It’s well known that one of the common performance issues that can affect tempdb is allocation bitmap contention. I discuss this, and ways to alleviate it, in these posts:
- The Accidental DBA (Day 27 of 30): Troubleshooting: Tempdb Contention
- Misconceptions around TF 1118
- Tempdb configuration survey results and advice
The current best advice around adding tempdb data files is enshrined in KB article 2154845. If you’re seeing tempdb allocation contention (see top blog post link above), then:
- If your server has less than 8 logical cores (e.g. a one CPU server with 4 physical cores and hyperthreading enabled has 8 logical cores), use # tempdb data files = # logical cores, equally sized
- If your server has more than 8 logical cores, start with 8 tempdb data files, and add sets of four at a time, equally sized, until the contention is alleviated
There are three problems that people often face when adding tempdb data files: matching the size of the existing files that are growing, adding a file doesn’t help with contention, and adding too many files.
Check It Out!

Matching Existing File Sizes
This problem occurs when the existing tempdb data files are growing, and people find it hard to create additional files that match the size of the existing files.
There’s an easy method for doing this: don’t!
Don’t try to match the size of existing, growing files. Create the new files to be a bit larger than the existing files, then go back and increase the size of the existing files to match the size of the new files.
For example, if I have 4 tempdb data files sized at 6GB each, and they’re growing by 512MB every few minutes because of an ad hoc workload. If I decide to add 4 more files, I might decide to add the four new files at 10GB each, and then go back and do ALTER DATABASE [mydb] MODIFY FILE [DataFileX] (SIZE = 10GB) for each of the 4 existing files. Problem solved.
But also see the bottom section, where you may want to limit the total amount of space taken up by all your tempdb files if the only reason for extra files is to alleviate tempdb allocation contention.
Additionally, if you have one full data file, you may find that…
Adding a File Doesn’t Help
This is very frustrating when it happens to people because it gives the impression that adding tempdb data files does not help with allocation contention. However, there is a simple explanation for this phenomenon.
Consider the case where there is one tempdb data file. Obviously all the allocations have to come from that data file and with the right workload, allocation bitmap contention will result. After the server has been up for a while, and the workload has been running and using tempdb for a while, the single tempdb data file may become quite full.
Now let’s say that you decide to add one more tempdb data file. What happens to the allocations?
Allocation uses two algorithms: round-robin and proportional fill. It will try to allocate from each file in the filegroup in turn, but will allocate proportionally more frequently from files that have proportionally more free space than others in the filegroup.
In the case where one file is very full and the other file is very empty, the vast majority of the allocations will be from the new, empty file. This means that almost all the contention moves from the initially existing tempdb data file to the new one, without much alleviation of the overall contention.
If this happens to you, try adding some more data files so that the allocation system has multiple files that it will allocate from, spreading the contention over those files and leading to an overall drop in contention and increase in transaction throughput.
But beware of immediately…
Adding Too Many Data Files
This is the case where tempdb allocation contention is a problem and people immediately add a large number of additional files where fewer files would work just as well. The problem here is that additional disk space is used up for no real gain, which may or may not be significant in your environment, depending on the size of the files added.
Let’s do an experiment. Below is a screen shot of PerfMon measuring transactions per second in tempdb for a contrived workload that has 100 connections all repeatedly creating and truncating temp tables. It’s running on my laptop (8 logical cores) using SQL Server 2014 RTM CU3.
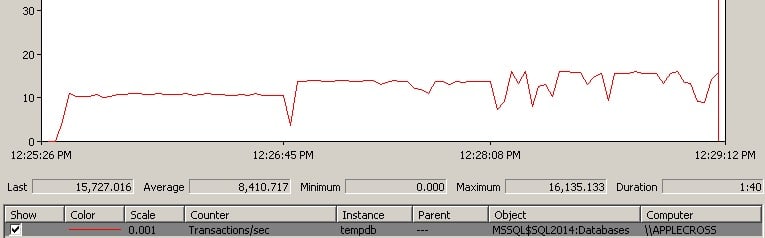
For the first third of the trace, there’s a single data file. For the middle third of the trace, there are two equally-sized files. For the final third of the trace, there are 8 equally-sized files.
Clearly there isn’t a big performance boost from having the additional 6 data files in the final third, but what’s the sweet spot?
Ideally you’d experiment with varying numbers of tempdb data files to find the sweet spot for your workload. However, that’s easier said than done, especially when you’re trying to standardize a tempdb configuration across multiple servers.
Here’s an example of a slightly different workload running under the same conditions on my laptop.
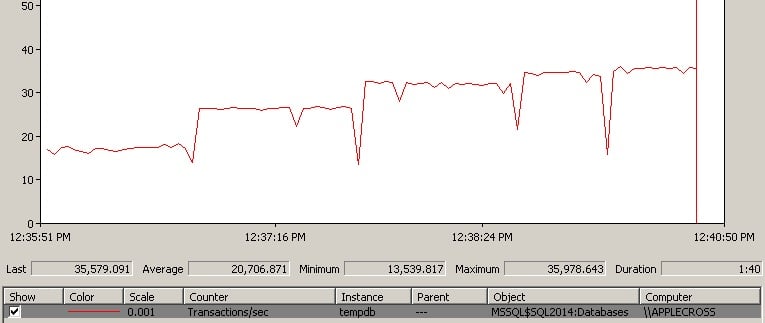
It starts with a single data file, then 2, 4, 6, and 8 (pausing perfmon between each file addition). In this case, it’s clearly worth it going to 8 data files. But would I make them all the same size as the initial data file?
