Well, I had a second post already planned and partially written but a comment on the first post (in what’s going to become a multi-part series) has made me decide to do a different part 2 post. So, make sure you read this post first: Locking, isolation, and read consistency.
The comment was about how read committed using locking has inconsistencies – and, yes, that’s true. Read committed using locking is prone to multiple inconsistencies; there are things you can do to reduce some anomalies but in a highly volatile OLTP environment you will get inconsistencies for long running readers. This is why having a secondary server for analysis is always a great idea. Then, everyone gets the same version of the truth – the point in time to which the secondary was updated (is that nightly, weekly, monthly?). Now, if the secondary is getting updates through transactional replication, you are back to the same problem. But, here, I cannot imagine NOT using read committed with versioning. Probably one of the BEST places to use versioning is on a replication subscriber. Replication won’t be blocked by readers and readers won’t be blocked by replication:
Check It Out!

Why is read committed with versioning preferred for readers?
More and more, we’re being tasked with analyzing “current” data. This is harder and harder to do without introducing anomalies. So, I’ll discuss non-repeatable reads in the bounds of a single statement. To get this to occur with a small data set and without setting up a bunch of connections, etc. I’ll engineer the anomaly.
Example
To do this, I’m going to use a sample database called Credit. You can download a copy of it from here. Restore the 2008 database if you’re working with 2008, 2008R2, 2012, or 2014. Only restore the 2000 database if you’re working with 2000 or 2005 (but, you can’t do versioning on 2000 so this is a 2005 or higher example).
Also, if you’re working with SQL Server 2014, you’ll potentially want to change your compatibility mode to allow for the new cardinality estimation model. However, I often recommend staying with the old CE until you’ve done some testing. To read a bit more on that, check out the section titled: Cardinality Estimator Options for SQL Server 2014 in this blog post.
So, to setup for this example – we need to:
(1) Restore the Credit sample database
(2) Leave the compatibility mode at the level restored (this will use the legacy CE). Consider testing with the new CE but for this example, the behavior (and all examples / locking, etc.) don’t actually change.
Scenario / example
(3) This is where things will get a bit more interesting – you’ll need a couple of windows to create the scenario…
FIRST WINDOW – setup the table:
USE [Credit];
GO
IF OBJECTPROPERTY(object_id('[dbo].[MembersOrdered]'), 'IsUserTable') = 1
DROP TABLE [dbo].[MembersOrdered];
GO
-- Create a copy of the Member table to mess with!
SELECT *
INTO [dbo].[MembersOrdered]
FROM [dbo].[Member];
GO
-- Create a bad clustered index that's prone to both fragmentation and
-- record relocation. This is part of what makes this scenario more likely!
-- But, that's not the main point of discussion HERE. This is good
-- because it's also easy to visualize
CREATE CLUSTERED INDEX [MembersOrderedLastname]
ON [dbo].[MembersOrdered]
([lastname], [firstname], [middleinitial]);
GO
SELECT COUNT(*) FROM [dbo].[MembersOrdered];
GO
Now… we’ll engineer the problem. But, I’ll describe it visually here:
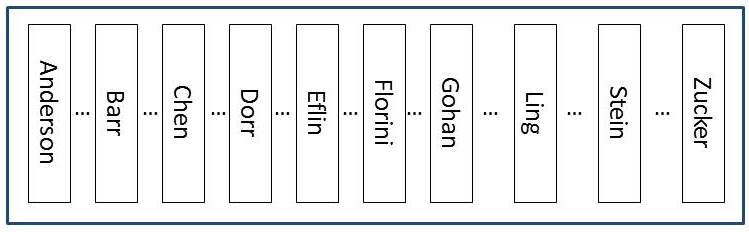
The table has NO nonclustered indexes and ONLY a clustered index on lastname. The data is essentially ordered by lastname (not going to get technical about what the data looks like on the page here or the fact that it’s really the slot array that maintains order not the actual rows… for this example – the logical structure of the table is good enough to get the point).
