In last week's survey I asked what you think is the most important thing when it comes to performance tuning, if you *had* to choose one – see here for the survey. Here are the results as of 6/7/09.
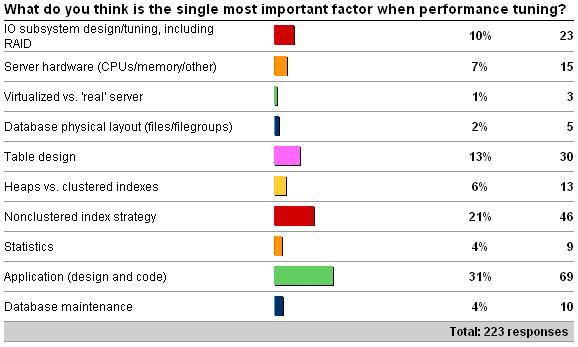
Now of course you're all calling 'foul' because I didn't put an 'it depends' option on there which you all would have chosen, but that would have been boring, and I wanted you to pick what you really think is the #1 thing in the majority of cases. Of course, in general the answer is always 'it depends', but some things turn out to be the #1 problem more often than others. For the record, mine and Kimberly's answers were overall indexing strategy, but I deliberately broke them out into clustered and nonclustered to see what people would pick. I'm not surprised that application issues and nonclustered indexing strategy came out top, but good to see that all answers were represented and there's a variety of opinion out there. Variety is the spice of life as they say, or is it garlic? Depends who's cooking I suppose – but I digress.
Check It Out!

Let's walk through each option and see how badly they can affect performance if something's wrong. This is by no means an exhaustive list of what could cause problems, just me rambling on at the end of a Sunday, as usual. Blog posts are so much easier than articles because you can have run-on sentences, short little fragments and all sorts of other verboten grammatical beasts.
IO subsystem design/tuning, including RAID: Quite a few things here could be wrong. Is there a write-intensive workload (either data files or log files) sitting on a RAID-5 array (with RAID-5 there's a performance penalty on writes)? Is the disk partitioning alignment, RAID stripe size, or NTFS allocation unit size incorrectly set? (See Are your disk partition offsets, RAID stripe sizes, and NTFS allocation units set correctly? for details.) Is the I/O subsystem just not up to the load being placed on it – high disk queue lengths, page IO latch wait errors, long-running IO errors? Is tempdb the bottle-neck because there a multiple procs with multiple users all trying to create/drop lots of temp tables? (See Misconceptions around TF 1118 for details.) Are there multiple databases using the same I/O subsystem such that disk-head contention is causing performance issues? Is there a network bottleneck with iSCSI storage? Are there filter drivers getting in the way and slowing things down?
Server hardware (CPUs/memory/other): Ok – I'm going to sound like a stuck-record saying 'quite a few things here could be wrong'. Let's just take it as read that each category has lots that could go wrong. A heavy load with a single CPU isn't going to perform well. However, sometimes excessive parallelization can lead to the dreaded CX Packet waits – multiple threads in the query processor waiting for information from each other because the server is overloaded – or blocking issues as locks start getting in the way – but that's more an application problem – oops, wrong section. Having more CPUs is usually a good thing as parallel plans usually run faster than single-threaded plans. Having too little memory can severely limit the buffer pool size and force buffer pool thrashing (low page life expectancies), and large operations to spool data to tempdb, placing further load on resources. Not sure what I meant now by 'other' – maybe having a wireless keyboard could slow down commands getting to SQL Server? Ok – I remember – CPU architecture. 64-bit vs. 32-bit. With 64-bit there's no real limit on the amount of memory that can be addressed, and no mucking around with AWE. There are some tricky issues with NUMA to make sure you don't get cross-node memory accesses (just like CPU cache invalidation could hit you on SMP architectures) but that's getting a little advanced and geeky. Btw – watch out for this when you're using Extended Events in SQL 2008 on multi-proc boxes – there's a setting where you can tell it what kind of CPU architecture you have.
