(New for 2020: we’ve published a range of SQL Server interview candidate screening assessments with our partner Kandio, so you can avoid hiring an ‘expert’ who ends up causing problems. Check them out here.)
This month the SQLskills team is presenting a series of blog posts aimed at helping Accidental/Junior DBAs ‘keep the SQL Server lights on’. It’s a little taster to let you know what we cover in our Immersion Event for The Accidental/Junior DBA, which we present several times each year. You can find all the other posts in this series at http://www.SQLskills.com/help/AccidentalDBA. Enjoy!
One of the most common performance problems that exists in SQL Server instances across the world is known as tempdb contention. What does that mean?
Tempdb contention refers to a bottleneck for threads trying to access allocation pages that are in-memory; it has nothing to do with I/O.
Consider the scenario of hundreds of concurrent queries that all create, use, and then drop small temporary tables (that by their very nature are always stored in tempdb). Each time a temp table is created, a data page must be allocated, plus an allocation metadata page to keep track of the data pages allocated to the table. This requires making a note in an allocation page (called a PFS page – see here for in-depth info) that those two pages have been allocated in the database. When the temp table is dropped, those pages are deallocated, and they must be marked as such in that PFS page again. Only one thread at a time can be changing the allocation page, making it a hotspot and slowing down the overall workload.
Back in SQL Server 2005, my dev team at Microsoft implemented a small cache of temp tables, to try to reduce this contention point, but it’s only a small cache, so it’s very common for this contention to be an issue, even today.
What’s really interesting though, is that many people don’t realize they have this problem – even seasoned DBAs. It’s really easy to figure out whether you have this kind of problem using the sys.dm_os_waiting_tasks DMV. If you run the query I have below, you’ll get an idea of where the various threads on your server are waiting, as Erin discussed earlier this month.
SELECT
[owt].[session_id],
[owt].[exec_context_id],
[owt].[wait_duration_ms],
[owt].[wait_type],
[owt].[blocking_session_id],
[owt].[resource_description],
CASE [owt].[wait_type]
WHEN N'CXPACKET' THEN
RIGHT ([owt].[resource_description],
CHARINDEX (N'=', REVERSE ([owt].[resource_description])) - 1)
ELSE NULL
END AS [Node ID],
[es].[program_name],
[est].text,
[er].[database_id],
[eqp].[query_plan],
[er].[cpu_time]
FROM sys.dm_os_waiting_tasks [owt]
INNER JOIN sys.dm_exec_sessions [es] ON
[owt].[session_id] = [es].[session_id]
INNER JOIN sys.dm_exec_requests [er] ON
[es].[session_id] = [er].[session_id]
OUTER APPLY sys.dm_exec_sql_text ([er].[sql_handle]) [est]
OUTER APPLY sys.dm_exec_query_plan ([er].[plan_handle]) [eqp]
WHERE
[es].[is_user_process] = 1
ORDER BY
[owt].[session_id],
[owt].[exec_context_id];
GO
Note that the [est].text line does not have text delimited – it throws off the plugin.
If you see a lot of lines of output where the wait_type is PAGELATCH_UP or PAGELATCH_EX, and the resource_description is 2:1:1 then that’s the PFS page (database ID 2 – tempdb, file ID 1, page ID 1), and if you see 2:1:3 then that’s another allocation page called an SGAM (more info here).
There are three things you can do to alleviate this kind of contention and increase the throughput of the overall workload:
- Stop using temp tables
- Enable trace flag 1118 as a start-up trace flag
- Create multiple tempdb data files
Ok – so #1 is much easier said than done, but it does solve that problem :-) Seriously though, you might find that temp tables are a design pattern in your environment because they made a query go faster once and then everyone started using them, whether they’re *really* needed or not for enhancing performance and throughput. That’s a whole other topic though and outside the scope of this post.
#2 prevents contention on the SGAM pages by slightly changing the allocation algorithm used. There is no downside from having this enabled, and I even say that all SQL Server instances across the world should have this trace flag enabled by default (and I said the same thing when I ran the dev team that owned the allocation code in the SQL Server Storage Engine).
#3 will help to remove the PFS page contention, by spreading the allocation workload over multiple files, thus reducing contention on the individual, per-file PFS pages. But how many data files should you create?
The best guidance I’ve seen is from a great friend of mine, Bob Ward, who’s the top Escalation Engineer in Microsoft SQL Product Support. Figure out the number of logical processor cores you have (e.g. two CPUS, with 4 physical cores each, plus hyperthreading enabled = 2 (cpus) x 4 (cores) x 2 (hyperthreading) = 16 logical cores. Then if you have less than 8 logical cores, create the same number of data files as logical cores. If you have more than 8 logical cores, create 8 data files and then add more in chunks of 4 if you still see PFS contention. Make sure all the tempdb data files are the same size too. (This advice is now official Microsoft guidance in KB article 2154845.)
