb return normal. we have to restart to make it normal.
Hi Paul,
Great for your wonderful and unique article
i am also getting DBCC_PFS_STATUS, DBCC_FILE_CHECK_OBJECT. is this problematic?
Regards,
Manish
Hi Paul,
Thanks for the wonderful article.
When I ran the code to find waittypes, the following waittypes were encountered:
‘DBCC_CHECK_TABLE_INIT’
‘DBCC_MULTIOBJECT_SCANNER’
‘CXPACKET’
and DBCCCheckd for db around 2 TB size was struggling. What are the best practices which must be followed in such cases?
MaxDOP is 0 and Cost of Parallelism is 5.
Thanks In Advance.
That looks just like a normal CHECKDB. Fast disks, lots of memory, no other workload, etc etc. See my post on consistency checking options for a VLDB – you may want to consider using another system or breaking up the checks.
Thanks Paul.
If the check db is run with Physical_Only option, then I think it would skip FileStream data checks. If the database is having filestream and CDC, is it advisable to run CheckTable, CheckAlloc against the database or is there any other option?
Yes, it skips FILESTREAM checks when you use PHYSICAL_ONLY. I’d recommend a non-PHYSICAL_ONLY CHECKDB or CHECKTABLE for those tables with FILESTREAM. CDC is irrelevant.
We were seeing DBs time out and processor time is usually high on production. Start working to find reason and came to this blog.
This is what I got
LatchClass Wait_S WaitCount Percentage AvgWait_S
ACCESS_METHODS_DATASET_PARENT 135,357 69488271 94.98 0.0019
We have MaxDOP = 8 and cost threshold for parallelism = 5 (default). Machine has two sockets each has 8 physical processor.
This is way beyond the scope of a blog comment I’m afraid. Check out the advice at http://www.sqlskills.com/sql-server-performance-tuning – lots of stuff to get you started there.
We don’t have a big problem just fine tunning the system.
Today some of the users complained about performance issues.
I opened the “Idera SQL check” free tool to find that “Non-page latch” has the main role. (above normal benchmark).
Normally I don’t see this wait group.
Digging further I narrowed it to LATCH_EX.
I took 2 samples (an hour appart) of dm_os_latch_stats, here is the delta between them:
latch_class waiting_requests_count wait_time_ms max_wait_time_ms
BUFFER 48507 963936 0
ACCESS_METHODS_DATASET_PARENT 916743 468162 0
ACCESS_METHODS_ACCESSOR_CACHE 3224 1569 0
Analyzing my benchmark, BUFFER was half in wait time and tenth in waiting_requests_count.
So I went back to analyze dm_os_wait_stats. Here I calculated the ratio between the sample and history.
The average percentage of the sample was 0.2% , but the following stood out:
wait_type waiting_tasks_count wait_time_ms max_wait_time_ms signal_wait_time_ms %
PAGEIOLATCH_SH 50854 1017903 0 2132 2.85%
PAGEIOLATCH_EX 2467 32306 0 21 1.60%
BROKER_TASK_STOP 245 1230115 0 4 1.53%
LATCH_EX 1938409 996801 0 142596 1.31%
PREEMPTIVE_OS_CRYPTOPS 51422 9594 0 0 1. 14%
PREEMPTIVE_OS_CRYPTACQUIRECONTEXT 51571 9513 0 0 1.13%
PREEMPTIVE_OS_CRYPTIMPORTKEY 51568 2696 0 0 1.09%
CXROWSET_SYNC 1606 403 0 118 0.92%
PREEMPTIVE_DTC_ABORTREQUESTDONE 165 120 0 0 0.92%
CMEMTHREAD 1993 460 0 188 0.87%
please help me with this:
LatchClass Wait_S WaitCount Percentage AvgWait_S
ACCESS_METHODS_DATASET_PARENT 22922.96 1653215 77.30 0.0139
NESTING_TRANSACTION_FULL 6433.59 383546 21.69 0.0168
NESTING_TRANSACTION_READONLY 274.45 29856 0.93 0.0092
FGCB_ADD_REMOVE 11.16 344 0.04 0.0324
BUFFER_POOL_GROW 4.87 431 0.02 0.0113
LOG_MANAGER 4.52 112 0.02 0.0403
ACCESS_METHODS_ACCESSOR_CACHE 2.05 2204 0.01 0.0009
ACCESS_METHODS_HOBT_VIRTUAL_ROOT 1.83 75 0.01 0.0244
ACCESS_METHODS_HOBT_COUNT 0.39 603 0.00 0.0006
What’s your question about these?
LatchClass Wait_S WaitCount Percentage AvgWait_S
ACCESS_METHODS_DATASET_PARENT 538505.72 264044033 97.69 0.0020
What is the ACCESS_METHODS_DATASET_PARENT?
What do you recommend to reduce the wait time?
The blog post explains what that latch class means. I don’t recommend anything unless LATCH_EX is suddenly the prevalent wait type, and it’s for this latch class. In that case, proceed as if you’re working on reducing parallel table scans that you’ve determined are unwanted. If they’re expected, then there’s no problem.
Hi Paul, I’m having some issues getting information about this latch ACCESS_METHODS_HOBT_COUNT. I don’t totally understand why this happens, if it is something to be worried about. what actions can we take to fix this…
could you please give me some guidance?
thanks in advance!
It’s to do with flushing row/page count changes to metadata on disk. Why do you think this is a bottleneck for your server?
Paul Sir,
I am a junior level dba and interested to learn and grow in my career.Please help me with the follwing questions:
What are the normal parallelism troubleshooting methods?
How to decide if parallelism is warranted?
What values should i set for ‘cost threshold for parallelism’ and MAXDOP
http://sqlperformance.com/2015/06/sql-performance/knee-jerk-wait-statistics-cxpacket
You are the great.
Sir pls Latch coupling comes under which latch
Page latches while navigating through an index.
Hi,
For two days, for an unknow reason, my server CPU is 100%, and when I ran your query, I have 79% that is ACCESS_MEHTODS_ACCESSOR_CACHE and 12% that is ACCESS_METHODS_DATASET_PARENT. Have you ever seen that??
ACCESS_METHODS_ACCESSOR_CACHE 256416.33 60799804 79.06 0.0042
ACCESS_METHODS_DATASET_PARENT 39082.56 568876548 12.05 0.0001
LOG_MANAGER 25188.57 2732 7.77 9.2198
Yes – but don’t start with latches, start with waits. Run my waits query and you’ll see a bunch of parallel queries running. That’s where you need to start tuning.
What is a difference between latch and lock ??
I’ll cover that in Monday’s newsletter, and then blog it in a few weeks.
Thanks!
How can I get your the newsletter?
https://www.sqlskills.com/newsletter
Thanks!