Last week’s survey was on what kind of backups you take, along with the recovery model used (see here for the survey). Here are the results as of 5/2/2009.
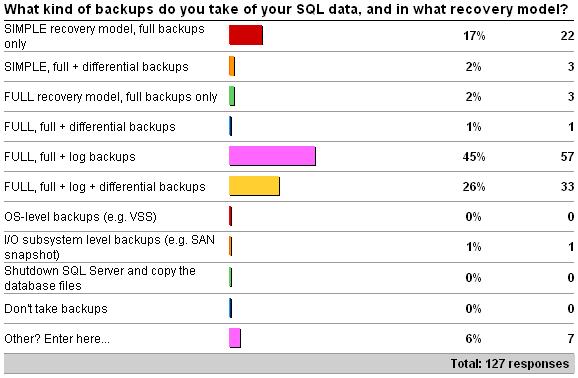
The ‘other’ responses were combinations of the other answers.
This survey is a bit of a pre-cursor to my article on Understanding SQL Server Backups that will be in the July TechNet Magazine (available start of June). In that article I explain how the three major backup types work, and then how to combine them into an effective backup strategy, so I don’t want to steal all my own thunder. In the spirit of my weekly surveys, this is a 20-minute, brain-dump editorial, rather than a very carefully planned out article.
When I’m teaching classes on Database Maintenance or High-Availability, I always tell people not to plan a backup strategy; plan a restore strategy. You don’t want to come up against a disaster recovery situation and find that the only backup you have of your multi TB 24×7 busy OLTP database is a full from several weeks ago. Kiss your job goodbye on that one. You have to make sure that you have backups that allow you to recover as quickly as possible and with the minimum of data loss.
So, you’re probably taking backups so that you can restore when disaster strikes. Some of you may also be taking backups because:
- You periodically restore the database onto a reporting server, onto a data warehouse server, or onto test/dev servers
- You’ve got log shipping implemented (backup, copy, restore; backup, copy, restore;…)
- You’ve got database mirroring implemented (and so you must use the FULL recovery model, and thus must take log backups to manage the transaction log)
- You’re in the FULL recovery model, even though you’re not interested in up-to-the-minute or point-in-time recovery, and must take backups to manage the size of the transaction log
The survey included what recovery model you’re running in too – basically SIMPLE or FULL. I don’t know anyone that runs all the time in the BULK_LOGGED recovery model; and most 24×7 systems cannot switch into BULK_LOGGED because of the possibility of crashing and not being able to take a tail-of-the-log backup, if a minimally-logged operation has occurred since the last log backup.
In the SIMPLE recovery model, you cannot take log backups – so you’re basically saying that you don’t need to be able to do up-to-the-minute recovery, point-in-time recovery, or single-page restores. That’s cool – it totally depends on your situation, and is you’re running in SIMPLE it means you understand that there’s no point running in FULL and having to take log backups if you’re not interested in using them. If you’re in the group covered by #4 above, switch to SIMPLE!
In the FULL recovery model, you have to take log backups – plain and simple – otherwise the log will grow out of control and eventually your database will grind to a halt when the log runs out of space. I’ve done a few blog posts about that so I won’t labor the point (see Search Engine Q&A #1: Running out of transaction log space, Search Engine Q&A #23: My transaction log is full – now what?, and Importance of proper transaction log size management).
In either recovery model, there’s the question of just how often should the various kinds of (I like to think of) ‘mandatory’ backups be taken, and whether to use the ‘optional’ differential backups. Again, not stealing my own thunder from TechNet Magazine: a full backup is a copy of all the data in the database; a log backup is all the transaction log generated since the last log backup (or first full/differential following a break in the log backup chain); a differential backup is all data that has changed since the last *full* backup.
You need to take regular full backups – but just how regular depends. If the database is very large, and you need to keep your backups around for regulatory purposes, you might choose to take a full backup every couple of weeks or a month, with compression. Commonly I see people taking a full backup once a week.
Almost 20% of respondents are in SIMPLE and only take full backups – I wonder how many realize that a full backup only gives you a single point-in-time to which you can recover – and you lose all work since the last full backup. In the SIMPLE recovery model, you can’t take log backups, so if you want to reduce the amount of data loss when a disaster occurs, you’ll need to take differentials too, which only a handful of respondents do. Although this still means you’ll have some data loss, it’s vastly reduced. The amount of potential data loss will be the amount of work since your last (e.g. daily) differential backup, rather than since your last (e.g. weekly) full backup.
