In Nov 2014, SQLskills made an offer to user group leaders to deliver remote user group sessions in 2015 and we’ve been having great fun delivering them. So far the team has delivered 34 sessions and we have 72 signed up! At my last session (for the San Diego SQL Server User Group), I delivered a session on stored procedures. It was great fun and I had a few questions at the end that made me come up with some new sample code… that’s where this post is coming from!
The question was because I said to make note of something being a parameter and not a variable (during the lecture) and so the question was – what’s the difference and how does that change the behavior?
Definitions
Parameters are values that are being passed into a stored procedure. Since these are part of the call to execute the procedure; these are “known” during compilation / optimization (but, that’s only IF SQL Server has to compile / optimize, more on that in a minute)
Check It Out!

Variables are assigned at runtime and therefore are “unknown” during compilation / optimization.
Literals are known at all times as they are exactly that – a simple / straightforward value
Review this heavily commented stored procedure:
CREATE PROCEDURE ParamVarLit
(@p1 varchar(15)) — defining the parameter name @p1 AND the data type
AS
— Declarations / assignments
DECLARE @v1 varchar(15); — defining the variable name @v1 AND the data type
SELECT @v1 = @p1; — assigning the variable to the parameter input value
DECLARE @v2 varchar(15); — defining the variable name @v2 AND the data type
SELECT @v2 = ‘Tripp’; — assigning the variable to a literal value
— Note: also acceptible is this format
— DECLARE @v2 varchar(15) = ‘Tripp’
— Statement 1 (using a parameter)
SELECT [m].*
FROM [dbo].[member] AS [m]
WHERE [m].[lastname] = @p1
— Statement 2 (using a variable)
SELECT [m].*
FROM [dbo].[member] AS [m]
WHERE [m].[lastname] = @v1; — or @v2, these will work EXACTLY the same way!
— Statement 3 (using a literal)
SELECT [m].*
FROM [dbo].[member] AS [m]
WHERE [m].[lastname] = ‘Tripp’;
GO
In the stored procedure you can see that there’s one input parameter, we’ll assign that when we call the stored procedure.
We can assign parameters by name (line two) or we can assign them by position (note, when you have a lot of parameters this can be frustrating)
EXEC [dbo].[ParamVarLit] @p1 = ‘Tripp’ — assignment by name
EXEC [dbo].[ParamVarLit] ‘Tripp’ — assignment by position
Outside of that, everything else is being defined / assigned within the stored procedure.
Setup
Now, we have to see how each of them works from an optimization perspective. To do this, I’m going to use a sample database called Credit. You can download a copy of it from here. Restore the 2008 database if you’re working with 2008, 2008R2, 2012, or 2014. Only restore the 2000 database if you’re working with 2000 or 2005.
Also, if you’re working with SQL Server 2014, you’ll potentially want to change your compatibility mode to allow for the new cardinality estimation model. However, I often recommend staying with the old CE until you’ve done some testing. To read a bit more on that, check out the section titled: Cardinality Estimator Options for SQL Server 2014 in this blog post.
So, to setup for this demo – we need to:
(1) Restore the Credit sample database
(2) Leave the compatibility mode at the level restored (this will use the legacy CE). Consider testing with the new CE but for this example, the behavior (and all estimates) don’t actually change.
(3) Update a row and add an index – use this code:
USE Credit;
GO
UPDATE [dbo].[member]
SET [lastname] = ‘Tripp’
WHERE [member_no] = 1234;
GO
CREATE INDEX [MemberLastName] ON [dbo].[member] ([Lastname]);
GO
Execution
To execute this procedure it’s simple – just use one of the execution methods above and make sure that you turn on “Show Actual Execution Plan” from the Query, drop-down menu.
EXEC [dbo].[ParamVarLit] @p1 = ‘Tripp’ — assignment by name
GO
This is what you’ll see when you execute:

Notice that the first statement and the third statement both use an index to look up the row but statement two does not. Why? It’s all tied to whether or not the value was “known” at the time of optimization. And, most importantly – this procedure was the executed when there wasn’t already a plan in cache. Because there wasn’t already a plan in cache, SQL Server was able to optimize this procedure for the parameters passed in at THIS execution. This does NOT happen for subsequent executions.
More specifically, when the statement KNOWS that the value is ‘Tripp’ (statement 1 knows because it’s getting optmized for ‘Tripp’ and statement 3 knows because the value is hard-coded for ‘Tripp’) then SQL Server can look to the statistics to determine how much data is going to be processed. In this case, SQL Server estimates that there are very few rows with a last name of ‘Tripp’ (from the statistics, it thinks there’s only 1). As a result, an index would be helpful to find this highly selective result so it chose a plan to use an index.
