In last week’s survey I asked whether you’re ever tested your disaster recovery plan, and if so, what happened? (See here for the survey). Here are the results as of 5/25/09:
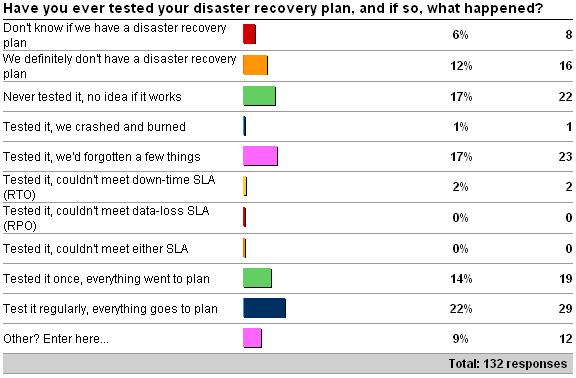
The ‘other’ responses are:
-
2 x “restored to test env regularly. don’t know if sla would be met.”
-
2 x “test it regularly, most goes according to plan”
-
2 x “Test it regularly, people screw up. Was a great win when I obtained the budget for this activity.”
-
2 x “test it regulary and learn new things every time but overall it works”
-
2 x “we have annual drp test company-wide”
-
1 x “We have lots of DR plans, some tested, some not.”
-
1 x “We test the dr failover with mirror.however chain replications (subscriber becomes pulisher)we can’t”
A good mixture of results, but only around 25% of respondents test it regularly. Rather depressingly, 35% of respondents either don’t have a DR plan or have one but have never tested it. Given the stories I see almost every day on the various forums, this doesn’t surprise me – but it’s still depressing nevertheless.
The term ‘disaster recovery’ means different things to different people. The word ‘disaster’ in my mind spans everything that could go wrong and affect whether your system and data is online, available, and performing to spec. The word ‘recovery’ means any process that allows you to bring your system and data back online, available, and performing to spec. Your disaster recovery plan could be as simple as restoring from the last full database backup, or as complicated as failing over all processing to a remote data center and engaging a 3rd-party company to distribute new DNS routing entries across the Internet. It, of course, depends (I have to work that into every editorial :-). Lots of people interchange DR and high-availability (HA), but HA is really a set of technologies that you implement to help protect against disasters causing problems. For instance, you might implement database mirroring so that part of the DR plan for a database is to failover to the mirror, keeping the database highly-available, while DR happens on the old principal. Or you might implement auto-grow on the transaction log file so that if it runs out of space the database doesn’t become unusable. Neither of these are doing DR, they’re preventing a disaster from affecting availability. DR in the second case would be what you do to provision more space for the log so the database can come online again.
Now, this editorial’s not going to be about putting together your disaster recovery plan – that’s an entire book in itself, as there are many techniques depending on the disaster and the resources you have available to facilitate recovery. If you don’t have a disaster recovery plan (which I’m going to start calling DR plan), then you should *know* that come disaster time, you’re risking whoever’s on duty floundering around making mistakes and potentially leading to more downtime and data-loss than if you had a plan to follow. People panic in times of high-stress and crisis, and without a set of steps to follow, bad things happen. Enough said. You know who you are – go get a DR plan before a disaster happens and you lose time, data, your job, or all of the above. I see them all happen regularly.
Once you have a DR plan in place, the ONLY way to know whether you’re going to be able to recover from a variety of disasters is to simulate some, in production. Yes, this is far easier said than done – persuading your business owners to take planned downtime (and possibly lose a bit of revenue) can be a hard argument to make, but unless you do, you can’t know that your DR plan will work. One argument I’ve found effective is wouldn’t you rather have all the various admins and DBAs on-site and expecting the test and things to potentially go wrong, than wait until a real disaster occurs in the middle of the night and THEN find out that the DR plan doesn’t work and everyone has to scramble when they’re least expecting it? Of course, business owners often aren’t interested in low-probability potential problems. DR and HA aren’t sexy topics UNTIL the company experiences a disaster. Then it’s likely to be the top thing on the CEO’s mind and you have to have a DR plan in production by Tuesday.
Seriously though, if you’re responsible for your system meeting certain SLAs (downtime and data loss – a.k.a. RTO and RPO) then your DR plan actually has to work, no matter how carefully you’ve designed it. This means you have to try restoring from your backups and seeing if you can do it within your downtime SLA. What about if you have to setup a new server first? What about if there’s no power in your building? What if your off-site backups are 200 miles off-site and the network link is down? What if none of your backups work? What if your differential backups are bad, do you still have all the log backups? How does that affect your recovery time? And so on and so on. You might think I’m just making stuff up and these things don’t happen, but they do, and everything I’m citing as an example has happened to a customer I’ve personally been involved with while at Microsoft or since then. And they keep happening over and over again to different people.
If I had to list the most common reasons I see why disaster recovery fails, they are:
- There are no backups, meaning recovery = data loss
- Backups don’t work or all contain the corruption, meaning recovery = data loss
- The data volume has increased since last DR test, meaning recovery time exceeds downtime SLA
- The initial failover when the disaster happens doesn’t work because the failover site only has part of the application ecosystem, meaning recovery involves getting the application working on the failover site AND then recovering from the disaster on the main site
Doing an initial test when the DR plan is first produced is great, because at least you know that it works, or there are some things you’ve missed (which is almost invariably the case). The DR (and HA plans) should be written by the most experienced DBAs, as they’re the ones who’ve “seen it all” and have a good idea of what could go wrong at any point during the recovery. And the plans should be tested by the most junior DBAs, as you can bet that if a disaster occurs at 2am on Thanksgiving morning, it won’t be the most senior DBA who’s on duty.
Doing a regular test is critical because things change. Data volume increases. Databases get added into the mix. Personnel change. SLAs change. And after a change, if you don’t test regularly, then you won’t know if your DR plan still works until you have a real disaster. If you can push for a DR plan test and everything works, everyone has increased peace of mind. If you can push for a DR plan test and things go south, you’ll be praised for having exposed the problems. But if you wait, and things go south, no-one likes being responsible for unnecessary downtime or data loss – and that doesn’t look good on a resume.
Next post – this week’s survey!
3 thoughts on “Importance of testing your disaster recovery plan”
I’ve been preaching this for years when I consult, speak, and write, but people still think I’m nuts when I tell them to test D/R (and even HA). I’ve seen it for the past 10+ years like you – it’s the same stuff over and over again. I think I’ve only been involved with and heard of a few successful disaster scenarios.
I also know everyone hates documentation and it’s hard to write (I know it probably better than anyone considering I’m wrapping up the new book now), but it has to be done when it comes to D/R plans. They need to be updated when things change in the environment. They are not write once, and forget about it.
The best thing anyone in IT can do is quantify how much downtime will cost, and show that testing D/R is much cheaper than hours or possibly days of downtime. Becoming more plugged into the business is so important these days.
I also amazed when I find out that orgs don’t test their DR/BCP plans.
My mantra: It ain’t a backup unless you’ve tested it from production – backup – recovery – production.
I’m also amazed by the number of systems that I work with that have ZERO backup processes in place. Zero.
No backups at all? yikes.
I’ve posted this before… a co-worker used to say it was a "Restore Plan, not a Backup Plan" If you never try and restore the data, you might as well be sending it to the bit bucket.
We just finished testing a whole datacenter failure to an alternate site in the next state. It is a lot of work to both Design and document such a system. But it does cost less in the long run.
Our customer’s even have DR plans that include "use paper" in case of a major failure… like CA falling into the ocean. What do you do if the DC falls into a hole and the power is going to be out for a week? Can your employee’s even make it into the office?