Well it's been almost 6 weeks since my last benchmarking blog post as I got side-tracked with the Myth-a-Day series and doing real work for clients :-)
In the benchmarking series I've been doing, I've been tuning the hardware we have here at home so I can start running some backup and other tests. In the last post I'd finally figured out how to tune my networking gear so the performance to my iSCSI arrays didn't suck – see Benchmarking: 1-TB table population (part 5: network optimization again).
Now I've decided that instead of using a 1-TB data set, I'm going to use a 100-GB data set so I don't have to wait 6 hours for each test to finish, it also means that I can start to make use of the SSDs that the nice folks at Fusion-io sent me to test out (sorry guys – I did say it would be a while until I got around to it!). See New hardware to play with: Fusion-io SSDs. I've got two 640-GB cards but I can only install one right now as I need the other PCI-E slot for the NIC card so I can continue to make comparisons with the iSCSI gear without compromising network performance. Then I'll move on to some pure iSCSI vs pure SSD tests.
I've been starting to discuss SSDs a lot more in the classes that I teach and there's some debate over where to put an SSD if you can afford one. I've heard many people say that using them for transaction logs and/or tempdb is the best use of them. We all know what the real answer is though, don't we – that's right – IT DEPENDS!
When to consider SSDs?
An SSD effectively removes the variability in latency/seek-time that you experience with traditional disks, and does best for random read/write workloads compared to sequential ones (I'm not going to regurgitate all the specs on the various drives – Google is your friend). Now, for *any* overwhelmed I/O subsystem, putting an SSD in there that removes some of the wait time for each IO is probably going to speed things up and lead to a workload performance boost – but is that the *best* use of an SSD? Or, in fact, is that an appropriate use of hardware budget?
If you have an overwhelmed I/O subsystem, I'd say there are two cases you fall into:
-
SQL Server is doing more I/Os than it has to because the query workload has not been tuned
-
You can tune the queries
-
You can't do anything about the queries but you can add more memory
-
You can't to anything about the queries and you can't add more memory
-
-
The query workload has been tuned, and the I/O subsystem is still overwhelmed.
I'd say that case #2 is when you want to start looking at upgrading the I/O subsystem, whether with SSDs or not.
If you're in case #1, there are three sub-cases:
-
You can tune the queries
-
You can't do anything about the queries but you can add more memory
-
You can't to anything about the queries and you can't add more memory
If you're in #1.1, go tune the queries first before dropping a bunch of money on hardware. Hardware will only get you so far – sooner or later your workload will scale past the capabilities of the hardware and you'll be in the same situation.
If you're in #1.2, consider giving SQL Server more memory to use for its buffer pool so it can hold more of your workload in memory and cut down on I/Os that way. This is going to be cheaper than buying SSDs.
If you're in case #1.3, you're in the same boat as for case #2.
Now you might want to start considering SSDs, as well as more traditional I/O subsystems. But what to put on it? Again, any overwhelmed I/O subsystem will benefit from an SSD, but only if you put it in the right place.
I have some clients who are using SSDs because they can't connect any more storage to their systems and this gives them a lot of flexibility without the complexity of higher-end storage systems. Others are thinking of SSDs as a greener alternative to traditional spinning disks.
The other thing to consider is redundancy. A 640-GB SSD card presents itself as 2 x 320-GB drives when installed in the OS. As you know, I'm big into availability so to start with I'm going to use these as a 320-GB RAID-1 array (not truly redundant as they're both in the same PCI-E slot – but I can't use both PCI-E slots for SSDs yet). I need to make sure that if a drive fails, I don't lose the ability to keep my workload going. This is what many people forget – just because you have an SSD, doesn't mean you should compromise redundancy. Now don't get me wrong, I'm not saying anything here that implies SSDs are any more likely to fail than any other technology – but it's a drive, and prudence dictates that I get some redundancy in there.
The first test: not overwhelmed transaction log
But which of your data and log files to put onto an SSD? It depends on your workload and which portion of your I/O subsystem is overloaded. This is what I'm going to investigate in the next few posts.
For my first set of tests I wanted to see what effect and SSD would have on my workload if the transaction log isn't the bottleneck but I put in on an SSD, as much advice seems to suggest. In other words, is the log *always* the best thing to put on an SSD? I'll do data files in the next test.
This is a narrow test scenario – inserting 100-GB of server-generated data into a single clustered index. The post Benchmarking: 1-TB table population (part 1: the baseline) explains the scripts I'm using. The hardware setup I'm using is explained in Benchmarking hardware setup, with the addition of the PCI-E mounted 640-GB ioDrive Duo.