For statement 2 though, SQL Server doesn’t seem to know to use an index. Why? Because here the variable (@v1) was unknown at the time of compilation / optimization. The variable is not assigned until actual execution but execution only occurs after a plan has been generated. So, the problem with variables is that SQL Server doesn’t know their actual values until after it’s chosen a plan. This can be both good and bad. Remember, SQL Server has to do something… So, in this case, SQL Server uses an average to estimate the rows and come up with a plan. This average comes from the density_vector component of a statistic rather than this histogram. If your data is reasonably evenly distributed then this can be good. And, it also means that the plan won’t change change after it’s kicked out of cache and a different execution occurs with different parameters. Some have learned this trick and have used it with success – but, only because their data is either evenly distributed OR the executions are using values that all resemble the average.
NOTE: This is EXACTLY the same behavior as using the OPTION (OPTIMIZE FOR UNKNOWN) clause on the statement within the stored procedure.
In this case, however, ‘Tripp’ is NOT like the average value and so the plan for statement 2 is not ideal for a variable assigned to ‘Tripp’. The data has a lot of duplicates and the average number of rows for most names is quite high (where an index is no longer userful). However, ‘Tripp’ is really not an average data value here and so the plan might be good for most other values. But, in this case, it’s not good for the value Tripp.
Execute the procedure again but supply a different value for @p1:
EXEC [dbo].[ParamVarLit] @p1 = ‘Anderson’ — assignment by name
GO
This is what you’ll see when you execute with ‘Anderson’ AFTER having created a plan for ‘Tripp’:
Wait – there’s no difference?
Nope, absolutely none! Really, review every aspect of your output /plan [not the actual values] and you’ll see it’s exactly the same! The plan that you see is always the estimated plan and the estimated plan is chosen when the stored procedure is optimized / compiled. Optimization / compilation occurs only when there isn’t already a plan in cache for that procedure.
Why are they the same?
The parameter – ‘Tripp’ was used on the first execution and this is what was “sniffed” and use for optimization. When I say “sniffed” all that means is that the value was KNOWN such that the optimizer could look at the statistics (and specifically the histogram) to estimate how many rows had a last name of ‘Tripp.’ It turns out that the estimate was 1. You can see this by hovering over the Index Seek in the first statement:
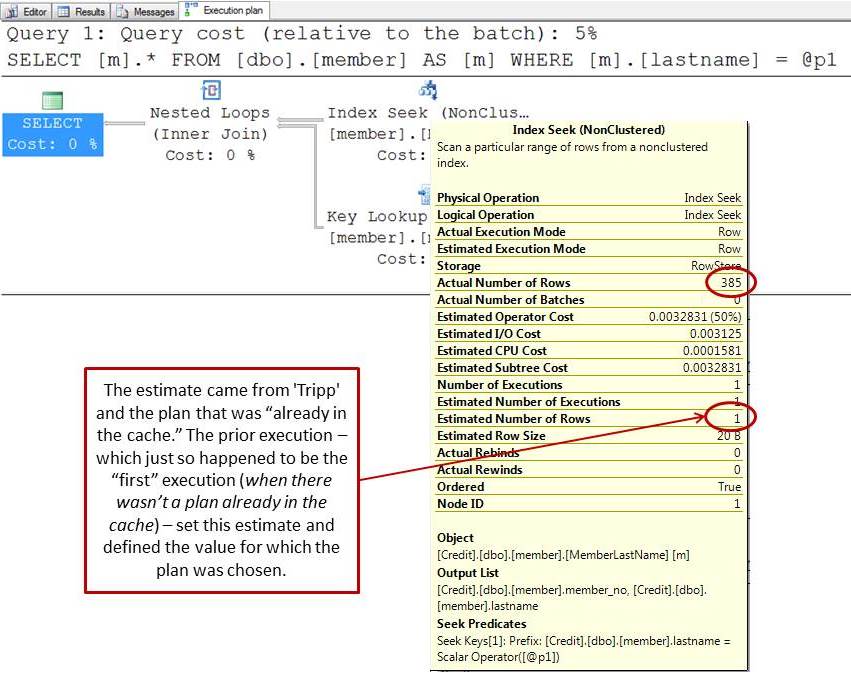
If you were to kick this plan out of cache and re-execute with ‘Anderson’ then something interesting would happen:
EXEC [sp_recompile] ‘[dbo].[ParamVarLit]’;
GO
EXEC [dbo].[ParamVarLit] @p1 = ‘Anderson’;
GO
Results in this plan:

There’s really one incredibly important observation here: ONLY the first statement’s plan changed!
