Last week’s survey was on how you should store large-value character data in SQL 2005+ (see here for the survey). Here are the result as of 4/3/2009 – and I think my favorite answer is starting to catch-on:
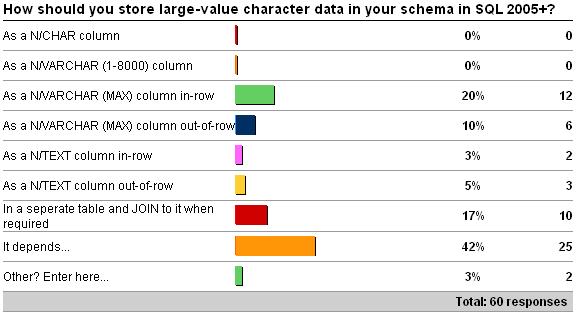
My favorite answer is, of course, it depends! For all those who didn’t answer ‘it depends’, your answer is valid, but only for particular circumstances, as each method has its pros and cons and won’t be applicable in all cases. It’s extremely important when designing a schema to consider how to store LOB data, as making the wrong choice can lead to nasty performance issues (where ‘performance’ is a catch-all to include things like slow queries, fragmentation, and wasted space). Now I’d like to run through each of the options and detail what I think of as the pros and cons. A couple of definitions first: ‘in-row’ means the column value is stored in the data or index record with the other columns; ‘out-of-row’ or ‘off-row’ means the column value is stored in a text page somewhere in the data file(s), with a physical pointer stored in the data/index record (taking either 16 or 24 bytes itself).
- As a N/CHAR column. This is a great choice when the data that’s stored in the column is a fixed size all the time, and always uses the full width of the column. Any time that the data may be smaller than the defined width of the column, space is being wasted in the row. Wasted space leads to fewer rows per page, more disk space being used to store the data, more I/Os to read the data, and more memory used in the buffer pool. However, if the character values are very volatile, and can change size, then having a fixed-width column can avoid the problem of a row having to expand and there not being enough space on the page to allow that – leading to a fragmentation-causing page split in an index (or forwarding record in a heap). There’s a tipping point that can be hard to identify for your particular application…
- As a N/VARCHAR (1-8000) column. For data values less than 8,000 bytes, this is the common choice as it avoids wasted space. However, if the application can change the size of the data after the initial creation of the row, then there is the possibility of fragmentation occurring through page-splits. A row can also be created that is more than 8,060 bytes – one or more variable-length columns is pushed into off-row storage and replaced by a physical pointer. This means any access of the column has to do an extra I/O to reach the data – and this is commonly a physical I/O as the text page is not already in memory. This can lead to hard-to-diagnose performance issues if a query selects the column and some rows have the data in-row, and some out-of-row. Also, if the data values tend towards the larger end of the 1-8,000 byte spectrum, individual rows can become vary large, leading to very few rows per page – and the problems described in the first option. If the data isn’t used very much, then storing it in-row like this isn’t very efficient.
- As a N/VARCHAR (MAX) column in-row. This has the same pros and cons as the option above, with the added benefit that the value can grow larger than 8,000 bytes. In that case it will be pushed off-row automatically, and start incurring the extra I/O for each access. These data types also work with the intrinsic functions in the same way as the character data types discussed above. I guess one drawback of this type compared to FILESTREAM is that it’s limited to 2GB. Also, if there’s a LOB data column in the table definition, the table’s clustered index cannot have online operations performed on it – even if all the LOB values are NULL or stored in-row!
- As a N/VARCHAR (MAX) column out-of-row. The drawback of storing this data out-of-row is that accessing it requires an extra I/O to retrieve it, but if the data isn’t used very much then this is an efficient way to go, but still uses space in-row to store the off-row pointer. An additional benefit of storing the data off-row is that it can be placed in a separate filegroup, possibly on less expensive storage (e.g. RAID 5) – but then there’s the drawback that it can’t be moved after being created except with an export/import operation. This option has the same online operations drawback as storing the data in-row.
- As a N/TEXT column in-row. This has the same pros and cons as the N/VARCHAR (MAX) column in-row option, but these data types are deprecated and don’t work with the majority of the intrinsic functions.
- As a N/TEXT column out-of-row. Same as above.
- In a separate table and join to it when required. This option is great when the data isn’t used very much, as it doesn’t require any storage at all in the main table (except for a value to use for the join), but it does require some extra up-front design and slightly more complicated queries. There’s another HUGE benefit to doing this – by moving the LOB data to another table, online operations become available on the main table’s clustered index. (This concept is ‘vertical partitioning’ a huge topic in itself…)
- As a FILESTREAM column. (Yes, I didn’t have this in the survey, but it’s a possibility). If your data values are going to be more than 1MB, then you may want to consider using the FILESTREAM data type to allow much faster access to the data than having to read it through the buffer pool before giving it to the client. There are lots of pros and cons to using FILESTREAM – see my whitepaper for more info here.
So, as you can see, the best answer for a general question like this is definitely It Depends!. Although I haven’t covered every facet of each storage option, the aim of this post is to show that it is very important to consider the implications of the method you choose, as it could lead to performance problems down the line.
Next post – this week’s survey!
4 thoughts on “Importance of choosing the right LOB storage technique”
Hi Paul
What is about VARBINARY(MAX) datatype to store LOB data (pictures for instance)
Hi Paul
You mean that you would not use VARBINARY(MAX) to store pictures, so what else?
Absolutely Uri – but I limited things to large-value character data – and I wouldn’t use VARBINARY(MAX) for that. Thanks!
No – I mean I wouldn’t use it to store large-value character data. It’s fine for unstructured LOB data like images, but that’s a whole other discussion about the best way to store them.