In my previous posts on FILESTREAM I discussed the directory structure of the FILESTREAM data container and how to map the directories to database tables and columns. In this post I’m going to explain how and when the FILESTREAM garbage collection process works as that doesn’t seem to be documented anywhere (even in the FILESTREAM whitepaper I wrote for MS – it wasn’t supposed to be that low-level). There seems to be a lot of confusion about how updates of FILESTREAM data work, and when the old versions of the FILESTREAM files are removed. I’m going to explain how it all works and then show you by example.
The basic behavior that is non-intuitive is that there’s no such thing as a partial update of FILESTREAM data. If you have 10MB of data stored in a FILESTREAM column (and hence have a 10MB FILESTREAM file), then updating even a single byte of it will result in a whole new 10MB FILESTREAM file. Anything that relies on having an up-to-date version of the database (e.g. log backups, log-shipping, replication) will pick up the entire new 10MB FILESTREAM file. Every time an update is made to that data, a new 10MB FILESTREAM file is created and then subsequently backed-up, replicated, etc. This can lead to unexpectedly large log backups, or network traffic between replication nodes.
Once you realize that new versions of the FILESTREAM files are going to be created, the obvious follow-on question is: when do the old versions get removed? The answer is: it depends!
The old versions are removed by a process called garbage collection – in much the same way that memory garbage collection runs for managed code and deallocates object instantiations that are no longer referenced by any variables. The key point is that nothing needs the object instantiation any more; otherwise the memory garbage collection would be corrupting the run-time memory of the managed code application. The same principle applies for FILESTREAM garbage collection – the old versions of the FILESTREAM files cannot be removed until they are no longer needed.
But what does ‘no longer needed’ mean for FILESTREAM files? Well, it’s kind of the same as for transaction log records. An old version of a FILESTREAM file is no longer needed if the transaction that created it has committed or rolled back, AND there are no other technologies that must read it, like a log backup (when running in the FULL or BULK_LOGGED recovery models), or the transactional replication log reader. In fact, the transaction log VLF containing the log record of the creation of the FILESTREAM data file must be switched to inactive before the FILESTREAM file can be garbage collected. Note that I don’t mention database mirroring – in SQL 2008 database mirroring and FILESTREAM cannot be used together.
Once the old FILESTREAM file is no longer needed, it is available for garbage collection. How does the garbage collection process know which FILESTREAM files to physically delete? The answer is that when the file is no longer needed, an entry is made in a special table called a ‘tombstone’ table. The garbage collection process scans the tombstone tables and removes only the FILESTREAM files with an entry in the tombstone table. You can read more about the tombstone tables in this blog post from the CSS blog.
So when does the garbage collection process actually run? It can’t be part of log backups, because in the SIMPLE recovery model, you can’t take log backups. The answer is that it runs as part of the database checkpoint process. This is what causes some confusion – an old FILESTREAM file will not be removed until after it is no longer needed AND a checkpoint runs.
Now let’s see this stuff in action. I’m going to create a database with FILESTREAM data in and then play around with transactions, log backups, and checkpoints to show you garbage collection working.
CREATE DATABASE [FileStreamTestDB] ON PRIMARY
(NAME = [FileStreamTestDB_data],
FILENAME = N'C:\Metro Demos\FileStreamTestDB\FSTestDB_data.mdf'),
FILEGROUP [FileStreamFileGroup] CONTAINS FILESTREAM
(NAME = [FileStreamTestDBDocuments],
FILENAME = N'C:\Metro Demos\FileStreamTestDB\Documents')
LOG ON
(NAME = [FileStreamTestDB_log],
FILENAME = N'C:\Metro Demos\FileStreamTestDB\FSTestDB_log.ldf');
GO
USE [FileStreamTestDB];
GO
CREATE TABLE [FileStreamTest1] (
[DocId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[DocName] VARCHAR (25),
[Document] VARBINARY(MAX) FILESTREAM);
GO
Now I’m going to put the database into the FULL recovery model and take a full database backup – which means I must now take log backups to manage the size of the transaction log. It also means that a FILESTREAM file cannot be removed until it has been backed up.