The first statement’s plan changed because on this execution SQL Server was able to “sniff” the parameter and optimize / compile a plan specific to it. More specifically, when the statement KNOWS that the value is ‘Anderson’ (again, only statement 1 knows this) then SQL Server can look to the statistics to determine how much data is going to be processed. In this case, SQL Server estimates that there are numerous rows with a last name of ‘Anderson’ (from the statistics, estimates 385 rows). As a result, the data is not selective enough to warrant using an index so in this case, SQL Server uses a table scan. (shown as a clustered index scan solely because the table has a clustered index)
Bringing It All Together
Parameters are evaluated and sniffed ONLY when a plan is being created. This ONLY happens when a plan is NOT already in the cache. And, sniffing is fantastic for THAT specific execution because “sniffing” a parameter lets SQL Server use the histogram component of statistic to determine the estimate. While the histogram is not always perfect, it’s usually a more accurate way of estimating rows. But, this can also lead to parameter sniffing problems where subsequent executions don’t perform well because the plan in cache wasn’t optimized for their values. There are many solutions to this problem, I covered a few of the options here: Building High Performance Stored Procedures.
Variables are ALWAYS deemed “unknown” and they cannot be sniffed. In this case, SQL Server doesn’t have a value to lookup in a statistic’s histogram. Instead, SQL Server uses an average to estimate the rows and come up with a plan. But. as I mentioned – this can be sometimes good and sometimes bad.
The literal is the easiest of them all. SQL Server knows this value and there’s absolutely nothing that will ever change that value. This can be sniffed and it will use the histogram getting the best estimate to use for optimization.
Play around with this sample procedure. Review the plans and the estimates v. actuals. Next week I’ll dive more into the statistics themselves and where the specific estimates are coming from!
Have fun and thanks for reading!
k
24 thoughts on “Stored Procedure Execution with Parameters, Variables, and Literals”
Hi,
I’m a little confused. After re compilation the cost relative to batch for statement one has increased from 5% to 49%. So compared to the rest of the batch which has not changed it is more expensive. Yet this sproc has been compiled for ‘Anderson’. So why is it more expensive to query ‘Anderson’ when it has been compiled for ‘Anderson’? I can understand that if you compile for ‘Anderson’ and query ‘Tripp’ it may be more expensive but it does not make sense to me this way round.
Hey there Steve – Ah, good question! I didn’t get into the statistics side of things but when a plan is compiled the estimates drive the plan and the cost of the operators is driven by the type of plan and chosen operators. In the case where two scans are being done, the cost is known and goes up accordingly. What’s funny though is that the cost of executing the ‘Tripp’ plan with the ‘Anderson’ value would make the execution of statement 1 a lot more costly (in terms of IO) but because the plan was estimated on Tripp (only 1 row) the *estimated* cost is still the same.
Does that make sense? It’s frustrating but I can summarize it also by saying that the actual plan is really just the estimated plan with actual numbers (shown through the yellow tool tips). What you see in the plan shape and percentages though is COMPLETELY driven by the plan (which was completed during optimization / compilation). So, the showplan doesn’t change an EXISTING when different parameters are passed (even if the actual costs are a lot higher).
Let me know if you have more questions on this!
k
Hi Kimberly,
Thanks for a great article. I think that I was getting hung up on comparing the three queries but that’s not a fair comparison. The first two queries are querying on Anderson where as the third query is querying on Tripp. It is obvious to me know that this is not fair as we know that the data density differs between Q3 and the other queries. I would have expected Q1 and Q2 to show a different estimated cost but I guess that because a scan if performed the cost would be the same, luck of the draw.
Thanks a lot for the article and the response to my question
Hey there Steve – Ah, but the estimate for Anderson is *very* close to the average – and, the plans end up being the same too. So, in the case of s1 and s2 where the parameter is Anderson, their costs end up being the same.
Again, good comments / questions!
Cheers,
k
Great read. Thanks
Thanks Orson!! (had fun on your facebook post ;-)
I have a much better grasp of parameter versus variable after reading your blog, but I’m not sure I understand when it is better to set a variable equal to the input parameter. (Q2 in your example) I once had a stored proc that took 2 input parameters, start date and end date. It ran fine in SSMS but once I compiled it and pushed it to SSRS, it crawled. A co-worker suggested parameter sniffing might be the problem, so I created two variables at the top of the sproc and set them to the input parameters and then used the variables in my WHERE statements. It definitely sped up the stored procedure, but I’m not sure I understand why. If I had just re-compiled it, would that have fixed the issue? I am struggling to understand what it would be “averaging” to decide on a plan. And what does it do when there are multiple variables? Does it look at them sequentially?