Here’s an example screenshot of a 100-connection workload on tempdb.
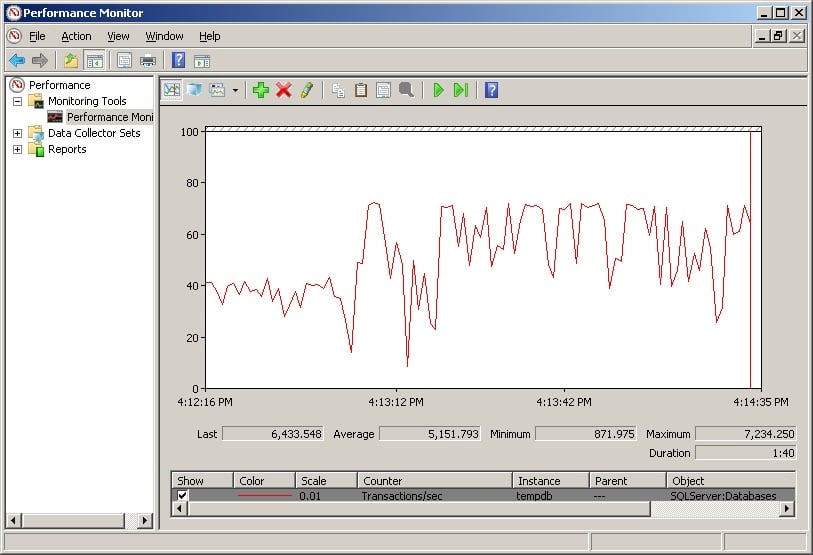
On the left was when I had a single tempdb data file and I was seeing nearly all the connections waiting for PAGELATCH_UP on 2:1:1. After adding three more tempdb data files and stabilizing, the throughput jumped, as you can clearly see.
This has just been an overview of this problem, but as I said, it’s very common. You can get more information from the links below:
53 thoughts on “The Accidental DBA (Day 27 of 30): Troubleshooting: Tempdb Contention”
“Incorrect syntax near ‘.1’.” You probably want “est.”.
Also, this query makes no effort to exclude “irrelevant” waiting types like BROKER_RECEIVE_WAITFOR that do not, of themselves, indicate any problem (if you have very many threads doing nothing, the memory needed for bookkeeping might be a concern, but I’ve personally never seen this become a problem before something else was).
“Wait statistics, or please tell me where it hurts” contains more background info on these waits (conveniently also on this very blog) for people who’d like to exclude them. That said, excluding BROKER_RECEIVE_WAITFOR is probably sufficient since the other waits are far too transient to show up in sys.dm_os_waiting_tasks under normal circumstances (so keeping them might actually be worthwhile).
Yeah – the code plugin chokes on delimited . Fixed.
Correct – I don’t ever filter anything out of sys.dm_os_waiting_tasks – only from sys.dm_os_wait_stats.
I get a syntax error – “Msg 102, Level 15, State 1, Line 15. Incorrect syntax near ‘.1’. ” when I run the script. Should line 15 be “[est].text,” instead?
Yeah – the code plugin chokes on delimited . Fixed.
Paul,
That query throws the following syntax error:
Msg 102, Level 15, State 1, Line 15
Incorrect syntax near ‘.1’.
Frank
Yeah – the code plugin chokes on delimited . Fixed.
I think 20 more people should tell you about the inadvertent error that you have already fixed. I mean, one notification isn’t enough, right? :-)
I think he cares for everybody’s comment even it’s the same on the other hand some people will just leave comment and don’t even look to this page after that ,so whenever you give a reply he’s notified by mail,which shows this blog is very lively
Just on the third action of alleviating contention and knowing when too many files have been added. By potentially adding too many files to tempdb would you expect to see an increase in pageiolatch_xx waits?
No – you’d see memory spill operations slowing down, which is very hard to gather empirical evidence for.
Thanks for the article, Paul. We are lucky not to see that much tempdb contention. :-)
Best, Frank
Paul, currently we only have one mirrored drive for tempdb. The data file and log file are the only files on this drive. I see high average write stalls on tempdb ~ 3407 ms which is much higher than the other db’s.
First question – is it OK to have both the data and log files for tempdb on the same drive?
Second – if I create additional data files for tempdb, can they all be on the same drive?
Thanks
No – with those latencies, you should have them on separate drives. And you either need faster storage for those files or you need to investigate your tempdb usage to see if it can be reduced. If you create additional data files, in your case I would not put them on the same drive (unless by drive you mead RAID array).