Virtualized vs. 'real' server: Now, I'm the first to admit that I'm not an expert in virtualization, but now I have 3 8-ways and lots of disks to play with at home, I want to be. That's why I picked up a Hyper-V book today after reading Tom's virtual bookshelf post here. What I do know is what I've heard from talking to people at conferences and during classes – the main thing here is I/O virtualization. If there's software virtualization of I/Os, then performance is going to suck under load and you better not do it in production. Microsoft's Hyper-V gets around this, as do things like VMware ESX, by allowing you to assign actual real physical resources to virtual machines. And that's as much as I know about it until the book arrives and I get back from Houston to read it. And no doubt I'll be posting more about it.
Database physical layout (files/filegroups): Tempdb is the obvious case, and I've covered that above. User databases are a bit trickier, and it really depends on the underlying I/O subsystem. A single monolithic data file on a single physical disk isn't going to perform well under heavy concurrent load. But it may do fine on a RAID-10 array sliced-and-diced in a clever way by an expensive SAN. In today's world, more and more databases are on SANs so user database performance is taken care of in that respect, and all you need to worry about is tempdb. I touched on this a little bit in the editorial of a previous survey Physical database layout vs. database size.
Table design: Both ends of the spectrum work well here – from the plastic Costco tables with the fold-down metal legs to antique French-oak farmhouse tables. Both will give many years of service with no degradation of performance. Just like regular tables, SQL Server tables come in all shapes and sizes and you can easily pick the wrong one for what you need, leading to poor performance. This is a massive can of worms – in fact Kimberly spends 2 brain-busting days on this in one class she teaches and she could easily spend a week of 10-hour days on it (oh yes, it's called the SQL Masters program :-) From picking the right column types (see Michelle's post at Performance Considerations of Data Types) to deciding how to store you LOB values (see my post at Importance of choosing the right LOB storage technique) to deciding on a good primary key. Just don't pick a random GUID, or if you have one, replace it. Clustered index keys should be unique, narrow, static and ever increasing. Table design encompasses so many things I can't do it justice in a late evening paragraph. But you get the idea.
Heaps vs. clustered indexes: Kimberly likes to wrap this up with nonclustered indexes too, but I wanted to break them out so I could reference a whitepaper that strongly suggests you should use clustered indexes: Comparing Tables Organized with Clustered Indexes versus Heaps. Read it yourself and draw your own conclusions. Basically, with the possibility of forwarding records in heaps, and the majority of a clustered index's upper levels being in memory, the extra random physical I/Os to access a record in a heap outweigh the aggregated cost of the in-memory binary-searches at each level of clustered index tree navigation. I'm sure some people will argue about this – bring it on. There are very special cases where heaps are better, but not in general.
Nonclustered index strategy: Biggie #1. Where to start here and what to say? For the majority of scenarios, if you don't have a good nonclustered indexing strategy you're not going to have good performance. There's a simple reason for this – without the right nonclustered indexes to allow the query optimizer to choose them, you're going to get table scans. Of your 124 billion row table. How fast is that going to be? Again, Kimberly has this class that she teaches on this where she goes into details on how to index for ORs, for ANDs, for JOINs, and all sorts of other kinky stuff. I need to sit and listen to her one day so I can appear knowledgeable about this. I just know that you need to have indexes with the right selectivity. Ok – I just called Kimberly downstairs in the office to make sure I'm right before I blog something and look like an idiot and she starts with 'erm, well it depends'. I give up. I do *corruption* and *HA* and *maintenance*, not performance tuning. It's bloody hard. Luckily I'm married to one of the best people on the planet for SQL index tuning – wow, what hope do you have? (Of index tuning, not of marrying Kimberly :-) Seriously, index tuning isn't that bad – I just had a moment of weakness. You need to make sure you have the right indexes and no completely unused indexes otherwise you're wasting resources maintaining them. You could do worse than listen to her on RunAs Radio Interview Posted – "Kim Tripp Indexes Everything".
Statistics: If the statistics are out-of-date, the optimizer will not be able to pick a good plan and your performance will suck. It's that simple. Turn on AUTO_UPDATE_STATISTICS and make statistics updating is part of your regular maintenance. Don't forget to update non-index statistics too.