No, not if the only reason I need the extra files is to alleviate the allocation bitmap contention. I’d lower the size of all the tempdb files, including the initial one, so I’m not taking up a huge amount of extra disk space for these files.
Just be aware that sometimes you don’t need to go all out and add a whole bunch of extra tempdb data files to get a performance boost.
Summary
The easiest way to alleviate tempdb allocation contention is to enable trace flag 1118 and to add more tempdb data files. Just be careful that you add the right number to help with the contention, you make all the files the same size, and that you take into account the total size of all the data files you’ve created, and possibly dial them all down a bit.
Enjoy!
35 thoughts on “Correctly adding data files to tempdb”
Nice clear and concise post Paul.
Thanks!
If you are putting tempdb on a dedicated drive, which is a best practice, is there any reason to be concerned with how much disk space the data files are taking up, assuming that there is still enough disk space for the tempdb lo file for the workload?
Hey Robert – nope – in that case it’s safe to use as much space as you think you need. There’s no performance penalty from having the data files being large (that I can think of), and of course there’s no disaster recovery penalty either as tempdb doesn’t get restored ever.
Thanks! As always, I appreciate you sharing your knowledge!
Hi Paul,
Great Always.
Please & Please let us know why always evenly add files(4 files or multiple of 4) why not oddly(3 or mulitple) for e.g. if i have 18 cores.
Regards
Bob didn’t explain why in his testing results, but I’m guessing it’s so that it’s a power of two so the round-robin and proportional fill algorithms aren’t unbalanced compared to the number of processors. Most systems have a multiple of 4 processor cores.
I feel like I should know/remember the answer to this given last weeks IE class, but when runaway or massive queries utilize tempdb, can it spread a temp table across files, or does the table just reside in 1 file? I’m trying to think of an instance where having too many divisions of tempdb could be detrimental, say you have a 50GB drive devoted to tempdb, and you divide the files up either with two files of 20GB apiece, or 8 files of 5GB apiece, with 10GB freespace left in each scenario. And then one massive query goes haywire and starts stuffing vast amounts of data into a temp object in tempdb.
In the first scenario (*IF* the tables/objects don’t get spread across the files), you would hit the 20GB cap in one file, and then that file could grow another 10GB and then the query would fail.
In the second scenario (again, with the in-question assumption that single objects do not get evenly distributed across files), you hit the 5GB cap of one file, and that file can grow another 10GB, so the query fails at 15GB of tempdb usage instead of the 30GB of the previous example.
Our developers are much addicted to superfluous SELECT DISTINCT and temp tables and can often find unique ways of testing the size limits of tempdb, so this isn’t an unrealistic scenario for us, at least in non-production. But if a tempdb object can be split across multiple files, it’s a non-issue, it would just fill up all 40GB of tempdb files in either scenario.
Thanks!
Hey Nic – all allocation uses round-robin as usual.
Thanks sir! I was labouring under a misapprehension of round robin allocation happening at an object level (ie., this object to this file, this object to the other), not a page/extent level, the latter being of course how it works (had to test it to prove it to myself). All cleared up now!
I wrote a PowerShell script to check both the TempDb files and the startup parameters.
Please have a look at:
http://finn.rivendel.be/?e=34
Your remarks and suggestions are welcome.
Paul,
I have question regarding sorting. I SET STATISTICS IO ON before running my query which involve some order by and group by. I see all logical read no physical read. However, when I run the following, I see the num_of_writes keep going up and I am using my local sql and no one is using it. Can you explain why tempdb activities don’t show up under STATISTICS IO?
SELECT num_of_writes, num_of_bytes_written FROM
sys.dm_io_virtual_file_stats(DB_ID(‘tempdb’), 1)
GO
Thanks,
Chung.
I don’t know – I’m not an expert on what that does/doesn’t show. Try asking on #sqlhelp on twitter or on one of the forums.
Hi Paul,
The new tempdb files which we add, should ideally be on different drive to gain performance . Because different drive means different thread.
Correct me if i am wrong ?
That’s not right. The one-thread-per-file/drive is a persistent myth. If you’re dealing with tempdb allocation bitmap contention, it doesn’t matter where the files are – all on the same drive is fine.
We’ll, we have a pretty busy web site and 24 core server with 22 TempDB data files and T1118 enabled, BUT still getting the issue :-(
You might need more files – or reduce your usage on small temp tables.
few days back we have moved to 2014 from 2012 server and we kept the same settings as earlier like we are using 8 datafiles in Tempdb for better performance and all placed in single drive.As this is datawarehouse environment batch loads are running continuously and tempdb drive is getting full.Even though 98% free space in Database it could not able reuse the space and throwing disk is full.