Hey there Leigh Anne – This is a great question. However, it’s a bit more difficult to answer in a short reply but I’ll try to do a summary (I do hope to do a statistics-related post next week and that might help more). Simply put, if you want more consistent plans for relatively evenly distributed data (or, when the large majority of the values supplied are close to the average) and you don’t want an atypical value defining the plan. That’s where using telling SQL Server to avoid sniffing and using the average value (average overall the data) might be better.
Even in this example that could have (and really would have) been a better decision. The sample data in credit looks like this:
385 Andersons
385 Barrs
385 Chens
385 Dorrs
…
with 1 Tripp. Tripp is really the anomaly within this data. Letting a plan go into cache for this anomaly means that almost everyone else suffers because Tripp is selective. When Tripp is used to define the plan, SQL Server chooses to use an index. However, ALL of the other values (Anderson, Barr, Chen, Dorr, etc.) have 384-385 rows – which is NOT selective enough to warrant using an index. A better plan for EVERY ACTUAL value would be to do a table scan. Now, it does get a bit more difficult for values that don’t exist because sniffing would use the histogram and the histogram has a better chance of knowing that the values aren’t there or that there are very few [but, that’s definitely NOT the case in larger and larger sets]. But, here, the only queries that would suffer would be those that request a name that does not exist or Tripp. So, if the common queries are those that supply Anderson / Barr / Chen / Dorr, etc. and rarely supply a name that does not exist then letting SQL Server use the average would be a better choice and it would not allow a plan to be put in the cache that would work well for the majority of executions.
I do hope that helps!
k
“Parameters are values that are being passed into a stored procedure.””
Nope. A parameter is the formal marker in a procedure declaration. It has a data type (the usual) and an invocation type. The invocation can be for input, for output, for either. in SQL/PSM we have explicit IN, OUT and INOUT in the procedure header. It gets worse! If your language supposes thunks, which are modules of code such as expressions, like “Foo(x+1)”, or function calls, like “Foo(sin(x))” or worse. This stuff goes back to Algol-60.
The actual value passed and used by body of the procedure is an argument. This is based on a flashback to to my ANSI X3H2 days and a discussion at a meeting decades ago. ghod! How did I get to be so old? I was always pedantic :)
Ha Joe – How awesome that you’re here! And, yes, you’re ever-so-right (and pedantic as usual – a wonderful trait). I guess I was going for the short-version in order to compare / contrast it with variables and literals. But, I do appreciate that you’re keeping me honest!
Thanks Joe!
k
The comment above was an argument passed to the blog engine.
LOL… definitely not! I don’t argue with Joe on anything related to definitions or ANSI syntax; he’ll get me every time! Where I do argue is tuning for an application and denormalizing… but, ut oh, let’s not start that in comments on a blog!! ;-) ;-)
k
Great article, thanks for the insight Kimberly. It is these type of insights that helps me write better code. Lot of times things are taken for granted with respect to queries and SP’s development. It is these type of experimentation that really helps me understand about how sql server generates a plan , I need to have my developer friends read this article.
Thank you
You’re welcome Ramdas. Thanks for reading!!
k
Kimberly, I noticed that you initialize your local variables using the following syntax:
SELECT @v1 = @p1;Is there a difference, either performance-wise or functional-wise between that method and using the “SET” statement as follows?
SET @v1 = @p1;Hey there Stewart – SELECT is the old school way (which is definitely me), SET is the newer way (I just never got used to it to be honest – no difference here), and DECLARE @v1 int = 4 is even newer. If any were to have a very tiny, tiny, tiny gain I would think it would be combining the declaration with the assignment. But, even then, if there is a gain, I’ve never heard anyone talk about it in a way that’s made me move over to using it exclusively so… I think the most important thing is to be consistent. Probably the fastest / cleanest is the declaration and assignment together.
Hope that helps!
k
Great post! Thanks Kimberly!
Thanks Rob!!
Would it be best to use variables or parameters that have a default value and are never explicitly assigned?
Hey there Eunice – If they have a default value and are never explicitly assigned then I’d move that into the statement as a literal? Or, with the calculation on one side of the expression (as opposed to pulling it out and into a variable). But, maybe I need more information here? Simply put, if the expression is outside of the statement itself then the value is unknown. If the value could be calculated once and known then it’s likely to give better results. But, it really depends on the result set that’s tied to the calculation… more information might help me answer this but I’d always go with a literal (where I could) and with the expression IN the statement (where possible) IF I want to use the histogram. But, if I want a generic / average plan then using a variable [or, using OPTION (OPTIMIZE FOR UNKNOWN)] would work.
Hope that helps!
k
Great post! Thanks Kimberly!
Great post!
Thanks Kimberly