(4) So, now that the table has been created – we will start by creating a problem (a row that will end up blocking us):
SECOND WINDOW – we’ll create a blocking transaction (t1)…
USE [Credit];
GO
BEGIN TRANSACTION
UPDATE [dbo].[MembersOrdered]
SET [lastname] = 'test',
[firstname] = 'test'
WHERE [member_no] = 9965;
Don’t get me wrong – this is a horribly bad practice (to have interaction in the midst of a transaction and to only send part of the transaction… if you walk away – SQL Server is incredibly patient and will hold locks until the transaction is finished [or, killed by an administrator]). But, the point… now our table will essentially look like this:
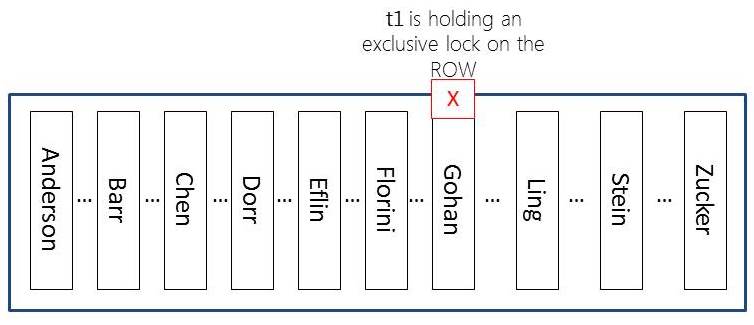
And, yes, there are MORE locks than just what I show here. SQL Server will also hold an IX lock on the page where this row resides and an IX lock on the table as well. And, of course, SQL Server will also hold a shared lock on the database. All of these locks (IX and the database-level S lock) are used as indicators. Individually, they don’t really block all that many other operations. You can have MANY IX locks on the same page at the same time and you can have many IX locks on the same table at the same time. Essentially these locks are used to show that someone has the “intent” to exclusively lock resources on this resource.
If you’re interested, check out sys.dm_tran_locks to see the locks held at each point of this example…
(5) So, now that the table has a locked row, we will try again to get a row count. Go back to the FIRST WINDOW and JUST re-run the query to get a count:
SELECT COUNT(*) FROM [dbo].[MembersOrdered]; GO
This will be blocked. And, it will sit blocked until the transaction finishes (either through a commit or rollback OR by being killed – none of which we’ll do…yet ).
So, what’s interesting and we need a bit of back-story to fill in is that our count query reads ONLY committed rows (we know that – it’s read committed locking). What a lot of people don’t know is that the row-level shared locks are released as soon as the resource has been read. This is to reduce blocking and because there’s no need (in read committed ) to preserve the state of the row (like repeatable reads does). And, I’ll prove that with an update…
(6) Now we’ll update a row that’s just sitting there and not locked (but, may have already been counted [locked, read, and then the lock was released] by our count query).
THIRD WINDOW – update and move a row that was already counted
USE [Credit]; GO UPDATE [dbo].[MembersOrdered] SET [lastname] = 'ZZZuckerman', [firstname] = 'ZZZachary' WHERE [lastname] = 'ANDERSON' AND [firstname] = 'AMTLVWQBYOEMHD'; GO
OK, now here’s another horribly bad practice (not using a key for a modification). But, this table has all sorts of problems (which is what makes it a wonder example for this). And, if I don’t go with something that’s efficiently indexed for this update then the locking would be different. I NEED to get row-level locking here. So, I have to do the update above. And, now what’s happened:
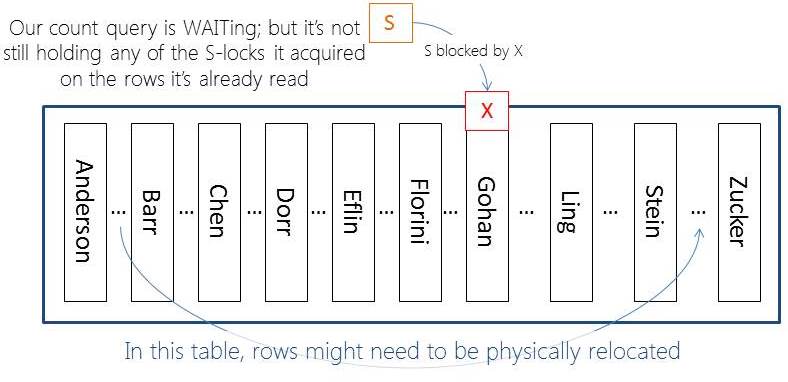
(7) Now, it’s time to “complete” the transaction that was blocking our count query.