Insufficient space in tempdb to hold row versions. Need to shrink the version store to free up some space in tempdb. Transaction (id=239368387 xsn=1273322 spid=126 elapsed_time=1590) has been marked as victim and it will be rolled back if it accesses the version store. If the problem persists, the likely cause is improperly sized tempdb or long running transactions. Please refer to BOL on how to configure tempdb for versioning.
Any recommendation for tempdb performance improvement like enabling trace flag -T1118 ??
Our server specifications are below.
SQL Server detected 4 sockets with 15 cores per socket and 30 logical processors per socket, 120 total logical processors; using 120 logical processors based on SQL Server licensing.512 GB RAM.
You need more tempdb space – you’re obviously able to do more transactions on 2014, so more versions, so bigger version store. What happened to the version store when you tested your workload on 2014 before moving to production on it (or didn’t you do any testing)?
ok.We did testing in Test environment but configuration and data which we processed is completely different. We just tested that code is working fine or not.In 2012 it was just taking 64 GB for tempdb data files and now its taking around 400 GB+ still its throwing disk is full.Will it be that much difference between 12 and 14?
and we are planning below changes
1)adding startup parameter -T1118
2)we are using Netapp(NTFS) storage where allocation unit size currently 4 MB to 64 MB.
Please suggest we can go ahead with above changes ? Or any other changes to improve the tempdb performance.
None of those things are going to reduce the size requirements for tempdb. T1118 is to help prevent allocation bitmap contention. You’re not having a performance problem – you’re having a size problem.
Yes.After implementing -T1118 issue has been resolved.Thanks for your suggestions.
Another great post from Mr. SQL Server! Thanks Paul!
I have a question related to the sizes on the tempdb files. I have a tempdb currently with 32 files and we have tested that we don’t need so many files and we want to reduced them to 16 files of equal size. We try doing this online, but it doesn’t shrink to zero to allow removing the files online. We can’t have a downtime right now and we are not using alwayson at this site. The strategy proposed was to reduce 16 of the files to its minimum without growth capacity, with the theory that they would not be used as they are full and they can’t grow any more. This is a temporary work around (for couple of months) till our next downtime. Do you see any issues with this approach?
Sounds good.
Hi Paul,
In our enviroment (SQL Server 2012 SP2 Enterprise) maxdop setting has been made 1 per SAP recommendation. Can temp db still be able to use parallelism on multi file temp DB configuration. Kindly suggest
Tempdb doesn’t use parallelism – multiple concurrent connections are running at the same time and using tempdb. So yes, MAXDOP is orthogonal to tempdb allocation contention.
With 8 logical cores, is 8 data files just the recommended starting point? I’m assuming that it’s ok to add more data files to an 8-core system if tempdb contention is happening (as evidenced by PAGELATCH_xx waits).
Yes, just a guideline. But if you’re having to add more files than cores, I’d usually prefer to address the root cause of the PAGELATCH contention, rather than trying to smother it with more data files.
We have large SQL server running an AX workload. We have tempdb configured with 8 files though we have 64 cores. I can’t see any contention but we see lots of read and (mostly) write IO constantly in TempDB. AX does use a lot of Tempdb but we have plenty of memory – 256GB. Should we see that much IO on TempDB. Could increasing files improve performance. With plenty of memory should most of the Tempdb work not stay in memory or is it constantly being wrote to disk. I.e. create a temp table, then the whole temp table is written to disk. The AX db is big and obviously more memory would improve performance but I don’t think its overloading memory. PLE is high, cache hit ratio is good… Or is that IO in tempdb just normal writing of tempdb structures to disk and not necessarily data?
I don’t think adding files will help you here. I don’t know anything about the AX workload characteristics I’m afraid. Do you have snapshot isolation or RCSI enabled for any databases? Or using table variables, or code that’s doing spills to tempdb? Any of those could account for what you’re seeing.
I am trying to figure out why our servers in azure are showing tempdb files in the c drive.
I have been told there is nothing in our scripts that should cause this, but I don’t believe in magic anymore. We use ARM templates for deployment. For exmample on one of out systems that has two cores, I see the file paths as below.W e keep the tempdb files on F drive so the mdf is correct. Would it have to be in the ARM template we are using or is there something else that could cause this?
tempdb 1 tempdev F:\Data\tempdb.mdf
tempdb 2 templog F:\Log\tempdb.ldf
tempdb 3 temp2 C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\tempdb_mssql_2.ndf
No idea – I don’t do anything with Azure. You’ll need to post in an Azure forum. Thanks
Hi Paul
I read many of your blogs and benefited tremendously. Thanks for all of you do for the SQL community.
My tempdb drive size is about 3 TB and it has a lot of free space. But Log file growth stops once the file size reaches 1 TB. I can’t find the reason why it will stop growing at 1 TB since the max file size setting is unlimited.
I will truly appreciate your help to understand this issue.
Regards
Mohammad Hoque
Does it stop at exactly 1TB? Do you get an error message? Which version? What’s the autogrowth setting?