ALTER DATABASE [FileStreamTestDB] SET RECOVERY FULL; GO BACKUP DATABASE [FileStreamTestDB] TO DISK = N'C:\SQLskills\FSTDB.bak'; GO
Now I’m going to create some FILESTREAM data.
INSERT INTO [FileStreamTest1] VALUES (
NEWID (),
'Paul Randal',
CAST ('SQLskills.com' AS VARBINARY(MAX)));
GO
Looking in the FILESTREAM data container I created, I have the following file:
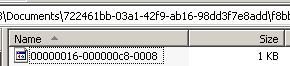
Remember from the previous blog posts, that the FILESTREAM file filenames are the database log sequence number at the time they were created. Now I’ll update the value in an implicit transaction (no BEGIN TRAN and COMMIT TRAN).
UPDATE [FileStreamTest1]
SET [Document] = CAST (REPLICATE ('Paul', 2000) AS VARBINARY(MAX))
WHERE [DocName] LIKE '%Randal%';
GO
And we now have the following files:
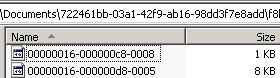
The new file is the 8KB file and the old FILESTREAM value is the 1KB file. If I try doing an explicit CHECKPOINT, nothing changes as the old file is still required as it hasn’t yet been backed up. Now I’ll do a log backup.
BACKUP LOG [FileStreamTestDB] TO DISK = 'C:\SQLskills\FSTB_log.bak'; GO
And the files are all still there. Although the first 1KB file is no longer needed, a checkpoint hasn’t occurred yet, so garbage collection hasn’t run. Now running an explicit CHECKPOINT, the directory still contains the two files. What happened? The transaction log VLF containing the log record for the creation of the FILESTREAM file is still active, so the file is still needed. I have to do *another* log backup and checkpoint before garbage collection kicks in (as that will cause the log to cycle, when there’s nothing happening in the database and no active transactions) and the directory view changes to:
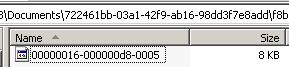
The alternative would have been to generate more log records, spilling into the next transaction log VLF, then do another log backup which would mark the ‘creation’ VLF inactive, and then the next checkpoint would run garbage collection on the file. This, of course, would be the normal course of events in a production database.
So, don’t get confused if you update a FILESTREAM file, then do a log backup and checkpoint and nothing happens. Remember the transaction log has to have progressed enough for the ‘creation’ VLF to be inactive too. You can prove this to yourself by creating an explicit transaction at the same time as the FILESTREAM update (in another, implicit transaction). No matter how many times you backup the log and checkpoint the database, the garbage collection will not run until the explicit transaction is committed or rolled back, and then another log backup and checkpoint is run.
I’ll leave it as a fun exercise for you to play around with updates in explicit transactions and various backup scenarios to see when garbage collection can and cannot remove old files, but now you know exactly how it works.
21 thoughts on “FILESTREAM garbage collection”
Regarding Garbage collection and MSSQL 2012 Availability Groups…
Can you think of a situation where you would get orphaned files in the FileStream directories? Recently we have had a common situation where we run a DBCC check against a VLDB which has a FS component and we get constant orphaned files in the Filestream directories…which require a lot of manual work to clean up…no root cause as to how these are getting in the directory structure yet.
Thanks for any input.
Corruption or a bug, basically. You could try contacting Microsoft for assistance.
We noticed a similar issue with orphaned files with InMemory optimised tables. From reading I understand InMemory tables use the same filetream feature to implement checkpoint file pairs. We are still investigating but find very little info on the subject. The log on the DB hit its MAX and from those times we see lots (181GB) of files build up in the InMemory file system location under GUID directory. I think the files should be cleaned by “checkpoint file garbage collection process” but for some reason not. Looking in the folder there are some older files assuming from other times when the background process failed. Could this be the same type of issue..?