Go back to the SECOND WINDOW and complete the transaction (to be honest, you can COMMIT or ROLLBACK – it really won’t matter for this example):
ROLLBACK TRANSACTION;
(8) Step 7 will have unblocked the row count query so all you need to do is go back to the first window and check the count that’s sitting there… which will be 10001 rows in our table that only has 10000 rows. Why? Because you were NOT guaranteed repeatable reads even in the bounds of a single statement.
Re-run the count query and you’ll get 10000 again.
Why read committed with versioning solves this problem?
When you change the database to read_commmitted_snapshot you change ALL read committed statements to use version-based reads. The best part is that we’ll never WAIT for in-flight rows nor will we see rows whose transactions completed within the bounds of your statement [the longer running the statements the more that this is possible]. The incorrect count would not occur for a few reasons but I’ll create a list of the reasons here:
When the row modification (t1) is made – the row will be versioned (SQL uses “copy on write” / “point in time” = snapshot) to take the BEFORE modification VERSION of the row and put it into the version store.
When the count begins it will just quickly continue (and not be blocked by the X lock held on the ‘Gohan’ row). This is not a problem, the columns are changing but the row is not being deleted – yes, we should count that row.
If I could switch to the window and run the update fast enough, it too would not be blocked by the version-based read NOR would the moved row be visible (even if it made it there in time) by the version-based read because it’s new location (handled as an INSERT) would be NEWER than our count statement’s START time. Our count will reconcile to the point in time when the statement BEGAN. Nothing is blocked and those changes (even when committed before we get there) are NOT visible to our version-based read.
Is Summary
Yes, read committed with versioning is often MUCH preferred over read committed using locking. But, versioning does come at an expense. You do need to do monitoring and analysis of THE version store (in THE tempdb). Someday (SQL Server 2016???) maybe we’ll multiple tempdbs (that would be awesome) and ideally, we’ll have some nice capabilities for controlling / limiting version store overhead (of one database over another). But, for right now – you have to make sure that your tempdb is optimized! And, if you have an optimized tempdb and you don’t have a lot of really poorly written long-running queries, then you might find out that the overhead is less than you expected. This is absolutely something that you should be not only considering but using!
Whitepaper: Working with tempdb in SQL Server 2005
Plus, be sure to review Paul’s tempdb category for other tips / tricks, etc.
OK, so now the originally planned part 2 is now trending to be part 3. Depending on questions – I’ll get to that in the next few days!
Thanks for reading,
k
8 thoughts on “Inconsistent analysis in read committed using locking”
Excellent write up, this is something I have been meaning to learn more about and your article has given me a first step on the ladder. Thank you.
Thanks! It’s a great topic to know more about – really helps in troubleshooting issues / problems. More on this one is coming! ;-)
Cheers,
k
Hi Kimberly,
Sorry for my newbie question but if the only resource waiting to be read was the one with the row lock, why did sql server read the row updated again afterwards? ( the record was physically moved but the only thing missing for sql server to finish the select statements was not the row lock ? )
Thanks
Hey there Tiago – Transaction 1 was modifying the row (which is why it was locked) and then the count query waited at that resource AFTER it had read the Anderson row. THEN, transaction 2 updated the Anderson row and moved it. Because of the record relocation it was placed back in the path of the count query (once the lock from transaction 1 was released). It’s because of the access methods chosen. And, the ANSI / ISO standards are that you are NOT protected from non-repeatable reads in “read committed.” In my example, I “engineered” the scenario by using one transaction (t1) to block. And then another transaction to relocate a row that I was certain my count query had read.
Definitely let me know if this doesn’t clear things up!
k
“Yes, SQL Server 2016 looks like it will have multiple tempdbs (yeah)”? Even as an MVP and after watching all of the Ignite sessions with the updates on the 2016 release, I seem I have missed something? Why are you guessing that we are going to be having multiple tempdbs per instance?
Hey there Boris – Actually, now I don’t even remember where I heard this but someone at Ignite (maybe twitter?) last week mentioned that they had heard that it would. But, now I can’t find anything on the data sheet, etc. that mentions it. So… maybe not? I’ll update the post to reflect that it’s unknown. Bummer! I was pretty excited when I heard that but now I don’t remember where. It was definitely around Ignite though (and I was surprised).
Thanks,
k