For the data file, I had it pre-grown to 100GB, on a RAID-10 array with 8 x 15k 300-GB SCSI drives.
For the log file, I had a variety of sizes and auto-growths, both on a RAID-10 array with 8 x 7.2k 1-TB SCSI drives, and on the 320-GB RAID-1 SSD. The log configurations I tested are:
-
Starting size 256MB with 50MB, 256MB, 512MB auto-growth
-
Fixed auto-growth of 256MB, but starting size of 256MB, 512MB , 1GB, 2GB, 4GB, 8GB
In each case I ran five tests and then took the average to use as the result.
Fixed initial size and varying auto-growth
This test case simulates a system where the log starts small and grows to around 6GB, then remains in steady state. Transaction size is optimized for the maximum 60-KB log block size, when the log *must* be flushed to disk, no matter whether a transaction just committed or not.
The results from the first test are below:
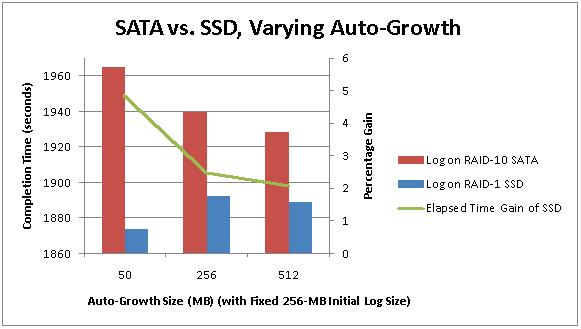
At the 50MB growth rate, the SSDs gave me a 5% gain in overall run time (the green line), but this decreased to around 2% when I started to increase the auto-growth size. Remember each data point represents the average of 5 tests.
Varying initialize size with fixed auto-growth
This test is the same as the previous one, but tries to remove the overhead of transaction log growth by increasing the initial size of the log so it reaches steady-state faster.
The result from the second test are below:
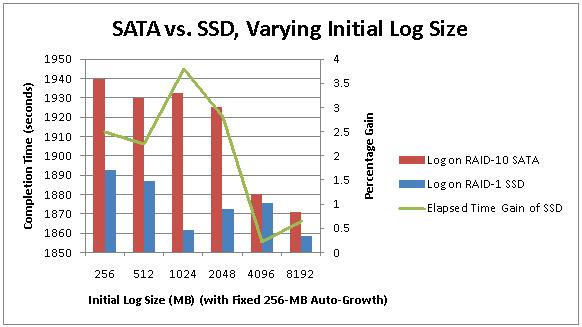
For initial log sizes up to and including 2-GB, the SSD gives me a 2.5-3.5% gain over the SATA array. This makes sense as the zero initialization that is required by the log whenever it grows will be a little faster on the SSD. Once I hit 4-GB for the initial size they performed almost the same, and at 8-GB, when no autogrowth occured, the SSD was only 0.8% faster than the RAID-10 array.
Summary
What am I trying to show with these tests? For this post I'm not trying to show you wonderful numbers that'll make you want to go out and buy an SSD right away. I wanted to show you first of all that just because I have an SSD in my system, if I put it in the wrong place, I don't get any appreciable performance gain. Clearly the RAID-10 array where my log is was doing just fine when I set the correct log size and growth. You have to think about your I/O workload before making knee-jerk changes to your I/O subsystem.
But one thing I haven't made clear – a single SSD configured in RAID-1 outperformed a RAID-10 array of 8 7.2k SATA drives in every test I did!
For this test, my bottleneck is the RAID-10 array where the data file is. Before I try various configurations of that, I want to try the SSD in a RAID-0 configuration, which most people use, and also see if I can get the RAID-10 array to go any faster by formatting it with a 64K stripe size.
17 thoughts on “Benchmarking: Introducing SSDs (Part 1: not overloaded log file array)”
That’s interesting Paul. I would think that the difference between HDD array and SSD would be bigger than 2-4%. I also would imagine log files would be first candidates to move to SSD. I am curious what will turn up with the data files.
Thanks! :)
I’m not familiar with the architecture of the SSDs you’re using, but is creating a raid 1 array using a single SSD drive really giving you much in the way of redundancy? Are the two "drives" isolated enough that one can fail without compromising the other?
That’s the whole point – in this case, my log file was fine, so putting it on an SSD didn’t help. It’s a real misconception.
Not so much – they’re both in the same PCI-E slot – to get true redundancy I’d need two cards – but I can’t configure my server that way yet.