I have a question: What is the best practice in the storage location of tempdb DATA and LOG? Should I put them on the same drive or have them separate. And what kind of drive: RAID array or other is also good?
Thank You
Usually you have the separate, but the degree of necessity depends on how you use tempdb. And you need at least RAID-1, not RAID-0.
I have a question: What is the best practice in the storage location of tempdb DATA and LOG? Should I put them on the same drive or have them separate. And what kind of drive: RAID array or other is also good?
Thank You
It’s usual to separate the data and log for tempdb, and depending on the tempdb load, even separating them from other database files too. You want at least RAID-1, and preferably RAID-10, for tempdb as you must have redundancy. If tempdb is unavailable the instance will shut down so you want to protect against that. RAID-5 isn’t suitable.
Thanks for the useful info Paul. The query runs fine on SQL2014 but I do not get any data in my results pane. Does this mean “no contention”?
Neil
It means no contention at the time you ran it. Run it a few more times, but likely it means no contention overall.
Hello Paul, thanks for suggestions from you and Bob Ward. They are very clear. But I’m interested also in understanding the technical reasons that are behind such recommendations, the cause-effect logic. I would like to understand the mechanisms and considerations that lead to define such rules. Such suggestions are just experience of smart people from the inside of the product or there’s some mathematics/logic behind that you can explain and we can understand?
1. Why adding data files four at a time?
2. Why one file per logical core?
Thanks very much
Alessandro
1) https://www.sqlskills.com/blogs/paul/correctly-adding-data-files-tempdb/
2) https://www.sqlskills.com/blogs/paul/a-sql-server-dba-myth-a-day-1230-tempdb-should-always-have-one-data-file-per-processor-core/
Hello Paul, I’m investigating a data warehouse on SQL Server 2008 where TempDB has avg_write_stall_ms at around 1599. The storage is a SAN. There are 12 logical cores and only 4 tempdb data files right now. I’m not seeing warnings from my monitoring software about TempDB contention. Based on the illustration with Perfmon, should I expect to see the IO stalls go down if I add TempDB files? It seems throughput should go up some and thus fewer IO’s waiting to be processed.
No – because adding a bunch more tempdb files is for allocation bitmap contention, not for slow I/O.
Hi Paul,
Currently we use this metric to monitor for tempdb contention:
SELECT COUNT(*) AS cnt
FROM sys.dm_os_waiting_tasks a
WHERE a.wait_type LIKE ‘PAGELATCH_%’ AND a.resource_description LIKE ‘2:%’;
On the other hand, looking at the query at the end of this blog post http://www.sqlsoldier.com/wp/sqlserver/breakingdowntempdbcontentionpart2 – I have some questions:
– Robert/Jonathan used ‘PAGE%LATCH_%’… do we care for PAGEIOLATCH in the context of monitoring for tempd contention or should we just look for ‘PAGELATCH_%’?
– We don’t need to count (and alert on) the 4th case in the script from the mentioned blog (the “Else ‘Is Not PFS, GAM, or SGAM page'” part), is that correct? That’s not contention on allocation pages. What does PAGELATCH contention on “normal” tempdb pages indicate?
Thanks!
For allocation bitmap contention, you don’t need to look at PAGEIOLATCH. For ‘normal’ pages, it could be an insert hotspot in a user table, or sys.sysallocunits with many concurrent temp table drops/creates.
So for monitoring tempdb allocation contention, we need to exclude these non-PFS/GAM/SGAM pages, correct?
Any tips how to investigate details about LATCH contention on “normal” tempdb pages? DBCC PAGE comes to mind.
Correct.
Yes – https://www.sqlskills.com/help/waits/pagelatch_ex/
Hi Paul,
We are getting resource_description like 2:1:118 and 2:3:209701 frequently with wait type PAGELATCH_EX ,please suggest what type of page contention here (SGAM,PFS)
These are not allocation bitmaps as they are not divisable by the offsets of the allocation bitmaps. Also, allocation bitmap contention is only for PAGELATCH_UP waits.
What are the object IDs returned when you do a DBCC PAGE of those pages?
Metadata: ObjectId = 34
That table is basically sysobjects. My guess is that you are creating and dropping tables very quickly in tempdb. The solution to that contention is either not to do that, or use long table names, and potentially with very different starting portions of the name, to spread the inserts out over multiple pages in that system table.
Yes,Its a product query which dropping and creating the temp tables ,below are the statement which causing the issues,
DROP TABLE #TempDoc
CREATE TABLE #TempDoc (DFieldId INT, DfieldValue nvarchar(255))
CREATE TABLE #TempPickList (PickListId INT)
DROP TABLE #TempPickList
Please suggest what should be the name of this table in-terms of long table name.