Application (design and code): Biggie #2. Sometimes no amount of cleverness can wring good performance from the twisted logic of a deranged application programmer. An application that is written with absolutely no concern for how SQL Server works is likely to not perform well. An application that is written with too much knowledge of how SQL Server works is likely to fall foul of relying on 'accidental' behaviors, or behaviors that are limited to certain data volumes or workloads. An application that is going to make heavy use of SQL server has to take into account how SQL Server is going to behave under a variety of workloads, on a variety of servers, and on a variety of I/O subsystems. The common application test framework? A ten-row customer table with a single connection. 'Excellent – my 16-table join with CLR-based aggregations runs in less than 2 seconds'. For 10 rows. Six months later: 'Now we've got 3 million customers, why does performance suck so bad?' Go figure.
Database maintenance: Ok – starting to get tired now and I still need to do this week's survey. Maybe I could just say 'do maintenance' and be done with it? No? Ok – how about go checkout the article I wrote last August for TechNet Magazine: Effective Database Maintenance article. If you don't maintain your indexes, they'll likely get fragmented and affect performance in one way or another and you'll need to play with FILLFACTOR (see Kimberly's Database Maintenance Best Practices Part II – Setting FILLFACTOR). If you don't take care of transaction log VLF fragmentation, it will affect log-based operations (Kimberly again at Transaction Log VLFs – too many or too few?). Seriously – she says I blog so much – how many links are in this post to her stuff? She blogs a lot too!. If you have corruption, it could manifest itself as long-running I/Os. If I don't put my food on to cook, then I'll be eating way too late again. That was a 'Paul maintenance' one that slipped in – and can have disastrous effects on blogging performance. Seriously, you can't just put a database into production and walk away. It will slowly degrade over time. Like red jello melting on a hot summer's day, but probably not as fast, unless you use random GUID primary keys, or it's really hot. What?!?
Performance tuning is an art and a science. But there's a huge amount of science behind it before you have to get into the art side of things. I've just scratched the surface here in a blog post that took me more than an hour to write, banging away non-stop as I do. And I don't do the art side of things. I leave that to Kimberly – she just got one of our client's batch jobs from a 72-hour run-time down to a 6.5 hour run-time. They were pretty happy. We can't all be the Goddess of Performance Tuning
Next post – this week's survey!
4 thoughts on “Important considerations when performance tuning”
I actually had indexing considerations as my third choice for the following reasons. If your underlying I/O subsytem stinks indexing will offer only limited benefits and may, in fact, become part of the problem due to poor write performance. The disk controllers have finite physical limits with regard to I/O’s per second. I can have the best index strategy in the world but if it’s all on a single file on one hard drive it’s not going to help that much. The primary performance problem that I encounter in my consulting engagements are systems that are I/O bound. The other benefit of a sound I/O subsystem is that it offers flexibility with regard to file/filegrouping.
That being said, attacking the indexing strategy is a great way to get an easy win or two and I will often start an engagement there; however, hear are my top four most "important" considerations in order.
1. I/O subsystem
2. File/Filegrouping (one logically follows the other)
3. Heaps vs clustered indexes
4. Non-clustered indexes
You’ll note that I didn’t mention application design. It’s been my experience that messing with the design isn’t usually an option from a performance tuning point of view. Re-working the apps is a very expensive proposition and requires extensive regression testing etc so my clients will rarely even talk about it. It also tends to annoy the developers. A very real political consideration.
Hmmm…regarding the nonclustered option, I’m dealing with that issue now in fact. We have a database in which information from a third party application that monitors everything about every system uploads and prunes data to the tables in the database it uses. NONE of the indexes are clustered, but there are plenty of non-clustered ones. Maintenance on this drives me crazy as it takes days for the summarization of the data from one table to another to occur (detailed -> hourly -> daily -> etc.) I’ve finally decided to take the approach of creating a clustered index on each table on a writetime column that all the tables share, and rebuild those indexes regularly. Sometimes, you’re stuck with non-clustered indexes. :-(