I know from my own testing that some standalone SSDs have relatively poor sequential write performance (so they would not be good candidates from a transaction log). The small variability in your results as you tried lots of different configuration changes to the log drive shows that the bottleneck is somewhere else.
It would be interesting to see what was going on with your top wait stats, and with Perfmon Avg Disk Sec/read and Avg Disk Sec/write for the data and log file arrays during these tests. I am very jealous that you have those Fusion-IOs to play with…
Keep up the good work!
But what you don’t really highlight is that the single SSD drive was able to beat an 8) 7.2k drive RAID-10 array, even if only by a little bit. Cost wise I’m not sure what the comparison would be though.
I never have understood why people want to put logs, which have a significant amount of sequential I/O, on SSD’s where the greatest performance advantage is in random IO.
I can also confirm that sqlio benchmarks show a RAID-1 pair of enterprise SSD’s on a SAS interface beat a RAID-1 pair of very modern 600GB, 15k SAS drives soundly on random access, and both pairs appeared to be controller limited on large block size sequential transactions. The SSD pair also showed the presumptive capability to meet or beat the performance of a 15-disk (older 146GB 15k FC drives, so much lower individual performance than the 600GB drives above) SAN LAN in very cursory, very unreliable "indication of concept" testing.
Tempdb I can see as a good thing to put on the SSD’s, but other than that, I’d suggest trying to monitor which tables and indexes are getting a lot of random I/O (or at least I/O) of whatever type, and move those over to the SSD’s (have SSD-only filegroups). Especially if you’re hitting any kind of limit on the SAN side, whether it be bandwidth or IOPS or cache turnover or even raw latency, you’ll be able to pull some data off the SSD’s at quite a good speed (benchmark it against your own particular SAN config, if you can) while pulling even more data from the SAN, and thus your aggregate performance should improve (unless your SSD’s aren’t even in the same ballpark as your SAN).
I wouldn’t use RAID-0 on a production database; failures can happen to anything (ever have a bad stick of RAM? Or a fan failure that allowed the heat to climb which in turn caused other failures?), so I would contend that some redundancy is better than none. I might, however, set up multiple different SSD RAID-1 pairs.
How many client connections did you use in the test? When you added a Fusion-IO to the mix, it probably increased an overall I/O cpacity of the system, i.e. you may get a much better overall perf. by increasing workload.
For this test I kept everything the same. I’m running some tests now that use RAID-0 and varying other parameters too.
So you run 16 concurent connections? My point is that for HDDs, 16 connections may be the top it can support. Fusion-IO has better IO capacity so it can scale highter than 16. Better hardware has 2 advantages: it can remove current bottleneck if you have one, and it increases capacity of the system, so you can sustain a highter workloads. For your current test we may have the second case.
@Konstantin Yes, as usual you’re jumping ahead :-) I’m changing things slowly so I can show the effect rather than immediately jumping to the best-case scenario. I know everything you’re saying, but I’m taking my readers there slowly.
@Deepside Indeed – hence the point of my post that sticking it in place of the log array isn’t the best use of it. I would never use RAID-0 for a prod database, whether on SSD or not, but that’s apparently what many people do so I want to give it a try.
Thanks for the comments!
Hi Paul, great article, but I know it’s over 4 years old. Anything changed materially and recommendations on articles (either by you or others) that have updated info on SSD’s as the technology has changed in the intervening time.
Thanks!
Thanks. Nothing’s changed that I know of.
Is there a recent benchmark article on SSD for local tempdb related to SQL server 2012?
Thanks,
Pingala
Unknown – I’d have to search on Google to find one.
Wanted to explore whether\or not either using an SSD flash drives or Ram Disks for
SQL Server 2012 Enterprise for 8 TEMPDB to take some IO/network load off of the Netapp storage.
Will this help performance?
Product: SQL Server 2012 Enterprise Core EN
Operating System: Windows Server 2008 Ent R2 SP1 x64 bit
Two Physical: Two node Cluster
Two Physical: Memory: RAM 512 GBs
Two Physical CPU: 64 logical Cores
Virtualization: No VMs
Description: Do SSD flash drives or RamDisks good idea for supporting for
eight tempdbs on a two-node cluster
AlwaysOn: No
Using the same LAN\SAN
Backups using the Snapshot Database mirroring
Impossible to say without knowing about your workload and performance characteristics. If tempdb I/O is a bottleneck for you, and you can’t reduce tempdb usage in SQL Server, then yes, SSDs will likely help you. I recommend you discuss this with your infrastructure team inside Microsoft.