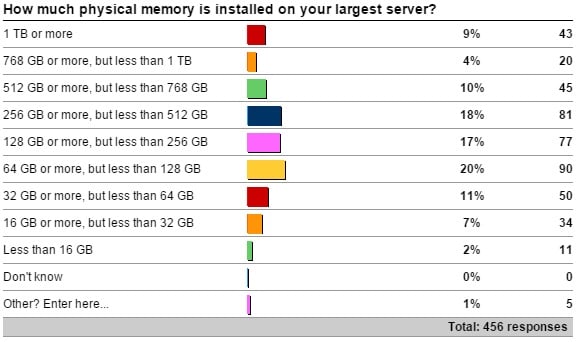
A month ago I kicked off a survey asking how much memory is installed on your largest server that’s running SQL Server. Thank you to everyone that responded.
Here are the results:
Check It Out!

The “other” values are:
- 3 more for the ‘128 GB or more, but less than 256 GB’ count
- 1 more for the ‘Less than 16 GB’ count
- One poor soul who only has 512 MB in their server!
This is very interesting:
- I expected the majority of servers to fall into the middle of the range (around 128GB), and it’s actually only 37% that fit into the 64 GB to 256 GB range.
- I’m surprised at the percentage of servers (41%) of servers with 256 GB or more.
- I didn’t know what percentage would have more than 1 TB, so almost 10% is really cool to see.
So what do these results mean? Well, the number of servers out there with lots (more than 128GB) of memory is more than half of all respondents. The more memory you have, the more important it is that you make sure that the memory is being used efficiently and that you’re not wasting space in the buffer pool (see here) and that you’re not churning the buffer pool with poor query plans causing lots of reads (see here).
What other things could be problems with large amounts of memory?
- Shutting down the instance. This will checkpoint all the databases, which could take quite a long time (minutes to hours) if suddenly all databases have lots of dirty pages that all need to be flushed out to disk. This can eat into your maintenance window, if you’re shutting down to install an SP or a CU.
- Starting up the instance. If the server’s POST checks memory, the more memory you have, the longer that will take. This can eat into your allowable downtime if a crash occurs.
- Allocating the buffer pool. We’ve worked with clients with terabyte+ buffer pools where they hit a bug on 2008 R2 (also in 2008 and 2012) around NUMA memory allocations that would cause SQL Server to take many minutes to start up. That bug has been fixed in all affected versions and you can read about in KB 2819662.
- Warming up the buffer pool. Assuming you don’t hit the memory allocation problem above, how do you warm up such a large buffer pool so that you’re not waiting a long time for your ‘working set’ of data file pages to be memory resident? One solution is to analyze your buffer pool when it’s warm, to figure out which tables and indexes are in memory, and then write some scripts that will read much of that data into memory quickly as part of starting up the instance. For one of the same customers that hit the allocation bug above, doing this produced a big boost in getting to the steady-state workload performance compared to waiting for the buffer pool to warm up naturally.
- Complacency. With a large amount of memory available, there might be a tendency to slacken off proactively looking for unused and missing index tuning opportunities or plan cache bloat or wasted buffer pool space (I mentioned above), thinking that having all that memory will be more forgiving. Don’t fall into this trap. If one of these things becomes such a problem that it’s noticeable on your server with lots of memory, it’s a *big* problem that may be harder to get under control quickly.
- Disaster recovery. If you’ve got lots of memory, it probably means your databases are getting larger. You need to start considering the need for multiple filegroups to allow small, targeted restores for fast disaster recovery. This may also mean you need to think about breaking up large tables, using partitioning for instance, or archiving old, unused data so that tables don’t become unwieldy.
Adding more memory is one of the easiest ways to alleviate some performance issues (as a band-aid, or seemingly risk-free temporary fix), but don’t think it’s a simple thing to just max out the server memory and then forget about it. As you can see, more memory leads to more potential problems, and these are just a few things that spring to mind as I’m sitting in the back of class here in Sydney.
Be careful out there!
12 thoughts on “Problems from having lots of server memory”
But the next question is how much of your disk is local and SSD rather than shared SAN filer disk. Our big system has “only” 128GB of RAM but also has 3TB of SSD. Ram is just your top tier for data, SSD can massively change the overall performance with reduced latency and high bandwidth.
To a point – but this can also be a crutch that allows you to not solve performance issues that are causing high read volumes when they shouldn’t. The highest performance I/O is one that stays logical and doesn’t become physical. One could argue that a server with 3TB of data that absolutely has to do a lot of reads should have more memory than 128GB, as SSD is still 100-1000 times slower than memory access.
Note, that shutting down an instance using the Service Control Manager (net stop sqlserver) does not checkpoint, but simply kills everything: https://connect.microsoft.com/SQLServer/feedback/details/776427/sql-server-service-control-manager-shutdown-does-not-checkpoint
This implies that crash recovery needs to run on instance startup.
The issue is not being fixed as it seems.
Paul,
There are 126GB or 256GB memory on our server, installed windows Server 2012 Datacenter and SQL Server 2012 SP1, and we meet a non-yield problem on many servers, the “TokenAndPermUserStore” use more than 13GB memory, MS told us that we need use sp_configure to change ‘access check cache bucket count’ and’access check cache quota’, we set ‘access check cache bucket count’ to 256 and set ‘access check cache quota’ to 1024, it does not work, could you please give us some advice for these option?
You need to go back to MS and tell them it didn’t work and ask them to give you more help.
MS suggert that we need test and give us a post http://blogs.msdn.com/b/psssql/archive/2008/06/16/query-performance-issues-associated-with-a-large-sized-security-cache.aspx, but it’s hard to test before we apply the new value on product server.
Thanks Paul!
Nothing else I can tell you – they gave you the correct advice.
More memory can lead SQL server to generate poor execution plans affecting performance. Recently, I ran into this issue and TF 2335 helped me. See http://dba.stackexchange.com/questions/53726/difference-in-execution-plans-on-uat-and-prod-server. Paul White was kind enough to clearly explain the cause.
This issue is also documented in KB2413549 – Using large amounts of memory can result in an inefficient plan in SQL Server (http://support.microsoft.com/kb/2413549).
Thanks for all knowledge sharing.
Kin
Hi Paul,
I am facing the issue with the sql server memory utilization. We are using 15 GB ram. Every 15 days sql server memory utilization is crossed 95%. So I dont have a choice to restart it whenever its crossed 95%. I do know that Cleaning bufferpool is not good option in production. We are using sql server 2012 Standard edition. our DB size is around 30GB. Please give me better solution for this.
Thank you.
This is how SQL Server works – it will take all the memory you give it. You need to set max server memory correctly to limit how much SQL Server can use.
Buffer cache an Plan cache: they are two much relevant memory areas inside SQL Server.
1. I understand that Plan cache is a distinct area, and it is NOT included in Buffer cache. Right?
2. We know that max server memory limits the Buffer pool only. There are many other memory areas outside of it (including plan cache?). So the sad truth is that we cannot control or limit the overall SQL Server memory consumption. Right?
3. The memory reserved (committed) by SQL Server is shown by the “Total Server Memory” object perf counter, right?
1) Plan cache memory is taken from the buffer pool.
2) See the latest Insider article for details
3) Correct