Thank you Paul for this suggestion. Is there a way we could test and find to see where the temp tables are getting landed with random prefixes in their names vs same name?
Yes, but not easily as you’d have to connect with the Dedicated Admin Connection and query the underlying hidden system table and use %%PHYSLOC%% and fn_PhysLocFormatter. I personally wouldn’t bother going through the hassle.
Thank you Paul for the direction, that helps.
Anand – the tables should have different names for different connections, and be spread throughout the alphabet. You’ll need to experiment with the name lengths to see where the contention reduces.
Thanks a lot Paul.
Hi Paul!
This article really helped me in operational environments. Thank you!
In accordance with Microsoft Documentation:
TempDB metadata contention has historically been a bottleneck to scalability for many workloads running on SQL Server. SQL Server 2019 introduces a new feature that is part of the In-Memory Database feature family, memory-optimized tempdb metadata, which effectively removes this bottleneck and unlocks a new level of scalability for tempdb-heavy workloads. In SQL Server 2019, the system tables involved in managing temp table metadata can be moved into latch-free non-durable memory-optimized tables. SQL Server 2019 introduces a new feature that is part of the In-Memory Database feature family, memory-optimized tempdb metadata, which effectively removes this bottleneck and unlocks a new level of scalability for tempdb-heavy workloads. In SQL Server 2019, the system tables involved in managing temp table metadata can be moved into latch-free non-durable memory-optimized tables.
With SQL Server 2019, When the tempdb has a data file, is there latch contention on tempdb?
You can remove system table contention if you implement that feature, but PFS allocation contention can still be there, depending on the workload.
Thanks for this post! For our workloads, we are facing GAM page contention in tempDB, which is causing lots of issues in our production environment. I have two questions regarding that:
1. How do you get a graph like you showed above in perfmon? I think it’ll be helpful for us to get a similar graph to further drill into the issue causing area
2. Will using memory optimized tempdb tables help us in reducing GAM page contention? We are heavily using “INSERT INTO # … SELECT ..” statements for our environment
1) No – haven’t done anything with GAM contention
2) Should be a big help. They will also be solving the GAM contention issue with latch-free updates in a future release.
Hi Paul,
I do see PAGELATCH_UP contention on tempdb with resource description 2:07:03 this is pointing to Resource Type at SGAM page. And this is occurring in Microsoft SQL Server 2017 (RTM-CU20) (KB4541283) – 14.0.3294.2 Developer Edition. To resolve this should we use -T1118 trace flag ?
Please provide your suggestion on this.
Thanks,
Correct – enable that trace flag on every instance in your environment.
Ok. Thank you Paul.
Great Post!
Thank you so much!
There are too many PAGELATCH_EX on the tempdb database and resource_description is 2:1:107. (100 Session)
How I can reduce it?
My laptop has 4 logical CPU cores and tempdb database has 4 data files.
SQL Server version is 2019 (CU14) Enterprise Edition (64-bit).
I use SQLQueryStress in my test.
What’s the page? Is it from a user table or a system table? The former, change your code/keys/temp table usage. The latter, set system tables in-memory.
Thanks for your reply!
It is from a user table.
The code is:
Use StackOverFlow
Go
SELECT Id into #Tbl
FROM dbo.Users
WHERE CreationDate > ‘2018-05-01’
AND Reputation > 100
Select u.* From dbo.Users
Inner join #Tbl
On u.id = #Tbl.id
ORDER BY DisplayName;
One hundred sessions run the query simultaneously.
I sent you two images by email.
Why do all sessions use the same file?
Thanks again!
From the images you sent, it looks like the table is small enough to be in a single extent, which is why all the PAGELATCH_EX are for a small set of pages in a single file.
Thanks!
The temp table is really small, but there is a heavy concurrency. (100 Session)
I think PAGELATCH_EX wait will decrease if SQL Server uses all tempdb data files. (4 data files in my case)
Do you think so?
No – because if the table fits in a single extent it won’t ever use more than one data file. And that’s also irrelevant because those latches are nothing to do with multiple files – it’s to do with updates on those table pages and the latches would still exist if the table happened to be spread over 8 pages in four files.
Thank you Paul!
We had a very good discussion.
With the new in memory features and different management of tempdb (I have seen where there are 32 files on a 2019 instance) would you change this article? Also do you have a recommendation as to a physical setup where organizations are using SSD’s? Still terrific as usual.
Not really – as it depends what kind of contention you’re getting. I don’t think SSDs make a difference, as it’s the number of files for most kinds of contention in tempdb, not the speed of the storage.