I suspect so, but I’m not sure as I’m not an expert on the internals of in-memory tables. Again, I’d contact support for assistance.
Looks like an issue described here:
https://www.sqlhammer.com/filestream-garbage-collection-with-alwayson-availability-groups/
Great explanation. You made the understanging easy … thanks Paul .
Can you please let me know how to calculate used space for each FS column in a Database of the Total FS drive ( NTFS drive assigned for FS data ) . As of now i am using datalength function but that is not matching up used space of FS data (Varbinary) data type in a database . For example used space is 50 GB of 1 TB . But datalength of FS columns show up only 100 MB . Kindly advice.
I don’t know of any good way to do this from within SQL Server.
every time we use backup or DBCC CHECKTABLE for deleting garbage?
Garbage Collection should run automatically, but it doesn’t.
i ran below query and wait for couple hours and my garbage still exists!!
begin tran
update TableName set colName = cast (‘Alinezhad’ as varbinary(max))
commit trans
Right – because simply running that query doesn’t cause garbage collection. Did you read the blog post? It explains when garbage collection happens – either when a checkpoint or log backup occurs, neither of which you’re doing. Your data backup causes it because it does a checkpoint. DBCC CHECKTABLE causes it because it creates a database snapshot, which does a checkpoint.
Paul, with regard to “there is no such thing as a partial update”… is it also true when updating Filestream data via the Win32 API (as opposed to TSQL)? I am getting conflicting information from different sources.
No. AFAIK you can do a partial update when accessing the FILESTREAM file directly.
Hello Paul Randal,
I need your help.
I made a dbcc checkdb and pointed out error in index 2 of the filestream table tombstone I am wanting to run a dbcc checktable with repair allow data loss on this table. For prevention, I restored a backup of the corrupted database in another instance and will test there as soon as I finish. My doubt is the loss of data in this table because I believe that there is no corruption in the index nocluster. Is there a possibility of data loss?
I don’t think so, but I’ve never tried that on that table.
I understand yesterday I tried in a different instance to not affect production. More really after applying DBCC CHECK TABLE to REPAIR_ALLOW_DATA_LOSS it has presented several errors in other tables. And now little attempt to restore the page with problem and it did not work I suggested to the manager that it would be best to restore the last valid backup.
You saved me! thanks a lot Paul!
I’m trying to remove filestream from my database. I have dropped the tables that had filestream data in them and now I am trying to remove the filestream data files from the DB using DBCC SHRINKFILE(, EMPTYFILE). In properties of the database it shows the data file size as 0MB, but I cannot remove the file. I have tried a series of checkpoints, log backups, and sp_filestream_force_garbage_collection but I cannot remove that data file. The error is that it cannot be removed because it is not empty. On my file system in the folder for that data file there are a bunch of 0kb files. Any recommendations for how to remove a filestream data file?
Sounds like something else might be using the filegroup. Various discussions about how to check for stuff like that online, e.g. https://stackoverflow.com/questions/26802310/how-to-complete-remove-filestream-and-all-attached-files
Hi Paul,
you wrote: “So when does the garbage collection process actually run? It can’t be part of log backups, because in the SIMPLE recovery model, you can’t take log backups.
Based on my very detailed analysis on version 2019, garbage collection process is part of transaction log backup. In FULL recovery model, you need double transaction log backup after delete command:
1. DELETE rows:
A. Entries are inserted in system tombstone table with status 273
2. LOG BACKUP:
B. Status is changed from 273 to 274 (slowly, 20 entries every 10 seconds)
5. LOG BACKUP:
C. Physical delete of files and delete from tombstone table (20 files every 10 seconds – in the same loop as step B.)
Client deleted 120.000.000 rows from table which means that files will be deleted in 2 years (without new inserts/deletes) :)
That means FILESTREAM isn’t suitable solution if we insert more than 2 rows/sec into FILESTREAM.
I found a way to force it by detach/reattach the database. Is there a better way to do that?
That’s just forcing a checkpoint.