About a month ago I kicked off a survey asking what you look for when first analyzing a plan for a poorly performing query. You can see the original survey here.
Here are the survey results:
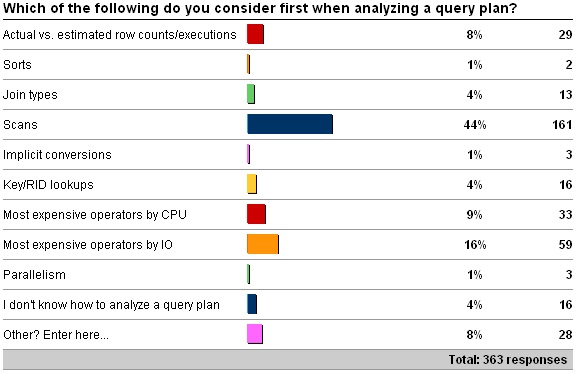
The "Other" values are as follows:
-
13 x "Most expensive as percentage of total cost of batch"
-
7 x "It depends on what I am trying to fix/improve"
-
4 x "Fat arrows"
-
3 x "Operator cost"
First of all – what would my answer be? I tend to look for scans and the most expensive operators, plus big fat arrows that stand out.
There's a clear winner here in opinion amongst my readers – by far the most common first consideration when analyzing a query plan is to look for scans – I'm not surprised by that.
In this editorial I'm not going to write about how to go about analyzing query plans – there's so much to cover that I'd end up writing a book-length blog post. Instead I'd like to point you at a bunch of resources that will help you with query tuning, including a few books.
I use SQL Sentry's fabulous free Plan Explorer tool to do this as I can switch back/forth between showing costs by CPU, by IO or combined. I can also see cumulative costs for a branch of the query plan, rather than having to look through a bunch of operators for expensive ones – this is invaluable to me day-to-day when working on client systems. It has a host of other features that SSMS does not have and I know lots of people who use it – why wouldn't you?
If you've never look at a query plan before, I strongly recommend Grant Fritchey's free e-book Dissecting SQL Server Execution Plans. I'd also recommend Grant's regular book SQL Server 2008 Performance Tuning Distilled.
As far as the choices I gave in the survey, each of them can be a major problem but aren't necessarily a problem at all. It's like the misconception that if you have wait stats, then you must have a performance problem. See my long blog post on wait stats for more info.
Here is some specific info that will help you understand the ramifications of each problem in a plan that I listed in the survey:
-
Different row counts or executions between the estimated and actual plans usually indicates that either statistics are out of date leading to a bad plan, or maybe a plan was cached for a stored proc based on atypical parameters. Checkout the following links:
-
Conor vs. Misbehaving Parameterized Queries + OPTIMIZE FOR hints (Conor Cunningham)
-
Estimated rows, actual rows and execution count (Gail Shaw)
-
Sorts can sometimes be caused by unneeded ORDER BY statement or by missing nonclustered indexes. A good, quick overview of sorts is in Showplan Operator of the Week – SORT (Fabiano Amorim)
-
Joins are very often misunderstood and there are a whole host of reasons why one join may be chosen over another. Best thing to do here is point you at Craig Freedman's excellent series that I link to here.
-
There are all kinds of reasons why scans appear in query plans, not all bad at all. One of the bad reasons is that there are insufficient nonclustered indexes which mean the table has to be scanned to retrieve the data – see the books and search on Google/Bing for an enormous amount written about this. Another reason is T-SQL code written so that an index *cannot* be used because an expression does not isolate the table column correctly, forcing a scan. I blogged about this here.
-
Yet another reason why scans occurs is code written/schema designed so that an operation called an implicit conversion occurs, where the table column must be converted to a different data type before a comparison can take place – forcing a scan, as each value has to be converted to the comparison type. Jonathan blogged about this here.
-
Key/RID lookups are where the query plan uses a nonclustered index to find a value, but the nonclustered index is not covering, so the other result set columns must be retrieved from the table row. When a Key Lookup occurs, the retrieval is from a clustered index and when a RID Lookup occurs the retrieval is from a heap. Both of these are undesirable because of the extra processing required. The fix for this is simply to ensure the correct indexes exist to support the queries, and that the queries are pulling in the correct columns – many times I've seen client code that pulls in columns that aren't necessary.
-
The most expensive operators in a plan are usually a good place to look to see where gains can be made by changing code, statistics, or indexing. I blogged a short post on using SET STATISTICS to watch IO and CPU costs here.
- Parallelism is again often misunderstood and not necessarily a bad thing. For a large report query in a data warehouse, parallelism is good. For frequent queries in a busy OLTP system, parallelism can be a problem. The best presentation I've seen by far on parallelism is by Craig Freedman – check it out here.
And that's what I have for you on query plans – lots of information for you to go exploring and learning. Analyzing a query plan is a skill that all DBAs and Developers should have IMHO and all the information is out there for you to try it out on your systems.
Enjoy!
One thought on “Query plan analysis first steps”
Great survey, Paul! One thing that really surprises me here is the extremely low number of folks that look for lookups first. This is almost always the first thing I look for, for a few reasons:
– They can cause a big CPU hit… especially if stats are off and SQL ends up doing more of them than expected, vs tipping to a scan.
– They are far and away the single biggest cause of deadlocks I’ve seen.
– They can be easier to "correct" than wider scans since there’s often an existing n/c index available, it just needs an included column or two to cover new columns added to a query.
IMO it’s best to start by quickly eliminating any lookups that you can, then move on to scans.