In the FULL recovery model, only a few % of respondents are NOT taking log backups – which means they shouldn’t be in the FULL recovery model, or are being forced to (e.g. from using mirroring) and don’t realize that having a redundant copy of the database isn’t a good enough HA strategy – you have to have backups too in case of a secondary failure.
The vast majority of respondents use the FULL recovery model taking full and log backups (45% – which is what I expected) and about 25% are also taking differentials too. This is a more advanced strategy and can seriously REDUCE your downtime in the event of a disaster. A differential backup basically short-circuits the need to restore all the log backups that were taken in the time between the last full backup and that differential backup. You’ll find out more on this in the article. For the ultimate in flexibility and fast recovery, this is the way to go – but at the cost of a little more complicated backup strategy, and extra storage space for the differential backups.
Now, what about the exotic answers at the end of the survey?
- OS-level backups: this isn’t a popular solution *at all* because of the complexity of getting the SQL data back out from the OS-level backup and recovered. I’m not surprised that no-one selected this.
- SAN-level backups: I’ve seen a few customers do this, with mixed results. You must make sure that the SAN admin knows what they’re doing – I heard of one customer who had data and log files on different LUNs. The SAN admin snapped the data LUN, and *then* the log LUN. Every so often, corruption would occur…
- Shutdown SQL and copy the files: Just don’t even think about this. Taking downtime to take a backup is daft, and what if the database is corrupt and won’t re-attach?
- Don’t take backups: No need to discuss this one.
Ok – that’s a quick blast that should give you some idea of why you’d want to make sure you’ve got the *right* backups, not just any old backup strategy.
Next post – this week’s survey!
(PS I’m really enjoying being on Twitter – lots on interesting stuff. See me at http://twitter.com/PaulRandal)
6 thoughts on “Importance of having the right backups”
Hi Paul,
I just voted while reading my backlog of blog posts, but I was too late, apparently. Count one extra vote in the "SIMPLE, full + differential" category.
However, I must say that I sometimes consider moving to "SIMPLE, full only" instead. I chose to do weekly full and daily simple to allow for daily backups without the disk space hit, but if I check the file sizes, I am quite disappointed. My full backups are around 100 kB. And while the diff backups are SOMETIMES smaller (around 20 kB – still quite a lot if you consider that there were almost no changes in the DB in that time), they will often be a lot larger, up to 40 kB or sometimes even 80 kB. Makes me wonder if the limited amount of disk space saved is worth the extra hassle in case a restore ever is necessary…
Best, Hugo
Hi Paul,
I am sick of creating the same SQL Maintenance Plans on every new implementation. Is there a way to script the Maintenance plans and just update a few things each time?
Why not create a script that programmatically creates all the maintenance jobs and job-steps for you? Then you can tweak a few things in it for each new instance you install.
Hi Paul
We briefly crossed paths last week on serverfault.com, and I didn’t put two and two together (until I came across this page) that you’re *that* Paul :-)
Right, with the flattery out the way, I’m interested in your "short-circuit" approach on differential backups. My experience has been mainly with MIS environments (simple recovery, full daily backups, and some log shipping for reporting DBs), hence the lack of sufficient working experience in this area, though I have done my required reading.
In addition to your Technet Magazine article, BOL and so forth, can you suggest other resources I can read up on? I would appreciate it and so would my customers.
One in particular (I arrived there on Monday) has resorted to simple recovery mode because of performance problems, and I know this is not going to help them. Their existing "backup" strategy is "Shutdown SQL and copy the files". I cried into my coffee when I heard this yesterday, and fatefully came across this page last night.
Thanks! Not just for getting back to me if you do, but for helping me out with your website in the past.
Hi Randolph,
Apart from the resources you’ve listed, I don’t know of any specific books that treat the subject in any more depth except one – SQL Server Backup and Recovery: Tools and Techniques by Frank McBath. It’s based on 7.0 and 2000 and I helped Frank tech review back in 2001. I’m sure all the regular DBA books cover it, but not sure how deeply. The TechNet Magazine article comes out this week sometime – watch the blog and I’ll announce it.
Thanks
Thanks, Paul. In the meantime, I’ve been reading your articles in older issues. Very interesting stuff.